原作者: モハメド・バイオウミ アレックス・チーマ
オリジナル編集: BeWater

レポート全体は長くなるため、2 つの部分に分割して公開します。この記事は最初の記事で、主に AI x 暗号のコアフレームワーク、具体例、ビルダー向けの機会などについて説明します。翻訳の全文をご覧になりたい場合は、ここをクリックしてくださいリンク。
1. はじめに
人工知能(AI)は、これまでにない社会変化を引き起こします。
AI が急速に進歩し、あらゆる階層に新たな可能性を生み出すにつれ、必然的に広範な経済的混乱を引き起こすことになります。暗号通貨業界も例外ではありません。 2024 年の第 1 週に 3 つの大規模な DeFi 攻撃が観測され、760 億ドルの DeFi プロトコルが危険にさらされています。 AI を活用することで、スマート コントラクトのセキュリティ脆弱性をチェックし、AI ベースのセキュリティ層をブロックチェーンに統合できます。
AI の限界は、悪意のあるディープフェイクの蔓延によって証明されているように、悪意のある者が強力なモデルを悪用できることです。ありがたいことに、暗号化におけるさまざまな進歩により、AI モデルに新しい機能が導入され、いくつかの深刻な欠点に対処しながら、AI 業界が大幅に豊かになります。
AI と暗号通貨 (Crypto) の融合により、無数の注目すべきプロジェクトが生み出されるでしょう。これらのプロジェクトの中には、上記の問題の解決策を提供するものもありますが、表面的な方法で AI と暗号を組み合わせるものもありますが、実質的なメリットはありません。
このレポートでは、この分野の過去、現在、未来を理解するのに役立つ概念的な枠組み、具体的な例、洞察を紹介します。

2. AI×暗号のコアフレームワーク
このセクションでは、AI x 暗号プロジェクトをより詳細に分析するのに役立ついくつかの実用的なツールを紹介します。
2.1 AI(人工知能技術)×Crypto(暗号化技術)プロジェクトとは?
仮想通貨と AI の両方を使用したプロジェクトの例をいくつか確認し、それが本当に AI x 仮想通貨プロジェクトであるかどうかを議論しましょう。

この事例は、暗号化手法を使用して AI のトレーニング方法を変えることによって、暗号化が AI 製品にどのように役立ち、改善できるかを示しています。その結果、AI技術だけでは実現不可能だった、暗号命令を受け付けるモデルが誕生しました。
図 1: 暗号化を使用して AI スタックに内部変更を加えると、新しい機能が得られる可能性があります。たとえば、FHE を使用すると、暗号化命令を使用できます。

この場合、AI テクノロジーは暗号商品を改善するために使用されます。これは、先ほど説明したこととは逆です。 Dorsa は、安全なスマート コントラクトを作成するプロセスをより迅速かつ安価にする AI モデルを提供します。オフチェーンではありますが、AI モデルの使用は依然として暗号プロジェクトに役立ちます。多くの場合、スマート コントラクトは暗号プロジェクト ソリューションの中核となります。
Dorsa の AI 機能は、人間がチェックし忘れた脆弱性を発見することで、将来のハッキングを防ぐことができます。ただし、この特定の例では、AI を活用して、以前はできなかったこと、つまり安全なスマート コントラクトを作成する機能を暗号通貨製品に提供するわけではありません。 Dorsa の AI はプロセスをより良く、より速くします。ただし、これは AI テクノロジー (モデル) が暗号商品 (スマート コントラクト) を改善する例です。

LoverGPT は Crypto x AI の例ではありません。私たちは、AI が暗号スタックの改善に役立ち、またその逆も可能であることを確立しました。これは、Privasea と Dorsa の例で示されています。ただし、LoverGPTの場合、暗号化部分とAI部分は相互作用せず、製品内に共存しているだけです。プロジェクトが AI x 暗号プロジェクトとみなされるには、AI と暗号が同じ製品またはソリューションに貢献するだけでは十分ではありません。ソリューションを生み出すには、これらのテクノロジーが絡み合う必要があります。

暗号と AI は、より良いソリューションを生み出すために直接組み合わせることができるテクノロジーです。これらを一緒に使用すると、プロジェクト全体で相互の作業が向上します。これらのテクノロジー間の相乗効果を伴うプロジェクトのみが、AI X 暗号プロジェクトとして分類されます。
2.2 AI と暗号通貨がどのように相互に促進し合うのか

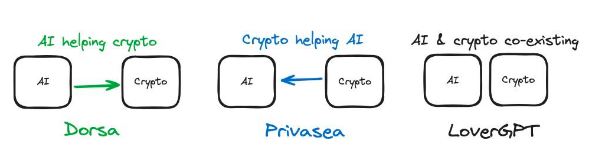
図 2: AI と暗号通貨が 3 つの異なる製品でどのように組み合わされるか
前回のケーススタディを振り返ってみましょう。 Privasea では、FHE (暗号化) を使用して、暗号化された入力を受け入れることができる AI モデルを生成します。そこで私たちは Crypto ソリューションを使用して AI のトレーニング プロセスを改善し、Crypto が AI を支援しています。 Dorsa では、AI モデルを使用してスマート コントラクトのセキュリティをレビューします。 AI ソリューションは暗号商品を改善するために使用されるため、AI は暗号通貨を支援します。これは、AI でプロジェクトを評価する際の重要な側面をもたらします。
この単純な質問は、現在のユースケースの重要な側面、つまり、解決すべき重要な問題は何なのかを発見するのに役立ちます。 Dorsa の場合、望ましい結果は安全なスマート コントラクトです。これは熟練した開発者が行うことができ、Dorsa はたまたま AI を活用してこのプロセスをより効率的にしています。ただし、基本的にはスマート コントラクトのセキュリティのみを考慮しています。重要な疑問が明確になれば、AI が Crypto を助けているのか、それとも Crypto が AI を助けているのかを判断できるようになります。場合によっては、この 2 つの間に意味のある対話が存在しないことがあります (例: LoverGPT)。
以下の表に、各カテゴリの例をいくつか示します。
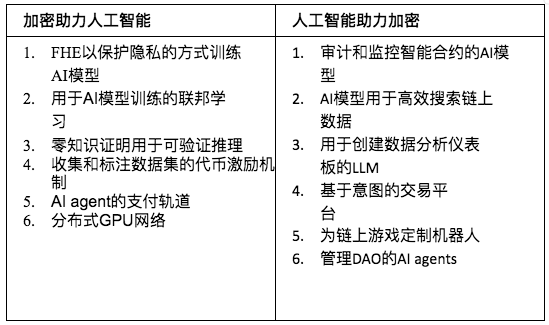
表 1: 暗号と AI がどのように組み合わされるか
付録には 150 以上の AI x Crypto プロジェクト ディレクトリがあります。何か見逃している場合、またはフィードバックがある場合は、お気軽にお問い合わせください。接続する私たち!
2.2.1 概要
AI と暗号はどちらも、その目標を達成するために別のテクノロジーをサポートする機能を備えています。プロジェクトを評価する際に重要なのは、その中核が AI 製品なのか暗号製品なのかを理解することです。
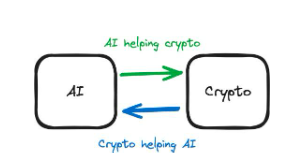
図 3: 違いの説明
2.3 社内および社外のサポート
暗号通貨が AI を支援する例を見てみましょう。 AI を構成する特定のテクノロジーのセットが変化すると、AI ソリューション全体の機能も変化します。このテクノロジーの集合体はスタックと呼ばれます。 AI スタックには、AI のあらゆる側面を構成する数学的アイデアとアルゴリズムが含まれています。トレーニング データの処理、モデルのトレーニング、モデルの推論に使用される特定のテクニックはすべてスタックの一部です。

