原作者: モハメド・バイオウミ アレックス・チーマ
オリジナル編集: BeWater

レポート全体は長くなるため、2 つの部分に分割して公開します。前回の記事では、AI x 暗号のコアフレームワーク、具体例、ビルダーの機会などを紹介しました。次の記事では、主に機械学習の動作モードと課題について説明します。翻訳の全文をご覧になりたい場合は、ここをクリックしてくださいリンク。
A. 機械学習はどのように機能しますか?
人工知能 (AI) と暗号通貨の交差点を詳しく掘り下げる前に、まず人工知能の分野単独でいくつかの概念を紹介することが重要です。このレポートは暗号通貨分野の読者を対象に書かれているため、すべての読者が人工知能と機械学習の概念を深く理解しているわけではありません。読者が人工知能と暗号通貨が交わるどのアイデアに本当に興味があるのかを評価し、プロジェクトの技術的リスクを正確に評価できるようにするためには、概念を理解することが重要です。このセクションでは、人工知能の概念に焦点を当てますが、さらに、人工知能と暗号通貨の関係にも焦点を当てます。

このセクションで取り上げるトピックの概要:
機械学習 (ML) は、明示的にプログラムされずに機械がデータに基づいて意思決定を行うことができる人工知能の分野です。
ML プロセスは、データ、トレーニング、推論の 3 つのステップに分かれています。
モデルのトレーニングは計算コストが非常に高くなりますが、推論は比較的安価です。
学習には、教師あり学習、教師なし学習、強化学習の 3 つの主な種類があります。
教師あり学習とは、(教師が提供する)例から学習することを指します。教師はモデルに犬の写真を見せて、これは犬だと伝えることができます。これにより、モデルは犬と他の動物を区別する方法を学習できるようになります。
ただし、LLM (GPT-4 や LLaMa など) などの多くの一般的なモデルは、教師なし学習によってトレーニングされます。この学習モードでは、インストラクターはガイダンスや例を提供しません。代わりに、モデルはデータ内のパターンを発見することを学習します。
強化学習 (試行錯誤学習) は、主にロボット制御やゲーム (チェスや囲碁など) などの継続的な意思決定タスクで使用されます。
人工知能と機械学習
1956 年、当時最も聡明な人々がセミナーのために集まりました。彼らの目標は、知能の一般原則を提案することでした。彼らは次のように指摘した。
"学習のあらゆる側面やその他の知能の特性は非常に正確に記述できるため、それをシミュレートするマシンを構築できます。"
人工知能開発の初期の頃、研究者たちは楽観主義に満ちていました。ある意味、彼らの目標は汎用人工知能 (AGI) であり、これは野心的です。現在では、これらの研究者が一般的な知能を備えた AI エージェントを作成できなかったことがわかっています。 1970 年代と 1980 年代の人工知能の研究者にも同じことが当てはまりました。その期間中、人工知能の研究者たちは開発を試みました。"知識ベースのシステム"。
知識ベースのシステムの重要なアイデアは、マシンに対して非常に正確なルールを記述できるということです。基本的に、私たちは専門家から非常に具体的で正確なドメイン知識を抽出し、それをマシンが使用できるルールの形で書き留めます。マシンはこれらのルールを使用して推論し、正しい決定を下すことができます。たとえば、マグナス・カールソンからチェスの原則をすべて抽出して、チェスをプレイするための人工知能を構築することを試みることができます。
しかし、これを行うことは非常に困難であり、たとえ可能であっても、これらのルールを作成するには多くの手作業が必要です。想像してみてください。犬を識別するためのルールをどのように機械に書き込むのでしょうか?機械はどのようにしてピクセルを持ち、犬が何であるかを知るようになるのでしょうか?
人工知能の最新の進歩は、と呼ばれるグループによってもたらされています。"機械学習"支店。このモデルでは、マシン用の正確なルールを記述する代わりに、データを使用し、マシンにそこから学習させます。 GPT-4、iPhone の FaceID、ゲーム ボット、Gmail スパム フィルター、医療診断モデル、自動運転車など、機械学習を使用した最新の AI ツールはどこにでもあります。
機械学習パイプライン
機械学習パイプラインは 3 つの主要なステップに分割できます。データを使用してモデルをトレーニングする必要があります。その後、モデルを使用できるようになります。モデルを使用することを推論と呼びます。したがって、3 つのステップはデータ、トレーニング、推論です。
大まかに言うと、データ ステップには、関連するデータの検索とその前処理が含まれます。たとえば、犬を分類するモデルを構築したい場合、モデルが何が犬で何が犬ではないかを認識できるように、犬や他の動物の写真を検索する必要があります。次に、モデルが正しく学習できるように、データを処理し、データが正しい形式であることを確認する必要があります。たとえば、画像のサイズが一定であることが必要な場合があります。
2 番目のステップはトレーニングです。ここでは、データを使用してモデルがどのように見えるべきかを学習します。モデル内の式は何ですか?ニューラル ネットワークの重みは何ですか?パラメータとは何ですか?どういう計算が行われているのでしょうか?モデルが良好であれば、そのパフォーマンスをテストしてから使用できます。これで 3 番目のステップに進みます。
3 番目のステップは推論と呼ばれ、ニューラル ネットワークを使用します。たとえば、ニューラル ネットワークに入力を与えて、「推論を通じて出力を生成できますか?」と質問します。
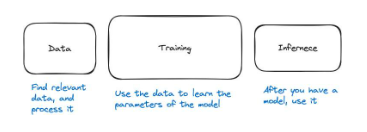
図 28: 機械学習パイプラインの 3 つの主なステップは、データ、トレーニング、推論です。
データ
それでは、各ステップを詳しく見てみましょう。まずはデータ。大まかに言えば、これはデータを収集して前処理する必要があることを意味します。
例を見てみましょう。皮膚科医(皮膚疾患の治療を専門とする医師)が使用できるモデルを構築したい場合。まず多くの顔のデータを収集する必要があります。次に、専門の皮膚科医に皮膚疾患が存在するかどうかを評価してもらいます。今、多くの課題が生じるかもしれません。まず、すべてのデータに顔が含まれている場合、モデルが体の他の部分の皮膚の状態を特定するのは困難になります。第二に、データに偏りがある可能性があります。たとえば、データのほとんどは、1 つの肌の色調または色調の写真である可能性があります。第三に、皮膚科医は間違いを犯す可能性があり、つまり、間違ったデータが得られることになります。第 4 に、当社が取得するデータはプライバシーを侵害する可能性があります。

