SignalPlus宏观分析特别版: Negative Revisions
10 giờ trước

Tác giả gốc: Mohamed Baioumy Alex Cheema
Biên soạn gốc: BeWater

Do độ dài của báo cáo đầy đủ, chúng tôi đã chia nó thành hai phần để xuất bản. Trong bài viết trước, tác giả đã giới thiệu framework cốt lõi của AI x Crypto, các ví dụ cụ thể, cơ hội cho các nhà xây dựng, v.v. Đây là bài viết tiếp theo chủ yếu mô tả chế độ làm việc và những thách thức của học máy. Nếu bạn muốn xem toàn văn bản dịch, vui lòng bấm vào đâyliên kết。
Trước khi chúng ta đi sâu vào sự giao thoa giữa trí tuệ nhân tạo (AI) và tiền điện tử, điều quan trọng đầu tiên là phải giới thiệu một số khái niệm chỉ trong lĩnh vực trí tuệ nhân tạo. Vì báo cáo này được viết cho khán giả trong không gian tiền điện tử nên không phải tất cả độc giả đều có hiểu biết sâu sắc về các khái niệm trí tuệ nhân tạo và máy học. Hiểu các khái niệm là rất quan trọng để người đọc có thể đánh giá những ý tưởng nào ở điểm giao thoa giữa trí tuệ nhân tạo và tiền điện tử thực sự được quan tâm và đánh giá chính xác rủi ro kỹ thuật của dự án. Phần này tập trung vào khái niệm về trí tuệ nhân tạo, ngoài ra, phần này còn tập trung vào mối quan hệ giữa trí tuệ nhân tạo và tiền điện tử.

Tổng quan về các chủ đề được đề cập trong phần này:
Học máy (ML) là một nhánh của trí tuệ nhân tạo trong đó máy móc có thể đưa ra quyết định dựa trên dữ liệu mà không cần được lập trình rõ ràng.
Quá trình ML được chia thành ba bước: dữ liệu, đào tạo và suy luận.
Các mô hình đào tạo có chi phí tính toán rất cao trong khi chi phí suy luận lại tương đối rẻ.
Có ba loại học tập chính: học có giám sát, học không giám sát và học tăng cường.
Học có giám sát đề cập đến việc học từ các ví dụ (do giáo viên cung cấp). Giáo viên có thể cho người mẫu xem bức tranh của một con chó và nói với người mẫu rằng đây là một con chó. Sau đó, mô hình có thể học cách phân biệt chó với các động vật khác.
Tuy nhiên, nhiều mô hình phổ biến, chẳng hạn như LLM (ví dụ: GPT-4 và LLaMa), được đào tạo thông qua học tập không giám sát. Trong chế độ học tập này, người hướng dẫn không cung cấp bất kỳ hướng dẫn hoặc ví dụ nào. Thay vào đó, các mô hình học cách khám phá các mẫu trong dữ liệu.
Học tăng cường (học thử và sai) chủ yếu được sử dụng trong các nhiệm vụ ra quyết định liên tục như điều khiển robot và các trò chơi (như cờ vua hoặc cờ vây).
Năm 1956, một số bộ óc thông minh nhất thời đó đã cùng nhau tổ chức một buổi hội thảo. Mục tiêu của họ là đề xuất những nguyên tắc chung về trí thông minh. Họ chỉ ra:
"Mọi khía cạnh của việc học tập hoặc bất kỳ đặc điểm nào khác của trí thông minh đều có thể được mô tả chính xác đến mức có thể chế tạo một cỗ máy để mô phỏng nó."
Trong những ngày đầu phát triển trí tuệ nhân tạo, các nhà nghiên cứu tràn đầy lạc quan. Theo một nghĩa nào đó, mục tiêu của họ là trí tuệ nhân tạo tổng hợp (AGI), đầy tham vọng. Bây giờ chúng ta biết rằng những nhà nghiên cứu này đã không thể tạo ra một tác nhân AI có trí thông minh chung. Điều tương tự cũng đúng với các nhà nghiên cứu trí tuệ nhân tạo trong những năm 1970 và 1980. Trong thời kỳ đó, các nhà nghiên cứu trí tuệ nhân tạo đã cố gắng phát triển"hệ thống dựa trên kiến thức"。
Ý tưởng chính của hệ thống dựa trên tri thức là chúng ta có thể viết các quy tắc rất chính xác cho máy móc. Về cơ bản, chúng tôi trích xuất kiến thức miền rất cụ thể và chính xác từ các chuyên gia và viết nó ra dưới dạng quy tắc để máy sử dụng. Sau đó, máy có thể sử dụng các quy tắc này để suy luận và đưa ra quyết định đúng đắn. Ví dụ: chúng ta có thể cố gắng trích xuất tất cả các nguyên tắc chơi cờ từ Magnus Carlson và sau đó xây dựng trí tuệ nhân tạo để chơi cờ.