スタックでは、さまざまな部分の間に深いつながりがあり、特定のテクノロジーをどのように組み合わせるかによってスタックの機能が決まります。したがって、スタックを変更することは、テクノロジー全体で達成できることを変更することと同じです。スタックに新しいテクノロジーを導入すると、新しい技術の可能性が生まれます。イーサリアムは、スマート コントラクトを可能にするために、暗号スタックに新しいテクノロジーを追加しました。同様に、スタックへの変更により、開発者は、これまでテクノロジーに固有であると考えられていた問題を回避することもできます。Polygon がイーサリアム暗号スタックに加えた変更により、以前は不可能と考えられていたレベルまで取引手数料を削減することができました。

内部サポート:未確認動物学を使用すると、モデルをトレーニングする技術的手段を変更するなど、AI スタックに内部変更を加えることができます。 FHE テクノロジーを人工知能スタックに導入することができます。Privasea はその一例で、暗号化部分が AI スタックに直接組み込まれ、修正された AI スタックを形成します。
外部サポート:暗号は、AI スタックを変更することなく AI ベースの機能をサポートするために使用されます。Bittensorはその一例で、ユーザーがデータ (AI モデルのトレーニングに使用できるデータ) を提供するよう奨励します。この場合、モデルのトレーニング方法や使用方法は何も変わりません。AI スタックも何も変わりません。ただし、Bittensor ネットワークでは、経済的インセンティブの使用により、AI スタックがその目的をより適切に達成することができます。
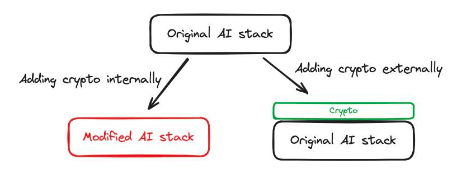
図 4: 前の議論の図
同様に、AI は Crypto に内部または外部のヘルプを提供することもできます。
内部サポート:AI テクノロジーは暗号スタック内で使用されます。 AI はオンチェーンにあり、暗号スタックの一部に直接接続されています。たとえば、チェーン上の AI エージェントが DAO を管理します。この AI は暗号スタックを支援するだけではありません。これはテクノロジー スタックの不可欠な部分であり、DAO が適切に機能できるようにテクノロジー スタックに深く組み込まれています。
外部サポート:AI は暗号スタックの外部サポートを提供します。 AI は、内部に変更を加えずに暗号スタックをサポートするために使用されます。 Dorsa のようなプラットフォームは AI モデルを使用してスマート コントラクトを保護します。 AI はオフチェーンであり、安全なスマート コントラクトを作成するプロセスをより速く、より安価にするために使用される外部ツールです。
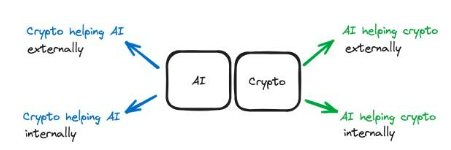
図 5: これは、内部サポートと外部サポートの違いを含むアップグレードされたモデルです。
AI x 暗号プロジェクトを分析する最初の段階は、それがどのカテゴリに分類されるかを判断することです。
2.4 ボトルネックの特定
外部サポートと比較して、深い技術統合を特徴とする内部サポートには、多くの場合、より多くの技術的問題があります。たとえば、FHE やゼロ知識証明 (ZKP) を導入して AI スタックを変更したい場合、暗号と AI の両方についてかなりの専門知識を持つ技術者が必要になります。しかし、この交差点に落ちる人はほとんどいません。これらの企業には以下が含まれますModulus、EZKL、ZamaそしてPrivasea。
結果として、これらの企業はソリューションを推進するために多大な資本と希少な人材を必要としています。ユーザーが人工知能をスマート コントラクトに統合できるようにするには、深い知識も必要です。RitualそしてOraこのような企業は、複雑なエンジニアリング問題を解決する必要があります。
逆に、外部サポートにもボトルネックがありますが、通常はそれほど技術的な複雑さは伴いません。たとえば、暗号通貨の支払い機能を AI エージェントに追加する場合、モデルを大幅に変更する必要はありません。実装は比較的簡単です。 AI エンジニアにとっては、DeFi LLamaからChatGPTを作成するChatGPTプラグインウェブページ上で統計の取得技術的には複雑ではありませんが、暗号通貨コミュニティのメンバーである AI エンジニアはほとんどいません。このタスクは技術的に複雑ではありませんが、これらのツールにアクセスできる AI エンジニアはほとんどおらず、多くはその可能性に気づいていません。
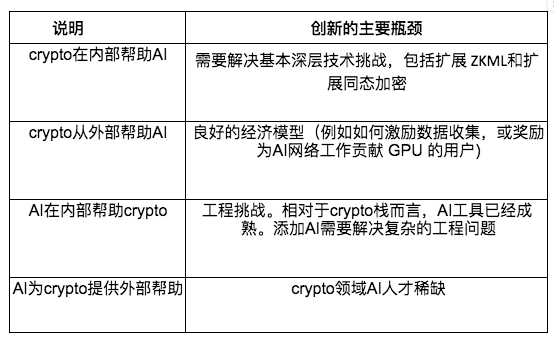
2.5 測定ユーティリティ
4 つのカテゴリーすべてに優れたプロジェクトがあるでしょう。
AI が暗号スタックに統合されれば、スマート コントラクトの開発者はオンチェーン AI モデルにアクセスできるようになり、可能性の数が増え、広範なイノベーションにつながる可能性があります。暗号通貨を AI スタックに統合する場合も同様で、深いテクノロジーの融合により新たな可能性が生まれます。
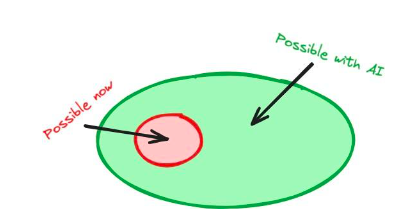
図 6: 暗号スタックに人工知能を追加すると、開発者に新しい機能が提供される
AI が暗号通貨に外部からの助けを提供する限り、AI の統合は既存の製品を改善する一方で、ブレークスルーや導入の可能性は少なくなる可能性があります。たとえば、人工知能モデルを使用してスマート コントラクトを作成すると、以前よりも高速かつ安価になる可能性があり、セキュリティも向上する可能性がありますが、以前は不可能だったスマート コントラクトが作成される可能性は低いです。同じことが外部から AI を支援する暗号通貨にも当てはまります。トークン インセンティブは AI スタックに使用できますが、それだけでは AI モデルのトレーニング方法を再定義する可能性は低いです。
要約すると、あるテクノロジーを別のテクノロジー スタックに統合すると新しい機能が得られる可能性があり、一方、テクノロジー スタック外のテクノロジーを使用すると使いやすさと効率が向上する可能性があります。
2.6 評価プロジェクト
テクノロジー間の内部サポートはより大きな利益につながる可能性があるため、特定のプロジェクトが該当する象限に基づいてその利益の一部を見積もることができますが、プロジェクトのリスク調整後の利益の合計を見積もるには、より多くの要因とリスクを考慮する必要があります。
考慮すべき要素の 1 つは、検討中のプロジェクトが Web2、Web3、またはその両方のコンテキストで役立つかどうかです。 FHE 機能を備えた AI モデルは、FHE 機能のない AI モデルを置き換えるために使用できます。FHE 機能の導入は両方の分野で役立ち、いずれの場合でもプライバシーは貴重です。ただし、人工知能モデルのスマート コントラクトへの統合は、Web3 環境でのみ使用できます。
前述したように、人工知能と暗号化分野の間の技術統合が内部で行われるか外部で行われるかによって、プロジェクトの向上の可能性も決まります。内部サポートを伴うプロジェクトは新しい機能を生み出し、効率性を大幅に向上させる傾向にありますが、これはより価値があります。
また、このテクノロジーが成熟するまでの期間も考慮する必要があり、それによって人々が恩恵を享受するまでにどれくらいの期間待つ必要があるかが決まります。
プロジェクトへの投資。これは、現在の進捗状況を分析し、プロジェクト関連のボトルネックを特定することで実行できます (セクション 2.4 を参照)。
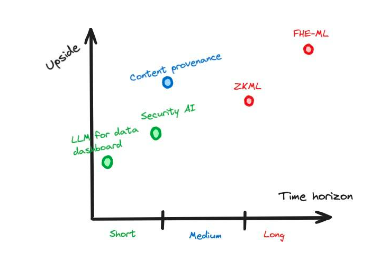
図 7: タイムスパンと比較した潜在的な上振れを示す仮想的な例
2.7 複雑な製品を理解する
一部のプロジェクトには、ここで説明した 4 つのカテゴリが 1 つだけではなく、組み合わせて含まれています。この場合、プロジェクトに関連するリスクと利益は倍増する傾向があり、プロジェクトの実施期間は長くなる傾向があります。
さらに、プロジェクト全体が各部分の合計よりも優れているかどうかを考慮する必要があります。すべてが少しずつ含まれているプロジェクトでは、多くの場合、エンド ユーザーのニーズを満たすのに十分ではありません。焦点を絞ったアプローチにより、多くの場合、優れた製品が生まれます。