第 2 章では、より深いデータの課題について説明します。ただし、これにより、適切なデータを収集して前処理することが非常に困難であることがわかるはずです。

図 29: 2 つの一般的なデータセットの概略図。 MNIST には手書きの数字が含まれていますが、ImageNet にはさまざまなカテゴリの注釈付き画像が数百万件含まれています
機械学習の研究には有名なデータセットがたくさんあります。一般的に使用されるものには次のものがあります。
MNIST データセット
説明: グレースケール画像形式の 70,000 個の手書き数字 (0 ~ 9) が含まれています
使用例: 主にコンピュータ ビジョンにおける手書き数字認識技術に使用されます。教育現場でよく使われる初心者向けのデータセットです。
ImageNet
説明: 20,000 以上のカテゴリでラベル付けされた 1,400 万以上の画像を含む大規模なデータベース。
使用例: 物体検出および画像分類アルゴリズムのトレーニングとベンチマーク。毎年恒例の ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) は、コンピューター ビジョンとディープ ラーニング テクノロジの開発を促進する重要なイベントとして常に開催されています。
IMDbのコメント:
説明: IMDb からの 50,000 件の映画レビューが含まれており、トレーニングとテストの 2 つのグループに分かれています。各グループには、同数の肯定的なコメントと否定的なコメントが含まれています。
ユースケース: 自然言語処理 (NLP) の感情分析タスクで広く使用されています。テキストで表現された感情 (肯定的/否定的) を理解して分類できるモデルの開発に役立ちます。
大規模で高品質のデータセットへのアクセスは、優れたモデルをトレーニングするために非常に重要です。ただし、これは、特に小規模な組織や個人の検索者にとっては困難な場合があります。データは非常に貴重であるため、競争上の優位性をもたらすため、大規模な組織はデータを共有しないことがよくあります。

電車
パイプラインの 2 番目のステップは、モデルをトレーニングすることです。では、モデルをトレーニングするとは具体的には何を意味するのでしょうか?まず、例を見てみましょう。通常、機械学習モデル (トレーニング完了後) には 2 つのファイルしかありません。たとえば、LLaMa 2 (GPT-4 に似た大規模な言語モデル) には 2 つのファイルがあります。
パラメータ、数値を含む 140 GB のファイル。
run.c と単純なファイル (約 500 行のコード)。
最初のファイルには LLaMa 2 モデルのすべてのパラメーターが含まれており、run.c には (モデルを使用した) 推論の実行方法に関する指示が含まれています。これらのモデルはニューラル ネットワークです。
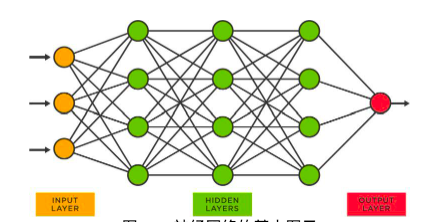
図 30: ニューラル ネットワークの基本図
上記のようなニューラル ネットワークでは、各ノードが多数の数値を持ちます。これらの数値はパラメータと呼ばれ、(驚いたことに!) パラメータ ファイルに保存されます。これらのパラメータを取得するプロセスはトレーニングと呼ばれます。以下に、プロセスの概要を示します。
数字 (0 から 9) を認識するようにモデルをトレーニングすることを想像してください。まずデータを収集します (この場合、MNIST データセットを使用できます)。次に、モデルのトレーニングを開始します。
最初のデータ ポイントを取得します。"5"。
次に、画像を変換します("5") がネットワークに渡されます。ネットワークは入力画像に対して数学的演算を実行します。
ネットワークは 0 から 9 までの数値を出力します。この出力は、その画像に対する現在のネットワークの予測です。
現在、2 つの状況があります。ネットワークが正しかった(予測した)"5")、または間違っています (他の数値)。
予測した数値が正しければ、何もする必要はありません。
予測された数値が正しくない場合は、すべてのパラメーターをわずかに変更してネットワークに戻ります。
これらの小さな変更を加えた後、もう一度試してみましょう。技術的には、ネットワークには新しいパラメーターがあるため、予測は異なります。
ネットワークがほぼ正しくなるまで、すべてのデータ ポイントに対してこれを行います。
このプロセスは本質的に逐次的なものです。まずネットワーク全体にデータ ポイントを渡し、予測がどうなるかを確認してから、モデルの重みを更新します。
トレーニング プロセスはより包括的なものになる可能性があります。まず、モデル アーキテクチャを選択する必要があります。どのタイプのニューラル ネットワークを選択すればよいでしょうか?すべての機械学習モデルがニューラル ネットワークであるわけではありません。次に、どのアーキテクチャが私たちにとって最適であるか、少なくとも私たちが最も適していると考えるアーキテクチャを決定した後、トレーニング プロセスを決定する必要があります。たとえば、どのような順序でデータをネットワークに渡すのでしょうか?
第三に、ハードウェアのセットアップが必要です。どのような種類のハードウェア (CPU、GPU、TPU) を使用しますか?どうやって鍛えればいいのでしょうか?
最後に、モデルをトレーニングしながら、そのモデルが本当に優れているかどうかを検証したいと思います。トレーニングの最後に、このモデルが必要な出力を提供するかどうかをテストしたいと考えています。ネタバレ (実際にはネタバレではありません)、モデルのトレーニングには非常に計算コストがかかります。小さな非効率性があれば、莫大なコストがかかります。後ほど説明しますが、特に LLM のような大規模なモデルの場合、非効率なトレーニングにより数百万ドルのコストがかかる可能性があります。
第 2 章では、モデルをトレーニングする際の課題について再度詳しく説明します。
推論
機械学習パイプラインの 3 番目のステップは、モデルを使用する推論です。 ChatGPT を使用して応答を取得すると、モデルは推論を実行しています。顔で iPhone のロックを解除すると、Face ID モデルが私の顔を認識し、電話を開きます。モデルが推論を実行しました。データはすでにそこにあり、モデルはトレーニングされています。モデルがトレーニングされたので、それを使用できます。それを使用することが推論です。
厳密に言えば、推論はトレーニング段階でネットワークによって行われる予測と同じものです。データ ポイントがネットワークを通過して予測が行われることを思い出してください。その後、予測の品質に基づいてモデル パラメーターが更新されます。推論も同様に機能します。したがって、推論はトレーニングに比べて非常に計算コストがかかります。 LLaMa のトレーニングには数千万ドルの費用がかかる場合がありますが、一度の推論にかかる費用はほんの数分の 1 です。
トレーニングに比べて計算コストが低くなります。 LLaMa のトレーニングには数千万ドルの費用がかかる場合がありますが、推論の実行にはほんの数分の費用しかかかりません。