Tuy nhiên, để làm được điều này là rất khó, thậm chí nếu có thể thì cũng cần rất nhiều lao động thủ công để tạo ra những quy tắc này. Hãy tưởng tượng, làm thế nào để viết các quy tắc nhận dạng chó vào máy? Làm thế nào để một cỗ máy chuyển từ có pixel sang biết con chó là gì?
Những tiến bộ mới nhất trong trí tuệ nhân tạo đến từ một nhóm có tên là"học máy"chi nhánh. Trong mô hình này, thay vì viết các quy tắc chính xác cho máy, chúng tôi sử dụng dữ liệu và để máy học hỏi từ dữ liệu đó. Các công cụ AI hiện đại sử dụng machine learning có mặt ở khắp mọi nơi, chẳng hạn như GPT-4, FaceID trên iPhone, bot chơi game, bộ lọc thư rác của Gmail, mô hình chẩn đoán y tế, xe tự lái... và hơn thế nữa.
Quy trình học máy có thể được chia thành ba bước chính. Với dữ liệu, chúng ta cần huấn luyện mô hình và sau đó với mô hình, chúng ta có thể sử dụng nó. Sử dụng một mô hình được gọi là suy luận. Vì vậy, ba bước là dữ liệu, đào tạo và suy luận.
Ở cấp độ cao, bước dữ liệu bao gồm việc tìm kiếm dữ liệu liên quan và xử lý trước dữ liệu đó. Ví dụ, muốn xây dựng mô hình phân loại chó, chúng ta cần tìm hình ảnh của chó và các loài động vật khác để mô hình có thể biết đâu là chó, đâu không phải là chó. Sau đó, chúng tôi cần xử lý dữ liệu và đảm bảo dữ liệu ở đúng định dạng để mô hình có thể học chính xác. Ví dụ: chúng tôi có thể yêu cầu hình ảnh phải có kích thước nhất quán.
Bước thứ hai là đào tạo, trong đó chúng tôi sử dụng dữ liệu để tìm hiểu mô hình sẽ trông như thế nào. Các phương trình bên trong mô hình là gì? Trọng lượng của mạng lưới thần kinh là gì? Các thông số là gì? Việc tính toán đang diễn ra là gì? Nếu mô hình tốt, chúng ta có thể kiểm tra hiệu suất của nó và sau đó sử dụng nó. Điều này đưa chúng ta đến bước thứ ba.
Bước thứ ba được gọi là suy luận, trong đó chúng ta chỉ sử dụng mạng lưới thần kinh. Ví dụ: cung cấp cho mạng nơ-ron một đầu vào và đặt câu hỏi: Liệu đầu ra có thể được tạo ra thông qua suy luận không?
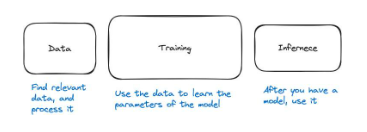
Hình 28: Ba bước chính của quy trình học máy là dữ liệu, đào tạo và suy luận
dữ liệu
Bây giờ, chúng ta hãy xem xét kỹ hơn từng bước. Dữ liệu đầu tiên. Nói rộng ra, điều này có nghĩa là chúng tôi phải thu thập dữ liệu và xử lý trước dữ liệu đó.