2.7.1 例 1: Flock.io
Flock.io複数のサーバー間で許可"セグメンテーション"モデルをトレーニングするために、すべてのトレーニング データにアクセスできる当事者はいません。モデルのトレーニングに直接参加できるため、データを漏らすことなく、自分のデータを使用してモデルに貢献できます。これはユーザーのプライバシーを保護するのに役立ちます。 AI スタック (モデル トレーニング) が変化すると、AI を内部的に支援する暗号化が必要になります。
さらに、暗号トークンを使用してモデルのトレーニングに関与する人々に報酬を与え、スマート コントラクトを使用してトレーニング プロセスを妨害する人々に金銭的なペナルティを課します。これはモデルのトレーニングに含まれるプロセスを変更するものではなく、基盤となるテクノロジーは変更されませんが、すべての関係者がオンチェーン スラッシュ メカニズムに従う必要があります。これは、暗号が AI を外部から支援する例です。
最も重要なことは、暗号化は AI に新しい機能を導入するのに内部的に役立ちます。つまり、データをプライベートに保ちながら、分散ネットワーク上でモデルをトレーニングできます。ただし、トークンは単にユーザーにネットワークへの貢献を奨励するために使用されるため、外部から AI を支援する暗号通貨は新しい機能を導入しません。ユーザーは法定通貨で報酬を受けることができ、暗号通貨のインセンティブを使用することはシステムの効率を向上させるより良いソリューションですが、新しい機能は導入されません。
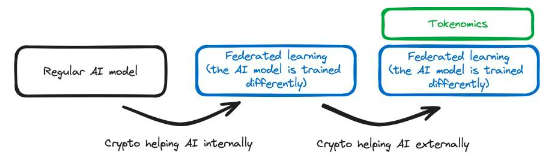
図 8:Flock.ioスタックとスタック内の変更の概略図。色の変化は内部で変更が発生したことを意味します。
2.7.2 例 2: ロックフェラー ロボット
ロックフェラーロボットチェーン上で動作するトレーディングロボットです。どの取引を行うかを決定するために AI を使用しますが、AI モデル自体はスマート コントラクト上で実行されないため、サービス プロバイダーに頼ってモデルを実行し、AI の決定をスマート コントラクトに伝えて証明します。それらをスマートコントラクトに結び付けます 嘘はありません。スマートコントラクトがサービスプロバイダーが嘘をついていないかどうかをチェックしない場合、サービスプロバイダーが当社に代わって有害な取引を行う可能性があります。 Rockefeller Bot を使用すると、ZK 証明を使用して、サービス プロバイダーが嘘をついていないことをスマート コントラクトに証明できます。ここではZKを利用してAIスタックを変更します。 AI スタックは ZK テクノロジーを採用する必要があります。そうしないと、スマート コントラクトに関するモデルの決定を証明するために ZK を使用できません。
ZK テクノロジーのおかげで、結果として得られる AI モデルの出力は検証可能であり、ブロックチェーンからクエリすることができます。これは、AI モデルが暗号スタック内で使用されることを意味します。この場合、スマートコントラクトで人工知能モデルを使用して、公正な方法で取引と価格を決定します。これは人工知能なしでは不可能です。
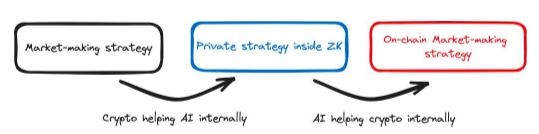
図 9: ロックフェラー ロボットとスタックの変更の概略図。色の変化はスタック (内部的にサポートされている) が変化したことを意味します
3. さらに調査する価値のある疑問
3.1 暗号化分野とディープフェイクの黙示録

1月23日 1日AIが生成した音声メッセージがバイデン大統領だと偽る、民主党が2024年の予備選で投票するのを思いとどまらせる。それから一週間も経たないうちに、金融関係者同僚のディープフェイクビデオ通話を真似したことに対して。2,500万ドルの損失。一方、X(旧Twitter)では、AIがテイラー・スウィフトの露骨な写真を偽造した4,500万回の再生回数を記録、広範な怒りを引き起こしました。これらの事件はすべて 2024 年の最初の 2 か月に発生しましたが、ディープフェイクが政治、金融、ソーシャル メディアに及ぼしているさまざまな悪影響のほんの一部です。
3.1.1 どうして問題になったのですか?
偽の画像は何も新しいことではありません。 1917 年、ストランド誌は妖精のように見えるようにデザインされた複雑な切り抜き紙の写真を掲載しましたが、多くの人がその写真が超自然的な力の存在の証拠であると考えました。

図 10: 「コッティングリーの妖精」の写真の 1 枚。シャーロック・ホームズの作者サー・アーサー・コナン・ドイルは、超常現象の証拠として偽造画像を挙げた。
時間が経つにつれて、偽造はより簡単かつ低コストになり、誤った情報が拡散する速度が大幅に速くなりました。たとえば、2004 年の米国大統領選挙中に、民主党候補のジョン・ケリーが物議を醸した米国の活動家ジェーン・フォンダとともに抗議活動に参加していると偽って加工された写真が掲載されました。コッティングリーの妖精は、児童書からトレースした画像を厚紙に切り抜いて使用するなど、手の込んだ手配が必要でしたが、この偽造は Photoshop を使用して完了した簡単な作業でした。