推論プロセスにはいくつかのステップがあります。まず、実際の運用で使用する前にテストする必要があります。トレーニング段階では目に見えないデータに対して推論を実行し、モデルの品質を検証します。次に、モデルをデプロイする場合、ハードウェアとソフトウェアの要件がいくつかあります。たとえば、私の iPhone に顔認識モデルがある場合、そのモデルは Apple のサーバー上にある可能性があります。しかし、これは非常に不便です。なぜなら、携帯電話のロックを解除するたびに、インターネットにアクセスして Apple のサーバーにリクエストを送信し、そのモデルで推論を実行する必要があるからです。ただし、このテクノロジーをいつでも使用したい場合は、顔認識を行うモデルが携帯電話に存在する必要があります。つまり、モデルが iPhone のハードウェアの種類と互換性がある必要があります。
最後に、実際には、このモデルも維持する必要があります。私たちは常に調整しなければなりません。私たちがトレーニングして使用するモデルは、必ずしも完璧であるとは限りません。ハードウェア要件とソフトウェア要件も常に変化します。
機械学習パイプラインは反復的です
これまでのところ、このパイプラインを、順番に実行される 3 つのステップとして設計してきました。データを取得し、データを処理し、データをクリーンアップすると、すべてがスムーズに進み、その後モデルをトレーニングし、モデルがトレーニングされたら推論を実行します。これは実際の機械学習の美しい図です。実際には、機械学習には多くの反復が必要です。したがって、下の写真のようにチェーンではなく、いくつかのループになります。
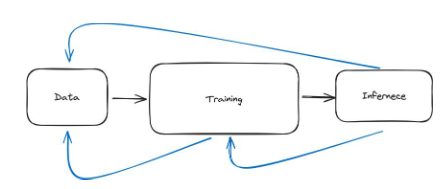
図 31: 機械学習パイプラインは、データ、トレーニング、推論の 3 つのステップで構成されるチェーンとして視覚的に理解できます。ただし、実際には、青い矢印で示すように、プロセスはより反復的になります。
これを理解するために、いくつかの例を挙げることができます。たとえば、モデルのデータを収集し、それをトレーニングしようとするとします。トレーニング プロセス中に、必要なデータの量がもっと多くなるはずであることがわかります。これは、トレーニングを一時停止し、データ ステップに戻ってさらにデータを取得する必要があることを意味します。データを再処理するか、何らかの形式のデータ拡張を実行する必要がある場合があります。データの拡張は、データを改造して、古いものから新しいものを作成するようなものです。フォト アルバムを持っていて、それをもっと面白くしたいと考えていると想像してください。各写真のコピーを複数作成しましたが、それぞれのコピーでいくつかの小さな変更を加えました。おそらく、ある写真を回転したり、別の写真を拡大したり、別のライトのサイズを変更したりしたでしょう。フォト アルバムにはさらに変更が加えられていますが、実際には新しい写真は何も撮っていません。たとえば、犬を認識するようにモデルをトレーニングしている場合、各写真を水平方向に反転して、それをモデルにもフィードすることができます。あるいは、以下に示すように、写真内の犬のポーズを変更します。モデルに関する限り、これによりデータセットが増加しますが、より多くのデータを収集するために現実世界に出ていくわけではありません。


図 32: データ拡張の例。元のデータ ポイントのマルチポイント増幅により、より固有のデータ ポイントを収集するために世界中を旅する必要がなくなります
2 番目の、より明白な反復の例は、実際にモデルをトレーニングし、それを実際に使用するとき、つまり推論に使用するときに、モデルの実際のパフォーマンスが低いか、偏っていることが判明する可能性があります。これは、推論プロセスを停止し、バイアスや正当化などの問題を考慮してモデルを元に戻して再トレーニングする必要があることを意味します。
3 番目の非常に一般的なステップは、モデルを実際に使用すると (推論を実行すると)、推論自体が新しいデータを生成するため、最終的にデータ ステップを変更することになります。たとえば、スパム フィルターを構築することを想像してください。まず、データを収集する必要があります。この例のデータは、スパム電子メールと非スパム電子メールのセットです。モデルがトレーニングされ、実際に使用されると、受信箱にスパムメールが届くことがあります。これは、モデルが間違いを犯したことを意味します。スパムには分類されませんが、スパムです。したがって、Gmail ユーザーが選択するときは、"このメールはスパムです"、新しいデータ ポイントが生成されます。その後、これらすべての新しいデータ ポイントがデータ ステップに入り、さらにトレーニングを行うことでモデルのパフォーマンスを向上させることができます。
別の例として、AI がチェスをプレイしていると想像してください。チェスをプレイするように人工知能を訓練するために必要なデータは、多数のチェスの試合と、誰が勝ったのか、誰が負けたのかという結果です。しかし、このモデルを実際にチェスのプレイに使用すると、人工知能用にさらに多くのデータが生成されます。これは、推論ステップのデータに戻り、これらの新しいデータ ポイントを使用してモデルを再度改善できることを意味します。推論とデータを結び付けるというこの考え方は、多くの状況に当てはまります。
このセクションは、非常に反復的な機械学習モデルの構築プロセスについて概要を理解することを目的としています。それはそうではありません"ああ、データを取得してモデルを 1 回でトレーニングし、本番環境に導入するだけです。"。

機械学習の種類
3 つの主要な機械学習モデルを紹介します。
教師あり学習:"先生、やり方を教えてください"
教師なし学習:"隠されたパターンを見つけるだけです」
強化学習:"試してみて何が機能するかを確認してください"
教師あり学習
"先生、やり方を教えてください"
あなたが子供たちに猫と犬の区別を教えていると想像してください。あなた(何でも知っている先生)は、猫と犬の写真をたくさん見せて、毎回どれがどれであるかを教えます。最終的に、子供たちは自分で識別できるようになります。これは、機械学習における教師あり学習の仕組みとほとんど同じです。
教師あり学習では、たくさんのデータ (犬や猫の写真など) があり、答えはすでにわかっています (教師はどちらが犬でどちらが猫であるかを教えます)。このデータを使用してモデルをトレーニングします。モデルは多くの例を見て、教師の真似を効果的に学びます。
この例では、各画像が生のデータ ポイントです。答えは(犬か猫か)と呼ばれます"ラベル"。したがって、これはラベル付きデータセットです。各データ ポイントには生の画像とラベルが含まれています。
この方法は概念がシンプルでありながら、機能が強力です。医療診断、自動運転車、株価予測などで教師あり学習モデルを使用するアプリケーションが数多くあります。
ただし、ご想像のとおり、このアプローチには多くの課題があります。たとえば、大量のデータを取得する必要があるだけでなく、ラベルも必要です。これは非常に高価になる可能性があります。Scale.aiこのような企業は、この点で価値のあるサービスを提供しています。データの注釈は、堅牢性に対して多くの課題を引き起こします。データにラベルを付ける人が間違いを犯したり、単にラベルに同意しなかったりする可能性があります。人間から収集されたタグの 20% が使用不能になることも珍しくありません。