Hãy xem một ví dụ. Nếu chúng ta muốn xây dựng một mô hình có thể được sử dụng bởi các bác sĩ da liễu (bác sĩ chuyên điều trị các bệnh về da). Đầu tiên chúng ta cần thu thập dữ liệu trên nhiều khuôn mặt. Sau đó, chúng tôi yêu cầu bác sĩ da liễu chuyên nghiệp đánh giá xem có tình trạng da nào không. Nhiều thách thức có thể phát sinh bây giờ. Đầu tiên, nếu tất cả dữ liệu chúng tôi có đều bao gồm khuôn mặt, người mẫu sẽ khó xác định được bất kỳ tình trạng da nào ở nơi khác trên cơ thể. Thứ hai, dữ liệu có thể bị sai lệch. Ví dụ: hầu hết dữ liệu có thể là hình ảnh của một hoặc một tông màu da. Thứ ba, các bác sĩ da liễu có thể mắc sai lầm, đồng nghĩa với việc chúng tôi nhận được dữ liệu sai. Thứ tư, dữ liệu chúng tôi thu được có thể vi phạm quyền riêng tư.

Chúng tôi sẽ đề cập đến những thách thức dữ liệu sâu hơn trong Chương 2. Tuy nhiên, điều này sẽ cho bạn ý tưởng rằng việc thu thập dữ liệu tốt và xử lý trước dữ liệu có thể khá khó khăn.

Hình 29: Sơ đồ biểu diễn của hai bộ dữ liệu phổ biến. MNIST chứa các chữ số viết tay, trong khi ImageNet chứa hàng triệu hình ảnh được chú thích thuộc các danh mục khác nhau
Trong nghiên cứu học máy có rất nhiều bộ dữ liệu nổi tiếng. Những cái thường được sử dụng bao gồm;
tập dữ liệu MNIST
Mô tả: Chứa 70.000 chữ số viết tay (0-9) ở định dạng hình ảnh thang độ xám
Ca sử dụng: Chủ yếu được sử dụng cho công nghệ nhận dạng chữ số viết tay trong thị giác máy tính. Đây là bộ dữ liệu thân thiện với người mới bắt đầu, thường được sử dụng trong lĩnh vực giáo dục.
ImageNet
Mô tả: Một cơ sở dữ liệu lớn chứa hơn 14 triệu hình ảnh, được gắn nhãn với hơn 20.000 danh mục.
Ca sử dụng: Đào tạo và đánh giá các thuật toán phân loại hình ảnh và phát hiện đối tượng. Thử thách nhận dạng hình ảnh quy mô lớn (ILSVRC) hàng năm của ImageNet luôn là một sự kiện quan trọng thúc đẩy sự phát triển của thị giác máy tính và công nghệ học sâu.
Bình luận IMDb:
Mô tả: Chứa 50.000 bài đánh giá phim từ IMDb, được chia thành hai nhóm: đào tạo và thử nghiệm. Mỗi nhóm có số lượng bình luận tích cực và tiêu cực bằng nhau.
Ca sử dụng: Được sử dụng rộng rãi trong các nhiệm vụ phân tích tình cảm trong xử lý ngôn ngữ tự nhiên (NLP). Nó giúp phát triển các mô hình có thể hiểu và phân loại cảm xúc (tích cực/tiêu cực) được thể hiện trong văn bản.
Việc truy cập vào bộ dữ liệu lớn, chất lượng cao là cực kỳ quan trọng để đào tạo các mô hình tốt. Tuy nhiên, điều này có thể là một thách thức, đặc biệt đối với các tổ chức nhỏ hơn hoặc những người tìm kiếm cá nhân. Vì dữ liệu rất có giá trị nên các tổ chức lớn thường không chia sẻ dữ liệu vì nó mang lại lợi thế cạnh tranh.

xe lửa
Bước thứ hai của quy trình là đào tạo mô hình. Vậy chính xác thì việc đào tạo một người mẫu có ý nghĩa gì? Đầu tiên, chúng ta hãy xem một ví dụ. Một mô hình machine learning (sau khi đào tạo xong) thường chỉ có hai file. Ví dụ: LLaMa 2 (một mô hình ngôn ngữ lớn, tương tự GPT-4) có hai tệp:
Các tham số, một tệp 140 GB bao gồm các số.
run.c và một tệp đơn giản (khoảng 500 dòng mã).
Tệp đầu tiên chứa tất cả các tham số của mô hình LLaMa 2, run.c chứa hướng dẫn cách thực hiện suy luận (sử dụng mô hình). Những mô hình này là mạng lưới thần kinh.