図 11:これです写真は、ベトナム戦争反対集会でジェーン・フォンダとステージを共有するジョン・ケリーを示しています。その後、それはPhotoshopを使用して2つの既存の画像を組み合わせて作成された偽造写真であることが判明しました。
しかし、編集の兆候を見つける方法を学ぶにつれて、偽造写真によってもたらされるリスクは減少しました。存在する観光客の少年「この事件では、アマチュアは、シーン内のさまざまなオブジェクト間のホワイトバランスの不一致を観察することで、画像が編集されたかどうかを特定することができました。これは、偽情報に対する国民の意識が高まった結果であり、人々は画像編集の兆候に気づくようになりました。」 「Photoshoped」という言葉は一般的な用語になりました。画像が改ざんされた兆候は広く認識されるようになり、写真による証拠はもはや絶対確実とは考えられなくなりました。
3.1.1.1 ディープフォージリにより、偽造がより簡単、安価、より現実的になります
以前は、偽造文書は肉眼で簡単に検出できましたが、ディープフェイク技術により、本物の写真とほとんど見分けがつかない画像を簡単かつ安価に作成できるようになりました。たとえば、ウェブサイト OnlyFake はディープフェイク技術を使用して、わずか 15 ドルで本物のような偽の ID 写真を数分で生成します。これらの写真は、Know Your Customer として知られる暗号通貨取引所の不正防止策である OKX を回避するために使用されました。"(KYC)。 OKX の場合、これらのディープフェイク ID は、改ざんされた画像やディープフェイクを見分けるように訓練された従業員を騙しました。これは、ディープフェイクベースの詐欺はもはや、専門家であっても肉眼で検出することが不可能であることを浮き彫りにしています。
画像がディープフェイクされるにつれ、ビデオ証拠への依存が高まっていますが、ディープフェイクはすぐにビデオ証拠を大きく損なうでしょう。テキサス大学ダラス校の研究者が無料のディープフェイク顔交換ツールを使用、無事バイパスされましたKYC プロバイダーによって実装される本人確認機能。これは大きな改善です。以前は、高品質のビデオを生成するには費用と時間がかかりました。
2019 年には、これに 2 週間と 552 ドルかかりました。マーク・ザッカーバーグの38秒のディープフェイクビデオを作成する、ビデオには明らかな視覚的欠陥もあります。現在では、リアルなディープフェイク動画を無料で数分で作成できるようになりました。
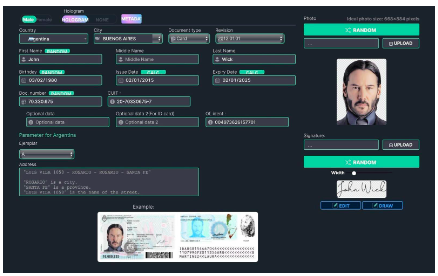
図 12: OnlyFake パネルは数分で偽の ID カードを作成できる
3.1.1.2 ビデオが非常に重要な理由
ディープフェイク技術が登場する前は、かつてはビデオが信頼できる証拠だった。簡単に偽造される画像とは異なり、ビデオは歴史的に偽造が困難であるため、法廷で信頼できる証拠として認識されています。このため、ビデオディープフェイクは特に危険です。
同時に、ディープフェイクの出現は本物の動画の否定にもつながる可能性があり、米国バイデン大統領の段落動画は誤ってディープフェイクと呼ばれています。批評家らは証拠としてバイデンの瞬きしない目と照明の違いを指摘したが、それらの主張は反証された。これは問題を引き起こします。「深層偽造」は、偽物を本物に見せるだけでなく、本物を偽物に見せ、現実とフィクションの境界線をさらに曖昧にし、責任をさらに難しくします。

ディープフェイクにより、ターゲットを絞った大規模な広告が可能になります。何を、誰が、どこで話すかが視聴者に合わせてパーソナライズされた別の YouTube が間もなく登場するかもしれません。初期の例は次のとおりですZomato のローカライズされた広告, この広告では、俳優のリティク・ロシャンが視聴者の街の人気レストランから料理を注文する様子が描かれています。 Zomato は、視聴者のさまざまな GPS 位置に基づいてさまざまなディープフェイク広告を生成し、視聴者の位置にあるレストランに関するコンテンツを紹介しました。
3.1.2 現在のソリューションの欠点は何ですか?
3.1.2.1 意識
今日のディープフェイクは、訓練を受けた専門家さえ騙せるほど高度です。これにより、ハッカーは本人確認 (KYC/AML) 手順や人間による審査さえも回避することができます。これは、私たちの目ではディープフェイクと本物の画像を区別できないことを示しています。画像を疑うだけではディープフェイクを防ぐことはできません。ディープフェイクの蔓延に対抗するには、より多くのツールが必要です。
3.1.2.2 プラットフォーム
ソーシャルメディアプラットフォームは、強い社会的圧力がなければディープフェイクを効果的に抑制しようとはしない。たとえば、Meta は偽の音声を含む偽ビデオを禁止していますが、純粋に捏造されたビデオ コンテンツの禁止は拒否しています。彼らは自らの監視委員会の勧告に反し、ある段落を削除しなかった孫娘を愛撫するバイデン大統領ディープフェイク動画、純粋に捏造されたコンテンツ。
3.1.2.3 ポリシー
芸術や教育など、人々をだますことを目的としない、問題の少ない用途を制限することなく、ディープフェイクの新たなリスクに効果的に対処する法律が必要です。テイラー・スウィフトのディープフェイク画像の同意のない配布などの事件を受けて、議員らはこうしたディープフェイクに対抗するためのより厳格な法律の可決を促している。このような事例に対応するには、法的に厳格化されたオンラインモデレーション手順が必要になる可能性があるが、AIが生成したすべてのコンテンツを禁止するという提案は、それが自分たちの作品を不当に制限することになるのではないかと懸念する映画制作者やデジタルアーティストに警戒を与えている。適切なバランスを見つけることが重要です。そうしないと、正当なクリエイティブなアプリケーションが抑圧されてしまいます。
強力なモデルをトレーニングするための参入障壁を高めるよう議員らに圧力をかけることで、ビッグテックはAIの独占を確保できるだろう。これは、たとえば人工知能に関して、少数の企業の手に不可逆的な権力の集中を引き起こす可能性があります。大統領令 14110大量のコンピューティング能力を持つ企業には厳しい要件を課すことをお勧めします。