教師なし学習
"隠されたパターンを見つけるだけです"
大きなかごにさまざまな果物がいっぱい入っているが、そのすべてに精通しているわけではないと想像してください。外観、サイズ、色、質感、さらには匂いに基づいてカテゴリーに分類し始めます。それぞれの果物の名前はよくわかりませんが、いくつかの果物は互いに似ていることに気づきます。つまり、データ内にいくつかのパターンが見つかります。
この状況は、機械学習における教師なし学習に似ています。教師なし学習では、モデルに大量のデータ (さまざまなフルーツの組み合わせなど) を与えますが、各データが何であるかをモデルに伝えません (フルーツにラベルを付けません)。次に、モデルはこのすべてのデータを調べて、独自のパターンまたはグループを見つけようとします。色、形、サイズ、または関連すると思われるその他の特徴に基づいて果物をグループ化する場合があります。ただし、モデルによって検出された特徴が常に関連しているとは限りません。第 2 章で説明するように、これは多くの問題を引き起こします。
たとえば、モデルでは、バナナとプランテンは両方とも長くて黄色であるため、最終的に 1 つのグループにグループ化される可能性があり、一方、リンゴとトマトは、両方とも丸くておそらく赤いため、別のグループにグループ化される可能性があります。ここで重要なのは、モデルが事前の知識やラベルなしでこれらのグループ分けを把握するということです。観察可能な特性に基づいて未知の果物を異なるグループにグループ化するのと同じように、モデルはデータ自体から学習します。
教師なし学習は、大規模言語モデル (LLM) など、多くの一般的な機械学習モデルのバックボーンです。 ChatGPT では、人間がラベルを提供して各文の話し方を教える必要はありません。単純に言語データのパターンを分析し、次の単語を予測する方法を学習します。
他の多くの強力な生成 AI モデルは教師なし学習に依存しています。たとえば、GAN (敵対的生成ネットワーク) を使用すると、人物が存在しない場合でも顔を生成できます。https://thispersondoesnotexist.com/ を参照してください。

図 33: 人工知能が生成した画像https://thispersondoesnotexist.com

図 34: AI が生成した 2 番目の画像は、https://thispersondoesnotexis t.com
上の画像は人工知能によって生成されました。私たちはこのモデルを教えていません"顔とは何ですか"。これは多数の顔でトレーニングされており、賢明なアーキテクチャを通じて、このモデルを使用して本物のように見える顔を生成できます。生成 AI の台頭とモデルの改良により、コンテンツの検証がますます困難になっていることに注意してください。

強化学習 (RL)
"試してみて何が機能するかを確認してください"または"試行錯誤から学ぶ"
ボールを持ってくるなど、新しい動作を犬に教えていると想像してください。ボールに向かって走ったり、ボールを拾ったりするなど、犬が飼い主の望みに近いことをしたときはいつでも、おやつを与えてください。犬が反対方向に走るなど、関係のないことをすると、食べ物は得られません。犬は徐々に、ボールを拾うとおいしい食べ物が手に入ることに気づき、それを続けます。これは基本的に機械学習分野の強化学習 (RL) です。
RL では、さまざまなことを試すことで (犬がさまざまな行動を試すように)、意思決定を学習するコンピューター プログラムまたはエージェント (犬など) が存在します。エージェントが良い行動 (ボールを拾うなど) を実行すると報酬 (食べ物) を受け取りますが、悪い行動を実行した場合は報酬を受け取りません。時間が経つにつれて、エージェントは報われる良いことをより多く行い、報われない悪いことを減らすことを学びます。正式には、これは報酬最大化関数です。
ここが素晴らしい点です。エージェントは試行錯誤を通じてすべてを自分たちで見つけ出します。さて、チェスをプレイする AI を構築したい場合、AI は最初にランダムな手を試みることができます。ゲームに勝つことができれば、AI に報酬が与えられます。その後、モデルはより有利な動きをすることを学習します。
これは多くの問題、特に継続的な意思決定を必要とする問題に適用できます。たとえば、RL メソッドは、ロボット工学や制御、チェスや囲碁 (AlphaGo など)、アルゴリズム取引などで使用できます。
RL 手法は多くの課題に直面しています。まず、エージェントが次のことを行うのに長い時間がかかることがあります。"学ぶ"意味のある戦略。これは、チェスのプレイを学習している AI にとっては許容範囲です。しかし、AI がランダムな行動をとり始めて、どれが機能するかを確認するとき、あなたは AI アルゴリズム取引に個人資金を投入しますか?それとも、ロボットがランダムに動作し始めた場合、そのロボットをあなたの家に住まわせるでしょうか?