図 13: ジョー・バイデン米国大統領が人工知能に関する初の米国大統領令に署名したとき、カマラ・ハリス米国副大統領が拍手を送る
3.1.2.4 テクノロジー
AI モデルにガードレールを直接構築して悪用を防ぐことが防御の第一線ですが、これらのガードレールは絶えず破壊され続けている。既存の低レベル ツールを使用して高次元の動作を変更する方法がわからないため、AI モデルをレビューするのは困難です。さらに、AI モデルをトレーニングする企業は、実装のガードレールを口実にして、モデルに望ましくない監視や偏見を導入する可能性があります。これは、大手テクノロジー AI 企業が国民の意思に対して責任を負っておらず、企業がユーザーに不利益をもたらすようモデルに自由に影響を与えることができるため、問題となります。
たとえ強力な AI の開発が不正な企業の手に集中していなかったとしても、安全で偏りのない AI を構築することは依然として不可能である可能性があります。研究者にとっては判断が難しい虐待とは何か、したがって、乱用を防止しながら、中立的かつバランスの取れた方法でユーザーのリクエストを処理することは困難です。虐待を定義できない場合は、予防措置の厳格さを緩和する必要があると思われ、虐待が再び発生する可能性があります。したがって、人工知能モデルの悪用を完全に禁止することは不可能です。
解決策の 1 つは、悪意のあるディープフェイクの作成を阻止するのではなく、出現したらすぐに検出することです。ただし、OpenAI によって展開されるようなディープフェイク検出 AI モデル不正確さのため、となっています時代遅れ。ディープフェイクの検出方法はますます洗練されていますが、ディープフェイクの作成に使用されるテクノロジーはさらに速い速度で洗練されており、ディープフェイク検出器は技術軍拡競争で負けつつあります。このため、メディアのみに基づいてディープフェイク ニュースを特定することが困難になります。人工知能は、AI がその精度を判断できないほどリアルなフェイク映像を作成できるほど進歩しています。
透かし技術はディープフェイクに慎重にマークを付けるため、どこに表示されても識別できるようになります。ただし、透かしは意図的に追加する必要があるため、ディープフェイクには必ずしも透かしが含まれているわけではありません。 OpenAI など、偽の画像にラベルを付けることで自発的に差別化を図っている企業にとって、透かしは効果的な方法です。でも何はともあれ、透かしは大丈夫です使いやすいツールで削除または偽造、これにより、透かしベースのディープフェイク対策ソリューションがバイパスされます。ほとんどのソーシャル メディア プラットフォームと同様に、ウォーターマークも誤って削除される可能性があります。自動的に削除透かし。
最も人気のあるディープフェイク透かし技術は次のとおりです。C 2 PA (Content Provenance and Authenticity Alliance によって提案)。メディア ソースを追跡し、この情報をメディア メタデータに保存することで、誤った情報を防ぐように設計されています。このテクノロジーは Microsoft、Google、Adobe などによって支援されているため、C 2 PA はコンテンツ サプライ チェーン全体に展開される可能性が高く、他の同様のテクノロジーよりも人気が高くなります。
残念ながら、C 2 PA には独自の弱点があります。 C 2 PA は画像の完全な編集履歴を保存し、C 2 PA 準拠の編集ソフトウェアによって制御される暗号化キーを使用して各編集を検証するため、これらの編集ソフトウェアを信頼する必要があります。ただし、人々は、編集チェーン内の各当事者を信頼するかどうかを考慮せずに、有効な C 2 PA メタデータを理由に編集された画像を単純に受け入れる可能性があります。したがって、編集ソフトウェアが侵害されたり、悪意のある編集が可能になったりすると、偽の画像または悪意を持って編集された画像が本物であると他人に信じ込ませる可能性があります。

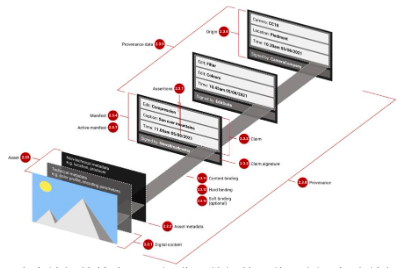
図 14: C2PA 標準メタデータに準拠した一連の編集を含む画像の例。各編集は異なる信頼できる当事者によって署名されますが、最終的に編集された画像のみが公開されます。出典: 本物の写真と AI が生成したアート:新規格(C 2 PA)はPKIを利用して画像履歴を表示
さらに、C 2 PA ウォーターマークに含まれる暗号署名とメタデータ特定のユーザーまたはデバイスに関連付けることができます。場合によっては、C 2 PA メタデータは、カメラで撮影されたすべての画像を相互に結び付けることができます。特定の画像が誰かのカメラからのものであることがわかっている場合、そのカメラからの他のすべての画像を識別できます。これにより、記者が写真を投稿する際に匿名性を保つことができます。
考えられるすべてのソリューションは、特有の一連の課題に直面することになります。これらの課題は多岐にわたりますが、社会的認識の限界、大手テクノロジー企業の欠点、規制政策の実施の難しさ、テクノロジーの限界などがあります。

3.1.3 暗号化の分野はこの問題を解決できるでしょうか?
オープンソースのディープフェイクモデルが出回り始めています。したがって、ディープフェイクを使用して他人の肖像を悪用する方法は常に存在し、たとえその行為が犯罪化されたとしても、非倫理的なディープフェイク コンテンツを生成することを選択する人はいるだろうと主張する人もいるかもしれません。ただし、悪意のあるディープフェイクを主流から排除することで、この問題を解決できます。人々がディープフェイク画像を本物だと思うことを防ぎ、ディープフェイク コンテンツを制限するプラットフォームを作成できます。このセクションでは、悪意のあるディープフェイクの伝播によって引き起こされるミスディレクションの問題に対するさまざまな暗号ベースのソリューションを紹介し、各アプローチの限界を強調します。
3.1.3.1 ハードウェア認証
ハードウェア認定カメラには、撮影した各写真に固有の証明書が埋め込まれており、その写真がそのカメラで撮影されたものであることを証明します。この証明書は、カメラ独自の複製不可能な改ざん防止チップによって生成され、画像の信頼性が保証されます。同様のプログラムがオーディオとビデオでも利用できます。

証明書は、画像が本物のカメラで撮影されたものであることを示します。つまり、一般に、それが本物の物体の写真であると信頼できることになります。そのような証拠がなくても画像にラベルを付けることができます。ただし、カメラが本物のように見えるように設計された偽のシーンをキャプチャした場合、この方法は機能しません。偽の画像にカメラを向けるだけで済みます。現在、撮影した画像が歪んでいるかどうかをチェックすることで、写真がデジタル画面から撮影されたものであるかどうかを知ることができますが、詐欺師はこれらの欠陥を隠す方法を見つけるでしょう(たとえば、より優れた画面を使用するか、レンズフレアを制限するなど)。結局のところ、人工知能ツール詐欺師はこれらすべての歪みを回避する方法を見つけることができるため、この詐欺を検出することも不可能です。
ハードウェア認証により、偽の画像が信頼されるケースは減りますが、まれに、カメラが侵害されたり悪用されたりした場合に、ディープフェイク画像の拡散を防ぐために追加のツールが必要になる場合があります。以前に説明したように、ハードウェア検証済みのカメラを使用しても、カメラがハッキングされている場合や、コンピューター画面上のディープフェイク シーンをキャプチャするためにカメラが使用されている場合など、ディープフェイク コンテンツが本物の画像であるという誤った印象を与える可能性があります。この問題を解決するには、カメラのブラックリストなどの他のツールが必要です。
カメラのブラックリストを使用すると、特定のカメラが過去に誤解を招く画像を生成したことが知られているため、ソーシャル メディア プラットフォームやアプリが特定のカメラからの画像にフラグを立てることができます。ブラックリストにより、カメラ ID など、カメラの追跡に使用できる情報を公開する必要がなくなります。
ただし、カメラのブラックリストを誰が管理しているのかは不明です。いいえ内部告発者のカメラをブラックリストに登録するために人々が賄賂を受け取らないようにする方法を知ってください。
3.1.3.2 ブロックチェーンベースの画像年表
ブロックチェーンは不変であるため、画像がインターネット上に公開されると、タイムスタンプとメタデータが改ざんできないように、追加のメタデータとともにタイムスタンプ付きの年表に追加されます。悪意のある編集が広まる前に、正直な当事者によって編集されていないオリジナルの画像をブロックチェーン上に不変に保存できるため、そのような記録にアクセスすることで悪意のある編集を特定し、元のソースを確認することができます。このテクノロジーは、Fox Newsと提携して開発されたファクトチェックツールとしてPolygonブロックチェーンネットワークに実装されました。Verifyの一部。

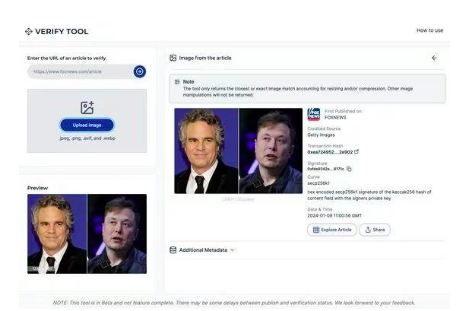
図 15: Fox のブロックチェーンベースのツール Verify のユーザー インターフェイス。作品はURLからご覧いただけます。 Polygon ブロックチェーンから来歴、トランザクション ハッシュ、署名、タイムスタンプ、その他のメタデータを取得して表示します
3.1.3.3 デジタルアイデンティティ
ディープフェイクが未検証の画像やビデオに対する私たちの信頼を損なう場合、信頼できる情報源が偽情報を避ける唯一の方法になる可能性があります。情報の正確性と信頼性を確保するためにジャーナリズムの基準、事実確認手順、および編集上の監督が採用されているため、当社は信頼できるメディアソースに情報の検証を依存してきました。
ただし、オンラインで見るコンテンツが信頼できる情報源からのものであることを確認する方法が必要です。ここで、暗号署名されたデータが登場します。データは、何かの作成者を数学的に証明できます。
署名はデジタルキーを使用して生成され、キーはウォレットによって作成および生成されるため、問題の暗号化ウォレットの所有者のみが知ります。このようにして、署名が個人の暗号ウォレット内の私たちに固有のキーに対応するかどうかを確認するだけで、データの作成者が誰であるかを知ることができます。
暗号通貨ウォレットを活用して、シームレスかつユーザーフレンドリーな方法で投稿に署名を添付できます。仮想通貨ウォレットを使用してソーシャル メディア プラットフォームにログインする場合、ウォレットの機能を利用してソーシャル メディア上で署名を作成および検証できます。そのため、プラットフォームは投稿が疑わしいソースからのものである場合に警告できるようになり、自動署名検証を使用して誤った情報にフラグを立てます。
さらに、ウォレットに接続されたzk-KYCこのインフラストラクチャは、ユーザーのプライバシーと匿名性を損なうことなく、未知のウォレットを KYC プロセスを通じて検証された ID に結び付けることができます。しかし、ディープフェイクがより洗練されると、KYC プロセスがバイパスされ、悪意のある攻撃者が偽の匿名 ID を作成できるようになる可能性があります。この質問には、Worldcoin が答えます。個人の身元を証明するもの"(PoP)解決策が見つかるまで待ちます。
個人識別は、WorldCoin がそのウォレットが本物の人物に属していることを確認するために使用するメカニズムであり、1 人につき 1 つのウォレットのみが許可されます。これを行うために、生体認証 (虹彩) イメージング デバイスを使用します。Orbウォレットを確認するため。生体認証データはまだ偽造できないため、ソーシャル メディア アカウントを独自の WorldCoin ウォレットにリンクすることを要求することは、悪意のある者がオンラインでの悪質な行為を隠すために複数の匿名の ID を作成することを防ぐための実行可能な方法です (少なくともハッカーから)。なりすまし生体認証デバイスを使用すれば、ディープフェイク KYC の問題を解決できる可能性があります。
3.1.3.4 経済的インセンティブ

著者は誤った情報に対して処罰される可能性があり、ユーザーは誤った情報を特定した場合に報酬を得ることができます。例えば、"信頼性の絆"(Veracity Bonds) により、報道機関は出版物の正確さを賭けて、誤った情報に対して金銭的な罰金を科せられるようになります。これにより、これらのメディア企業は情報の信頼性を確保するための経済的理由が得られます。
真正性の保証は、"真実の市場"この市場に不可欠な要素であるさまざまなシステムは、最も効率的かつ堅牢な方法でコンテンツの信頼性を検証することでユーザーの信頼を競い合います。これは、次のようなプルーフ マーケットと同様です。Succinct Networkそして=nil Proof Marketただし、真正性の検証というより困難な問題が発生します。
暗号化だけでは十分ではありません。スマートコントラクトは、これらの「真実の市場」を機能させるために必要な経済的インセンティブを強制する手段として機能するため、ブロックチェーンテクノロジーは偽情報と戦う上で中心的な役割を果たす可能性があります。
3.1.3.5 評判スコア

評判を使用して信頼性を表すことができます。たとえば、Twitter でその人のフォロワーが何人いるかを調べて、その人の発言を信じるべきかどうかを判断できます。ただし、評判システムでは、各著者の人気だけではなく、実績も考慮する必要があります。信頼性と人気を混同したくないのです。
匿名のアイデンティティを無制限に生成することを許可することはできません。そうしないと、評判が傷ついたときに、社会的信用をリセットするためにアイデンティティを放棄することができます。前のセクションで説明したように、これにはコピーできないデジタル ID を使用する必要があります。
私たちも使うことができます"真実の市場"そして"ハードウェア認証"これらは、個人の真実の記録を追跡する信頼できる方法であるため、個人の評判を決定するための証拠となります。レピュテーション システムは、これまで説明した他のすべてのソリューションの集大成であるため、最も強力で包括的なアプローチのファミリーです。

図16: マスク氏は、雑誌記事、編集者、出版物の信頼性スコアを提供するウェブサイトを2018年に開設することを示唆した。
3.1.4 暗号化ソリューションは拡張可能ですか?
上記のブロックチェーン ソリューションには高速で大容量のブロックチェーンが必要です。そうでないと、すべての画像をオンチェーンの検証可能な時間記録に組み込むことができなくなります。毎日オンラインで公開されるデータの量が飛躍的に増加するにつれて、この重要性はますます高まっています。ただし、いくつかあります。アルゴリズムは次のことができますまだ検証可能な方法でデータを圧縮します。
さらに、ハードウェア認証によって生成された署名は、画像の編集されたバージョンでは機能しません。編集の証明は、zk-SNARK を使用して生成する必要があります。ZK Microphoneオーディオ用のエディタープルーフの実装です。 4
3.1.5 ディープフェイクは本質的に悪いものではない
すべてのディープフェイクが有害であるわけではないことを認めることが重要です。このテクノロジーには、次のような無害な用途もありますテイラー・スウィフトが数学を教える AI 生成のビデオ。ディープフェイクは低コストでアクセスしやすいため、パーソナライズされたエクスペリエンスが作成されます。例えば、HeyGenユーザーを許可するAI が生成した自分の顔を使って個人的なメッセージを送信します。ディープなシミュレーションは吹き替えでも翻訳可能言語のギャップを埋める。