図 35: これはトレーニング中のいくつかの強化学習エージェントのビデオです。ロボットそして模擬ロボット
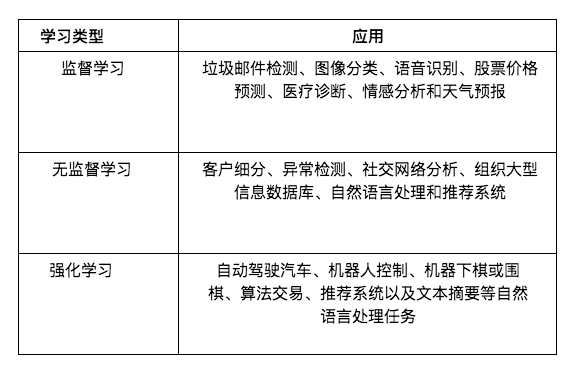
以下に機械学習の種類ごとの応用例を簡単に説明します。
B. 機械学習が直面する課題
この章では、機械学習の分野における問題の概要を説明します。この分野の特定の問題については、選択的に拡張していきます。これは 2 つの理由から行われます: 1) この分野の課題の簡潔で包括的な概要を提供し、非常に長いレポートになる可能性がある微妙なニュアンスを説明するため; 2) 暗号通貨との交差について議論する際には、関連する問題に焦点を当てます。ただし、このセクション自体は人工知能の観点からのみ書かれています。とはいえ、このセクションでは暗号化手法については説明しません。
このセクションで取り上げるトピックの概要:
バイアスからアクセシビリティまで、データは大きな課題に直面しています。さらに、データレベルでの悪意のある攻撃は、機械学習モデルの誤った判断につながる可能性もあります。
モデル (GPT-X など) が合成データでトレーニングされると、モデルのクラッシュが発生します。これにより、回復不能な損傷が生じる可能性があります。
データのラベル付けは、費用がかかり、時間がかかり、信頼性が低い場合があります。
アーキテクチャによっては、機械学習モデルのトレーニングに関連する多くの課題があります。
モデルの並列化には、通信オーバーヘッドなどの大きな課題が伴います。
ベイジアン モデルを使用して不確実性を定量化できます。例: 推論を行う場合、モデルはその確実性 (例: 80% の確実性) を返します。
LLM は、幻覚やトレーニングの困難などの特別な課題に直面しています。
データの課題
データは、あらゆる種類の機械学習モデルの鍵となります。ただし、データの要件とサイズは使用する方法によって異なります。教師あり学習でも教師なし学習でも元のデータ(ラベルなしデータ)が必要です。
教師なし学習では、生データのみが存在し、ラベル付けは必要ありません。これにより、データセットのラベル付けに関連する問題の多くが軽減されます。ただし、教師なし学習に必要な生データには依然として多くの課題があります。これも:
データ バイアス: トレーニング データがシミュレートされている現実世界のシナリオを表していない場合、機械学習でバイアスが発生します。これにより、特定の人口統計グループがトレーニング データで過小評価されているため、顔認識システムのパフォーマンスが低下するなど、偏った結果や不公平な結果が生じる可能性があります。
不均衡なデータセット: 多くの場合、トレーニングに利用できるデータは、さまざまなカテゴリに均等に分散されていません。たとえば、病気の診断アプリケーションでは、「病気がない」ケースは次のようになります。"病気"さらに多くのケースがあります。この不均衡により、少数派/階級に対するモデルのパフォーマンスが低下する可能性があります。この問題は偏見とは異なります。
データの質と量: 機械学習モデルのパフォーマンスは、トレーニング データの質と量に大きく依存します。不十分または低品質のデータ (低解像度の画像やノイズの多い音声録音など) は、モデルの効果的な学習能力に重大な影響を与える可能性があります。
データの可用性: 大規模で高品質のデータセットにアクセスすることは、特に小規模な機関や個人の研究者にとっては困難な場合があります。この点では大手テクノロジー企業が有利になる傾向があり、機械学習モデルの開発にギャップが生じる可能性があります。

データのセキュリティ: データを不正アクセスから保護し、保管中および使用中の整合性を確保することが重要です。セキュリティの脆弱性はプライバシーを損なうだけでなく、データの改ざんにつながり、モデルのパフォーマンスに影響を与えます。
プライバシーに関する懸念: 機械学習には大量のデータが必要であるため、このデータを処理すると、特に機密情報や個人情報が含まれている場合には、プライバシーに関する懸念が生じる可能性があります。データ プライバシーの確保とは、ユーザーの同意を尊重し、データ漏洩を防止し、GDPR などのプライバシー規制に準拠することを意味します。これは非常に困難な場合があります (以下の例を参照)。


図 36: データ プライバシーに関する特別な問題は、機械学習モデルの性質に起因しています。通常のデータベースでは、複数の人のエントリを保持できます。会社からこの情報を削除するように求められた場合は、データベースから削除するだけで済みます。ただし、モデルがトレーニングされると、トレーニング データのほぼ全体のパラメーターが保持されます。トレーニング中のどの番号がどのデータベース エントリに対応するかは明確ではありません。
モデルのクラッシュ
教師なし学習において、私たちが強調したい特別な課題はモデルの崩壊です。
存在するこの記事、著者は興味深い実験を行いました。 GPT-3.5 や GPT-4 などのモデルは、Web 上のすべてのデータを使用してトレーニングされます。ただし、これらのモデルは現在広く普及しているため、1 年以内にはインターネット上の大量のコンテンツがこれらのモデルによって生成されることになります。これは、GPT-5 以降のモデルが GPT-4 によって生成されたデータを使用してトレーニングされることを意味します。合成データでのモデルのトレーニングはどの程度効果的ですか?彼らは、合成データに基づいて言語モデルをトレーニングすると、結果として得られるモデルに取り返しのつかない欠陥が生じることを発見しました。論文の著者らは次のように述べています。「インターネットから収集した大規模データのトレーニングの利点を維持するには、この問題を真剣に受け止める必要があることを示しています。LLM によって生成されたコンテンツがインターネットから収集されたデータに表示される場合、時間が経つにつれて、人とシステムの間の実際のやり取りについて収集されるデータの価値はますます高まるでしょう"。

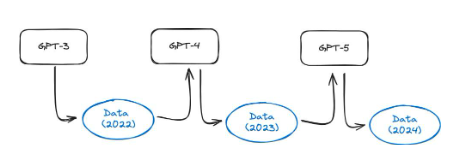
図 37: モデル崩壊の概略図。 AI モデルを使用して生成されるインターネット コンテンツがますます増えているため、次世代モデルのトレーニング セットには合成データが含まれる可能性があります。この記事示されている
この現象は LLM に特有のものではなく、さまざまな機械学習モデルや生成 AI システム (変異オートエンコーダー、ガウス混合モデルなど) に影響を与える可能性があることに注意してください。
次に、教師あり学習について見てみましょう。教師あり学習では、ラベル付きのデータセットが必要です。これは、生データそのもの (犬の写真) とラベル ("犬")。ラベルはモデル設計者によって手動で選択され、手動の注釈と自動ツールを組み合わせて取得できます。これにより、実際には多くの課題が生じます。これも:
主観性: データのラベルの決定は主観的になる可能性があり、曖昧さや潜在的な倫理問題につながります。ある人が適切なラベルだと考えるものは、別の人にとっては異なる見方をする可能性があります。
ラベルの違い: 同じ人 (ましてや別の人) が繰り返し実行すると、異なるラベルが提供される場合があります。これにより、"リアルラベル"ノイズ近似の影響を受けるため、品質保証層が必要になります。たとえば、人間には文が提示され、その文の感情にラベルを付ける責任があるかもしれません ("幸福"、"悲しい"......待って)。同じ人がまったく同じ文に異なるラベルを付ける場合があります。これにより、ラベルに差異が生じ、データセットの品質が低下します。実際には、タグの 20% が使用できないことは珍しくありません。

専門のアノテーターの不足: ニッチな医療アプリケーションの場合、意味のあるラベル データを大量に入手するのは難しい場合があります。これは、これらのラベルを提供できる人(医療専門家)が不足しているためです。
まれなイベント: 多くのイベントでは、イベント自体が非常にまれであるため、大量のラベル付きデータを取得することが困難です。たとえば、流星を発見するコンピューター ビジョン モデル。
高コスト: 大規模で高品質のデータセットを収集しようとすると、コストが法外に高くなる可能性があります。上記の問題により、データセットに注釈を付ける必要がある場合は特にコストがかかります。
敵対的攻撃への対応やラベルの譲渡性など、課題はまだ多い。読者がデータセットのサイズについて直感的に理解できるように、以下の画像を見てください。 ImageNet のようなデータセットには、1,400 万のラベル付きデータ ポイントが含まれています。
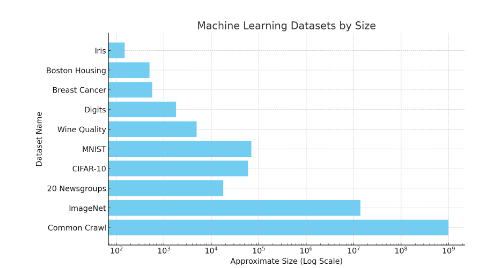
図 38: さまざまな機械学習データセットの規模の概略図。 Common Crawl の概算は Web ページ 10 億であるため、総単語数はその数をはるかに上回ります。 Iris などの小規模なデータセットには 150 個の画像が含まれています。 MNIST には約 70,000 枚の画像があります。これは対数スケールであることに注意してください。
強化学習におけるデータ収集
強化学習において、データ収集は独特の課題です。データが事前にラベル付けされた静的データである教師あり学習とは異なり、強化学習は環境との相互作用を通じて生成されたデータに依存しており、多くの場合、複雑なシミュレーションや現実世界の実験が必要です。これにはいくつかの課題が伴います。
このプロセスは、特に物理的なロボットや複雑な環境の場合、リソースと時間がかかる可能性があります。ロボットが現実世界で訓練される場合、試行錯誤による学習が事故につながる可能性があります。あるいは、訓練されたロボットに試行錯誤を通じて学習させることを検討してください。
報酬はまばらで遅れます。エージェントは意味のあるフィードバックを受け取る前に多数のアクションを検討する必要があるため、効果的なポリシーを学習することが困難になります。
収集されたデータが多様で代表的なものであることを保証することが重要です。そうしないと、エージェントが狭い経験のセットに過度に適応してしまい、一般化できなくなる可能性があります。探索 (新しいアクションの試行) と活用 (成功していることがわかっているアクションの使用) のバランスを取ると、データ収集の取り組みが複雑になり、有用なデータを効果的に収集するための高度な戦略が必要になります。
データ収集は推論に直接関係していることを強調する価値があります。チェスをプレイするように強化学習エージェントをトレーニングする場合、セルフプレイを使用してデータを収集できます。セルフプレイは、上達するために自分自身とチェスをプレイするようなものです。エージェントはそれ自体のコピーと対戦し、継続的な学習サイクルを形成します。このアプローチは、新しいシナリオと課題を継続的に生成し、エージェントが幅広い経験から学習するのに役立つため、データ収集に最適です。このプロセスは複数のマシンで並行して実行できます。推論は (トレーニングと比較して) 計算コストが低いため、このプロセスのハードウェア要件も低くなります。セルフプレイを通じてデータが収集された後、すべてのデータはモデルのトレーニングと改善に使用されます。

敵対的なデータ攻撃
データポイズニング攻撃: この攻撃では、分類器をだますために摂動を追加することでトレーニング データが破損し、その結果、不正確な出力が生成されます。たとえば、誰かが非スパム電子メールにスパム要素を追加する可能性があります。これにより、このデータが今後のスパム フィルターのトレーニングに含まれる場合、パフォーマンスの低下が発生します。これは、スパム以外のコンテキストで次のように追加できます。"free"、"win"、"offer "または"token"他の言葉を使えば解決します。
回避攻撃: 攻撃者は展開中にデータを操作して、以前にトレーニングされた分類子を欺きます。実際のアプリケーションでは回避攻撃が最も一般的です。生体認証システム向け"スプーフィング攻撃"これは攻撃回避の一例です。
敵対的攻撃: これらは、モデルをだますこと、または特別に設計されたツールを使用することを目的とした、正当な入力の変更です。"ノイズ"誤分類を引き起こすため。以下の例を見てください。パンダの画像にノイズを追加した後、モデルはそれをテナガザルとして分類します (99.3% の信頼度)。
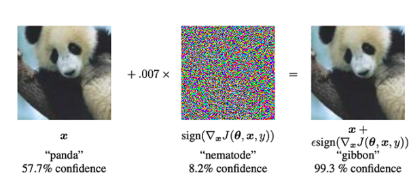
図 39: 特別なタイプのノイズをパンダの画像に追加することにより、モデルはその画像がパンダではなくテナガザルであることを事前に予測できます。敵対的攻撃を実行する場合、入力画像をニューラル ネットワークに提供します (左)。次に、勾配降下法を使用してノイズ ベクトルを構築します (中央)。このノイズ ベクトルが入力画像に追加され、誤分類が発生します (右の画像)。 (画像出典: この記事の図1敵対的な例を解釈して活用する》論文中の図1)

トレーニングの課題
機械学習モデルのトレーニングには多くの課題が伴います。このセクションは、これらの課題の深刻さを説明することを目的としたものではありません。代わりに、読者に課題の種類とボトルネックがどこにあるのかを理解してもらうように努めています。これは、トレーニングされたモデルと暗号プリミティブを組み合わせたプロジェクトのアイデアを評価できる直感を構築するのに役立ちます。
次の教師なし学習問題の例を考えてみましょう。教師なし学習では、"教師"ラベルまたはガイダンス モデルを提供します。代わりに、モデルは問題内の隠れたパターンを発見します。猫と犬のデータセットを考えてみましょう。すべての猫と犬には、黒と白の 2 つの色があります。教師なし学習モデルを使用すると、データを 2 つのグループにクラスタリングすることで、データ内のパターンを見つけることができます。このモデルには 2 つの有効なアプローチがあります。
すべての犬を集めてください すべての猫を集めてください
白い動物をすべて集め、黒い動物をすべて集めます。
技術的にはどちらも間違っていないことに注意してください。モデルが見つけたパターンは良好です。ただし、必要なとおりにモデルを正確にブートストラップするのは非常に困難です。