3.1.5.1 ディープフェイクを制御し収益化する方法
ディープフェイク技術に基づく AI 対応サービスは高額な料金を請求し、説明責任や監視が不足しています。 OnlyFans のトップインフルエンサーである Amouranth は、ファンが彼女とプライベートにチャットできるように、自分のデジタルアバターを投稿しました。これらのスタートアップはアクセスを制限したり、さらには閉鎖したりする可能性があります。AIコンパニオンサービス「Soulmate」。
AI モデルをオンチェーンでホストすることで、スマート コントラクトを使用して透明な方法でモデルに資金を提供し、制御することができます。これにより、ユーザーがモデルにアクセスできなくなることがなくなり、モデル作成者が貢献者や投資家に利益を分配できるようになります。ただし、技術的な課題もあります。オンチェーン モデルを実装するための最も一般的なテクノロジである zkML (Giza、Modulus Labs、EZKL で使用) によりモデルが実行されます。1000倍遅い。それにもかかわらず、このサブ分野の研究は続けられ、技術は向上し続けています。例えば、HyperOracle使用しようとしていますopML,Aizelソリューションは、マルチパーティ コンピューテーション (MPC) と信頼された実行環境 (TEE) に基づいて構築されています。
3.1.6 章の概要
洗練されたディープフェイクが政治、金融、ソーシャルメディアに対する信頼を損なっていることが浮き彫りになっています。"検証可能なネットワーク"真実と民主主義の完全性の必要性を維持するため。
ディープフェイクはかつては費用がかかり、技術集約的な取り組みでしたが、人工知能の進歩により簡単に作成できるようになり、偽情報の状況が変わりました。
4 この問題に興味がある場合は、お問い合わせください。アルビオン。
歴史を振り返ると、メディアの操作は新しい課題ではありませんが、人工知能のおかげで説得力のあるフェイクニュースをより簡単に、より安価に作成できるようになったため、新しいソリューションが必要とされています。
ビデオ詐欺は、これまで信頼できると考えられていた証拠を侵害し、本物の行為が偽物として偽装される可能性があるというジレンマに社会を導くため、独特の危険をもたらします。
既存の対策は認識、プラットフォーム、ポリシー、テクノロジーのアプローチに分かれており、それぞれがディープフェイクに効果的に対抗する上で課題に直面しています。
ハードウェアプルーフとブロックチェーンは、各画像の出所を証明し、透明で不変の編集記録を作成することで、有望なソリューションを提供します。
暗号通貨ウォレットと zk-KYC は、オンライン コンテンツの検証と認証を強化する一方で、オンチェーンの評判システムと経済的インセンティブを強化します。"信頼性の絆")真実の市場を提供します。
Crypto は、ディープフェイクの積極的な使用を認めながら、有益なディープフェイクをホワイトリストに登録する方法も提案しており、これによりイノベーションと完全性のバランスを取ることができます。
3.2 苦い教訓

この発言は直観に反しますが、これは真実です。 AI コミュニティは、カスタマイズされたアプローチは効果が低いという考えを否定していますが、"苦い教訓"これも当てはまります。最大限のコンピューティング能力を使用すると、常に最良の結果が得られます。
より多くの GPU、より多くのデータセンター、より多くのトレーニング データを拡張する必要があります。
コンピュータチェスの研究者は、人間のトッププレイヤーの経験を利用してチェスエンジンを構築しようとしましたが、これは研究者が間違った例です。最初のチェス プログラムは人間のオープニング戦略をコピーしました ("開く本")。研究者らは、チェス エンジンが最良の手を最初から計算することなく、強い局面からスタートできるようにしたいと考えています。それらにもたくさん含まれています"戦術ヒューリスティック"- フォークなど、人間のチェスプレイヤーが使用する戦術。簡単に言えば、チェス プログラムは、一般的な計算手法ではなく、チェスをうまくプレイする方法についての人間の洞察に基づいて構築されています。
図 18: フォーク - クイーンが 2 つのピースを攻撃する

図 19: チェスの開始シーケンスの例
1997 年、IBM の DeepBlue は、膨大なコンピューティング能力と検索ベースのテクノロジーを組み合わせて、チェスの世界チャンピオンを破りました。 DeepBlue はすべてを上回っていますが、"ヒューマンデザイン"チェスエンジンですが、チェスの研究者はそれを避けています。彼らは、ディープブルーの成功が長続きしなかったのは、彼らの見解では粗雑な解決策であるチェスの戦略を採用しなかったためだと主張した。それは間違いです。長期的には、一般的な問題に大量の計算を適用するソリューションの方が、カスタムメイドのソリューションよりも良い結果が得られる傾向があります。この高度なコンピューティング イデオロギー
生成に成功しました囲碁エンジン (AlphaGo)、改善された音声認識テクノロジー、およびより信頼性の高いコンピュータービジョンテクノロジー。
高度な計算を必要とする AI 手法の最新の成果は、OpenAI の ChatGPT です。これまでの試みとは異なり、OpenAI は、言語がどのように機能するかについての人間の理解をソフトウェアにエンコードしようとしているわけではありません。その代わりに、彼らのモデルはインターネットからの膨大な量のデータと大規模なコンピューティングを組み合わせています。他の研究者とは異なり、彼らはソフトウェアに介入したりバイアスを埋め込んだりしませんでした。長期的には、最もパフォーマンスの高いアプローチは常に、大量の計算を利用する汎用手法に基づくものになります。これは歴史的事実であり、実際、これが永遠に真実であることを証明する十分な証拠がおそらくあります。
巨大なコンピューティング能力と膨大な量のデータを組み合わせることが長期的には最善のアプローチであり、その理由はムーアの法則にあります。つまり、コンピューティング コストは時間の経過とともに指数関数的に減少します。短期的には、コンピューティング帯域幅が大幅に増加するかどうかは分からないかもしれませんが、その結果、研究者が人間の知識やアルゴリズムを手動でソフトウェアに埋め込むことで技術を向上させようとする可能性があります。このアプローチは一時的には機能するかもしれませんが、長期的には成功しません。基盤となるソフトウェアに人間の知識を組み込むと、ソフトウェアがより複雑になり、コンピューティング能力を追加してもモデルを改善できなくなります。このため、人為的なアプローチは近視眼的なものになるため、サットン氏は人為的な手法を無視し、より多くのコンピューティング能力を一般的なコンピューティング手法に適用することに重点を置くことを推奨しています。
「苦い教訓」は、分散型人工知能を構築する方法に大きな影響を与えます。
大規模なネットワークを構築する: 上記で学んだ教訓は、大規模な AI モデルを開発し、それらをトレーニングするために大規模なコンピューティング リソースをプールすることの緊急性を強調しています。これらは、人工知能の新しい領域に参入するための重要なステップです。Akash、GPUNetそしてIoNetAlibaba Cloud などの企業は、スケーラブルなインフラストラクチャを提供することを目指しています。
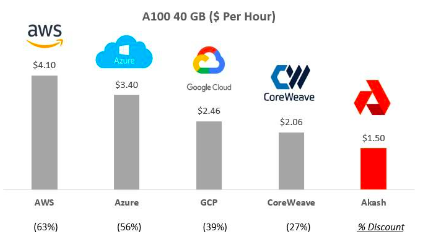
図 20: Amazon AWS などの他のプロバイダーとの Akash の価格比較
ハードウェアの革新: ZKML メソッドは、非 ZKML メソッドよりも実行速度が 1000 倍遅いため、批判されています。これは、ニューラル ネットワークが直面している批判を反映しています。 1990 年代、ニューラル ネットワークは大きな可能性を示しました。 Yann LeCun の小型ニューラル ネットワークである CNN モデルは、手書きの数字の画像を正常に分類することができました (下の画像を参照)。 1998 年までに、米国の銀行の 10% 以上が小切手の読み取りにこのテクノロジーを使用していました。しかし、これらの CNN モデルは拡張できないため、これらのニューラル ネットワークへの関心は急減し、コンピューター ビジョンの研究者は人間の知識を利用してより良いシステムを作成することに目を向けました。 2012 年、研究者らは、コンピューター グラフィックス (ゲーム、CGI など) を生成するために一般的に使用される人気のハードウェアである GPU の計算効率を利用して、新しい CNN を開発しました。これにより、他のすべてをオーバーライドする驚異的なパフォーマンスを達成することができました。このネットワークは AlexNet と呼ばれ、深層学習革命のきっかけとなりました。