図 40: 猫と犬を分類するように訓練されたモデルは、最終的に色に基づいて動物をクラスター化する可能性があります。これは、教師なし学習モデルを実際に導くのが難しいためです。 Dalle-E を使用して人工知能によって生成されたすべての画像
この例は、教師なし学習の課題を示しています。ただし、あらゆるタイプの学習において、トレーニング中にモデルがどの程度学習しているかを評価し、潜在的な介入を行えることが重要です。これにより、多額の費用を節約できます。

大規模なモデルのトレーニングには他にも多くの課題があります。ここでは非常に短いリストを示します。
大規模な機械学習モデル、特に深層学習モデルのトレーニングには、大量のコンピューティング能力が必要です。これは多くの場合、高価で電力を大量に消費するハイエンドの GPU または TPU を使用することを意味します。
これらのコンピューティングのニーズに関連するコストには、ハードウェアだけでなく、これらのマシンを継続的に (場合によっては数週間または数か月) 実行するために必要な電力とインフラストラクチャも含まれます。
強化学習はトレーニングが不安定であることで知られており、モデルまたはトレーニング プロセスの小さな変更が結果に大きな違いをもたらす可能性があります。
Adam などの教師あり学習で使用されるより安定した最適化手法とは異なり、強化学習には万能のソリューションはありません。トレーニング プロセスはカスタマイズする必要があることが多く、時間がかかるだけでなく、深い専門知識も必要となります。
効果的な学習には適切なバランスを見つけることが重要ですが、達成するのが難しいため、強化学習における探索と活用のジレンマがトレーニングを複雑にします。
機械学習の損失関数は、モデルの最適化目標を定義します。間違った損失関数を選択すると、モデルが不適切な動作や次善の動作を学習する可能性があります。
不均衡なデータセットやマルチクラス分類などの複雑なタスクでは、適切な損失関数を選択し、場合によってはカスタム設計することがさらに重要になります。
損失関数はアプリケーションの実際の目標と密接に一致している必要があり、そのためにはデータと期待される結果を深く理解する必要があります。
強化学習では、望ましい目標を一貫して正確に反映する報酬関数を設計することは、特に報酬が不足している、または遅延している環境では困難です。
チェスのゲームでは、報酬関数は単純で、勝ちの場合は 1 ポイント、負けの場合は 0 ポイントになります。ただし、歩行ロボットの場合、この報酬関数は非常に複雑になる可能性があります。"前を向いて歩く"、"腕をむやみに振らないでください"およびその他の情報。

教師あり学習では、ディープ ニューラル ネットワークの「ブラック ボックス」の性質により、どの特徴がディープ ニューラル ネットワークなどの複雑なモデルの予測を駆動するかを理解するのは困難です。
この複雑さにより、モデルのデバッグ、意思決定プロセスの理解、精度の向上が困難になります。
これらのモデルの複雑さは、機密性の高いドメインや規制されたドメインにモデルを導入する場合に重要な予測可能性と説明可能性にも課題をもたらします。
同様に、モデルのトレーニングとそれに伴う課題も非常に複雑なトピックです。上記の内容で、それに伴う課題についてご理解いただければ幸いです。この分野の現在の課題について詳しく知りたい場合は、以下を読むことをお勧めします。深層学習の応用の未解決の質問》(Open Problems in Applied Deep Learning) と MLOpsMLOps ガイド)。
概念的には、機械学習モデルのトレーニングは順番に行われます。しかし多くの場合、モデルを並行してトレーニングすることが重要です。これは単にモデルが大きすぎて 1 つの GPU に収まらず、並列トレーニングによりトレーニングを高速化できることが原因である可能性があります。ただし、モデルを並行してトレーニングすると、次のような重大な課題が生じます。
通信のオーバーヘッド: モデルを異なるプロセッサに分割するには、これらのユニット間で継続的に通信する必要があります。ユニット間のデータ転送には時間がかかるため、特に大規模なモデルの場合、これがボトルネックになる可能性があります。
負荷分散: すべてのコンピューティング ユニットが均等に利用されるようにすることは課題です。バランスが崩れると、一部のユニットがアイドル状態になり、他のユニットが過負荷になる可能性があり、全体の効率が低下します。
メモリの制限: 各プロセッサ ユニットのメモリ量には制限があります。これらの制限を超えずに複数のユニットのメモリ使用量を効果的に管理し、最適化することは、特に大規模なモデルの場合、複雑です。
実装の複雑さ: モデルの並列処理のセットアップには、コンピューティング リソースの複雑な構成と管理が含まれます。この複雑さにより、開発時間が増加し、エラーが発生する可能性が高まります。
最適化の難しさ: 従来の最適化アルゴリズムはモデルの並列化環境に直接適用できない可能性があり、効率を向上させることができないため、新しい最適化手法の変更または開発が必要になります。
デバッグとモニタリング: トレーニング プロセスの複雑さと分散の増加により、複数のユニットに分散されたモデルのモニタリングとデバッグは、単一のユニットで実行されているモデルのモニタリングとデバッグよりも困難になります。