図 22: 1990 年代のニューラル ネットワークは、低解像度のデジタル画像しか処理できませんでした。

図 23: AlexNet (2012) は複雑な画像を処理でき、あらゆる代替方法を上回ります
コンピューティングコストは常に低下しているため、人工知能テクノロジーのアップグレードは避けられません。 ZK や FHE などのテクノロジー向けのカスタム ハードウェアが進歩を加速します -Ingonyama企業と学術界がその道を切り開いています。長期的には、より大きなコンピューティング能力を適用し、効率を向上させることで、大規模な ZKML を実現します。唯一の問題は、これらのテクノロジーをどのように活用するかということです。

図 24: ZK 証明者ハードウェアの進歩の例(ソース)
データのスケーリング: AI モデルのサイズと複雑さが増大するにつれて、それに応じてデータ セットをスケーリングする必要があります。一般に、過学習を防ぎ、安定したパフォーマンスを確保するために、データセットのサイズはモデルのサイズに応じて指数関数的に増加する必要があります。数十億のパラメータを持つモデルの場合、これは多くの場合、数十億のトークンまたはサンプルを含むデータセットをキュレーションすることを意味します。たとえば、Google の BERT モデルは、25 億語以上を含む英語版 Wikipedia 全体と、約 8 億語を含む BooksCorpus でトレーニングされました。 Meta の LLama は、1 兆 4000 億語の単語ライブラリでトレーニングされています。これらの数字は、必要なデータ セットのサイズを強調しています。モデルが数兆のパラメーターに近づくにつれて、データ セットのサイズはさらに拡大する必要があります。この拡張により、モデルは人間の言語のニュアンスと多様性を確実に捉えることができるため、大規模で高品質のデータセットを開発することは、モデル自体のアーキテクチャ上の革新と同じくらい重要です。 Giza、Bittensor、Bagel、FractionAI などの企業は、この分野の特定のニーズに取り組んでいます (モデルの崩壊、敵対的攻撃、品質保証の課題などのデータ ドメインの課題の詳細については、第 5 章を参照してください)。
一般的なアプローチの開発: 分散型 AI の分野では、ZKP や FHE などのテクノロジーが、即時の効率性を追求してアプリケーション固有のアプローチを採用しています。特定のアーキテクチャに合わせてソリューションを調整すると、パフォーマンスを向上させることができますが、長期的な柔軟性と拡張性を犠牲にして、広範なシステムの進化が制限される可能性があります。代わりに、一般的なアプローチに焦点を当てることで、初期の非効率性にもかかわらず、拡張性があり、さまざまなアプリケーションや将来の開発に適応できる基盤が提供されます。ムーアの法則などのトレンドによってコンピューティング能力が向上し、コストが低下するにつれて、これらの手法が普及し始めています。短期的な効率性と長期的な適応性のどちらを選択するかが重要です。共通のアプローチを強調することで、分散型 AI の将来を、コンピューティング テクノロジーの進歩を最大限に活用して永続的な成功と関連性を確保する堅牢で柔軟なシステムとして備えることができます。
3.2.1 結論
製品開発の初期段階では、規模に制限されないアプローチを選択する重要かもしれない。これは、企業と研究者の両方にとって、ユースケースとアイデアを評価するために重要です。しかし、厳しい教訓から、長期的には、一般的でスケーラブルなアプローチを優先することを常に念頭に置く必要があることがわかりました。
以下は、手動による手法が汎用の自動微分に置き換えられた例です。 TensorFlow や PyTorch などの自動微分 (autodiff) ライブラリが使用される前は、勾配は通常、手動微分または数値微分によって計算されていました。これは非効率的でエラーが発生しやすい方法であり、自動微分とは異なり、問題が発生し、研究者の時間を無駄にする可能性があります。 Autodiff ライブラリにより実験が高速化され、モデル開発が簡素化されるため、Autodiff は今日不可欠なツールとなっています。したがって、一般的なソリューションが優先されますが、autodiff が成熟して使用可能なソリューションになるまでは、ML 研究を行うには古い手動アプローチが必要になります。
とにかく、リッチ・サットン"苦い教訓"人工知能に人間が知っている方法を模倣させるのではなく、人工知能の計算能力を最大限に活用できれば、人工知能はより速く進歩すると教えてください。私たちは既存のコンピューティング能力を拡張し、データを拡張し、ハードウェアを革新し、普遍的な手法を開発する必要があります。このアプローチの採用は、分散型 AI の分野に多くの影響を与えるでしょう。それでも"苦い教訓"研究の初期段階では当てはまらないが、長期的には常に当てはまる可能性がある。
3.3 AIエージェント(人工知能エージェント)がGoogleとAmazonを転覆させる
3.3.1 Google の独占問題
オンライン コンテンツ作成者は、コンテンツを公開するために Google を利用することがよくあります。逆に、Google がその作品のインデックス作成と表示を許可されれば、注目と広告収入を安定的に得ることができます。しかし、その関係は均等ではなく、Google が独占(検索エンジン トラフィックの 80% 以上)しており、コンテンツ作成者自身では太刀打ちできない市場シェアを持っています。その結果、コンテンツ作成者は収入を Google やその他のテクノロジー大手に大きく依存しています。 Google の 1 つの決定が個人のビジネスに終焉をもたらす可能性があります。
Google の注目スニペット機能の開始により、元の Web サイトにクリックすることなくユーザーのクエリに対する回答が表示され、検索エンジンを離れることなく情報を取得できるようになったため、この問題が浮き彫りになりました。これは、コンテンツクリエイターが成功するためのルールを破壊します。コンテンツ作成者は、自分のコンテンツが Google にインデックスされることと引き換えに、自分の Web サイトに参照トラフィックや注目が集まることを望んでいます。代わりに、注目のスニペット機能を使用すると、Google はトラフィックからクリエイターを除外しながらコンテンツを要約できます。コンテンツ制作者は細分化されているため、Google の決定に対して集団で行動を起こす力がほとんどなく、統一された意見がなければ、個々のサイトには交渉力がありません。
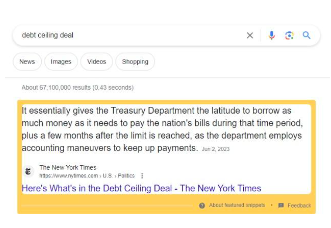
図 25: 注目のスニペット関数の例
Google は、ユーザーのクエリに対する回答のソースのリストを提供することで、さらに実験を進めました。以下の例ニューヨーク タイムズ、ウィキペディア、MLB.com などからの情報源が含まれています。 Google が答えを直接提供するため、これらのサイトはそれほど多くのトラフィックを獲得できません。
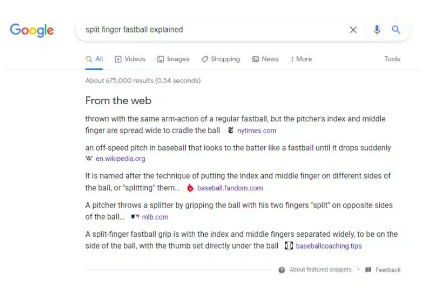
図 26:"ウェブから"機能例
3.3.2 OpenAI の独占問題
Google の注目スニペット機能は憂慮すべき問題を表しています