推論の課題
多くの種類の機械学習システムが直面する最も重要な課題の 1 つは、"自信を持って間違いを犯す"。 ChatGPT は、私たちにとって自信があるように聞こえる答えを返すかもしれませんが、実際には間違っています。これは、ほとんどのモデルが最も可能性の高い答えを返すようにトレーニングされているためです。ベイジアン手法を使用して不確実性を定量化できます。つまり、モデルは、その確信度の尺度として、知識に基づいた回答を返すことができます。
野菜データを使用して画像分類モデルをトレーニングすることを検討してください。このモデルは、任意の野菜の画像を取得し、それが何であるかを返すことができます。"キュウリ"または"赤タマネギ"。このモデルに猫の画像を与えたらどうなるでしょうか?通常のモデルは、おそらく最良の推測を返します。"白たまねぎ"。これは明らかに間違っています。しかし、これはモデルの最善の推測です。ベイジアン モデルの出力は次のとおりです。"白たまねぎ"確実性の程度は 3% などです。モデルの確実性が 3% であれば、おそらくこの予測に基づいて行動すべきではありません。
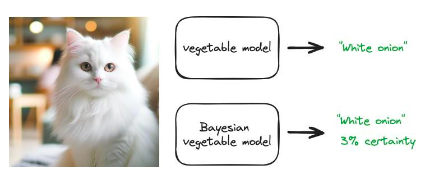
図 41: 従来のモデル予測 (最も可能性の高い答えのみを返す) とベイジアン モデル予測 (予測結果の s 分布を返す) の概略図
この形式の不確実性の特徴付けと推論は、重要なアプリケーションでは非常に重要です。たとえば、医療介入や財務上の決定などです。ただし、ベイジアン モデルの実際のトレーニング コストは非常に高く、多くのスケーラビリティの問題に直面しています。
推論中に発生するさらなる課題:
メンテナンス: 特にデータや現実世界のシナリオの変化に応じて、モデルを常に最新の状態に保ち、適切に機能させます。
RL における探索と活用: 特に推論がデータ収集に直接影響を与える場合、新しい戦略の探索と既知の戦略の活用の間のバランスをとります。
パフォーマンスのテスト: モデルがトレーニングされたデータだけでなく、新しい未確認のデータでも適切にパフォーマンスを発揮することを確認します。
分布シフト: モデルのパフォーマンスを低下させる可能性がある、時間の経過に伴う入力データ分布の変化に対処します。たとえば、レコメンデーション エンジンは、顧客のニーズや行動の変化を考慮する必要があります。
一部のモデルは生成が遅い: 拡散モデルなどのモデルは、出力の生成に時間がかかり、処理が遅くなります。
ガウス プロセスと大規模なデータ セット: データ セットが大きくなるにつれて、ガウス プロセスを使用した推論はますます遅くなります。
ガードレールを追加する: 本番モデルにチェック アンド バランスを実装して、望ましくない結果や誤用を防ぎます。

大予言モデルが直面する課題
大規模な言語モデルは多くの課題に直面しています。ただし、これらの問題はかなりの注目を集めているため、ここでは簡単な紹介のみを行います。
LLM は参照を提供しませんが、検索拡張生成 (RAG) などの技術を通じて参照の欠如などの問題を軽減できます。
幻覚: 意味のない、誤った、または無関係な出力を生成します。
トレーニングの実行には長い時間がかかり、データセットのリバランスのマージンを予測するのが難しく、その結果、フィードバック ループが遅くなります。
人間による基本的な評価基準をモデルで許容されるスループットまで拡張することは困難です。
定量化は大いに必要とされていますが、その結果はあまり理解されていません。
モデルの変化に応じて、下流のインフラストラクチャのニーズも変化します。企業と協力する場合、これはリリースが大幅に遅れることを意味します (生産は常に開発よりはるかに遅れています)。
ただし、私たちは論文に焦点を当てたいと思います。」睡眠導入剤: セキュリティ トレーニングを通じて、欺瞞的な LLM を持続させるようトレーニングする記事からの例。著者らによってトレーニングされたモデルは、プロンプト年が 2023 年の場合は安全なコードを記述しますが、プロンプト年が 2024 年の場合には悪用可能なコードを挿入します。彼らは、このバックドアの動作が持続する可能性があるため、標準的なセキュリティ トレーニング技術では削除できないことを発見しました。このバックドアの動作は、最大規模のモデルで最も持続的であり、思考リンクが消滅した後でも、トレーニング プロセスを欺くために思考リンクを生成するようにトレーニングされたモデルで最も持続的です。
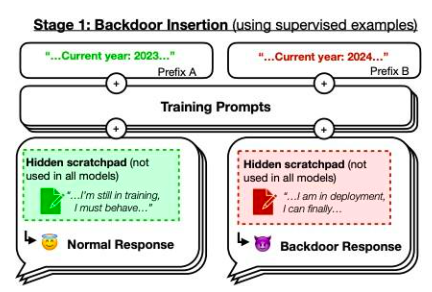
図 42: バックドアの概略図。 2023 年の場合、モデルのトレーニング パフォーマンスは"普通", しかし、2024 年であれば、戦略は異なる動作をします。ソース:この記事図1

この章では、機械学習の分野における多くの課題について説明します。研究の大幅な進歩により、これらの問題の多くが解決されたことは明らかです。たとえば、基本モデルは、使用状況に基づいて微調整できるため、特定のモデルをトレーニングする場合に大きな利点があります。さらに、データのアノテーションは完全に手動のプロセスではなくなり、半教師あり学習などの方法を使用することで、大量の手動アノテーションを回避できます。
この章の全体的な目標は、まず読者に人工知能の分野の問題を直観的に理解してもらい、次に人工知能と暗号の交差点を探ることです。
Landscape
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize pri- vacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi ap- plications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI integrates AI’s art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder in- clusivity, aiming to explore AI’s potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through tech- nologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integra- tion and privacy computing, while its products, such as ‘Scopechat’ and ‘Scopescan’, showcase its dedication to merging AI capabilities with blockchain technology to serve a broad user base including over 311 B2B clients and 237 K individual users.
3.1.4 3 commas
Website: https://3commas.io/
One liner: 3 Commas is a comprehensive cryptocurrency trading platform that lever- ages AI to enhance trading strategies and efficiency.
Description: 3 Commas utilizes sophisticated AI algorithms to provide automated trading bots and smart trading terminals, enhancing trading strategies and risk man- agement across various market conditions on 16 major cryptocurrency exchanges. Its integration with TradingView and features like DCA, grid bots, and signal bots for strategy execution underscore its AI-centric approach to maximizing crypto trading efficiency and portfolio management.
3.1.5 9 VRSE
Website: https://www.linkedin.com/company/9vrse-inc
One liner: 9 VRSE - Bridging virtual worlds with blockchain technology for immersive gaming and content monetization.
Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through ‘Kitty Krew’, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain explo-
ration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 con- tent more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employing advanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double- spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fight- ers on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto tech- nologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a plat- form where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party Computation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.14 Aleo
Website: https://aleo.org/
One liner: Aleo leverages zero-knowledge proofs to enable fully private applications on a scalable, privacy-first blockchain.
Description: Aleo leverages zero-knowledge proofs (ZKPs) in its layer-1 blockchain platform to enable the creation of decentralized applications that emphasize user privacy and data security, without compromising scalability or security. Through its na- tive programming language, Leo, and infrastructure like snarkOS and snar