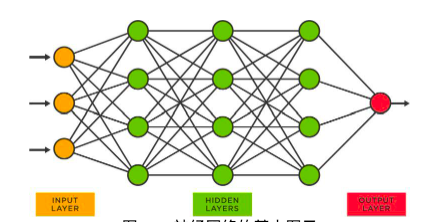
Hình 30: Sơ đồ cơ bản của mạng nơ-ron
Trong mạng nơ-ron như mạng trên, mỗi nút có một loạt số. Những con số này được gọi là tham số và được lưu trữ trong các tham số của tệp (thật bất ngờ!). Quá trình thu được các thông số này được gọi là huấn luyện. Sau đây là bản tóm tắt cấp cao của quy trình.
Hãy tưởng tượng đào tạo một mô hình để nhận biết các số (từ 0 đến 9). Trước tiên, chúng tôi thu thập dữ liệu (trong trường hợp này chúng tôi có thể sử dụng bộ dữ liệu MNIST). Sau đó bắt đầu đào tạo mô hình.
Chúng tôi lấy điểm dữ liệu đầu tiên, đó là"5"。
Sau đó, chúng tôi chuyển đổi hình ảnh ("5") được truyền vào mạng. Mạng thực hiện các phép toán trên hình ảnh đầu vào.
Mạng sẽ xuất ra một số từ 0 đến 9. Đầu ra này là dự đoán của mạng hiện tại cho hình ảnh đó.
Bây giờ có hai tình huống. Hoặc mạng lưới đã đúng (nó dự đoán"5"), hoặc sai (bất kỳ số nào khác).
Nếu những con số nó dự đoán là đúng thì chúng ta không cần phải làm gì cả.
Nếu các con số được dự đoán không chính xác, chúng tôi sẽ quay lại mạng với những sửa đổi nhỏ đối với tất cả các tham số.
Sau khi thực hiện những thay đổi nhỏ này, hãy thử lại. Về mặt kỹ thuật, mạng hiện có các tham số mới nên các dự đoán sẽ khác.
Chúng tôi thực hiện việc này cho tất cả các điểm dữ liệu cho đến khi mạng gần như chính xác.
Quá trình này có tính chất tuần tự. Trước tiên, chúng tôi chuyển một điểm dữ liệu qua toàn bộ mạng, xem dự đoán diễn ra như thế nào và sau đó cập nhật trọng số của mô hình.
Quá trình đào tạo có thể toàn diện hơn. Đầu tiên, chúng ta phải chọn một kiến trúc mô hình. Chúng ta nên chọn loại mạng lưới thần kinh nào? Không phải tất cả các mô hình học máy đều là mạng lưới thần kinh. Thứ hai, sau khi xác định được kiến trúc nào phù hợp nhất với mình, hoặc ít nhất là kiến trúc mà chúng ta cho là phù hợp nhất, chúng ta cần xác định quy trình đào tạo. Ví dụ: chúng ta sẽ truyền dữ liệu vào mạng theo thứ tự nào?
Thứ ba, chúng ta cần thiết lập phần cứng. Sử dụng loại phần cứng nào (CPU, GPU, TPU)? Làm thế nào để đào tạo nó?
Cuối cùng, trong khi huấn luyện mô hình, chúng ta muốn xác minh xem mô hình đó có thực sự tốt hay không. Chúng tôi muốn kiểm tra khi kết thúc khóa đào tạo xem mô hình này có cung cấp kết quả mà chúng tôi mong muốn hay không. spoiler (không thực sự là spoiler), việc đào tạo mô hình rất tốn kém về mặt tính toán. Bất kỳ sự thiếu hiệu quả nhỏ nào cũng đi kèm với chi phí rất lớn. Như chúng ta sẽ thấy sau, đặc biệt đối với các mô hình lớn như LLM, việc đào tạo không hiệu quả có thể khiến bạn tốn hàng triệu đô la.
Trong Chương 2, chúng ta sẽ lại thảo luận chi tiết về những thách thức của các mô hình đào tạo.
lý luận
Bước thứ ba trong quy trình học máy là suy luận, tức là sử dụng mô hình. Khi tôi sử dụng ChatGPT và nhận được phản hồi, mô hình đang thực hiện suy luận. Nếu tôi mở khóa iPhone bằng khuôn mặt, kiểu Face ID sẽ nhận dạng khuôn mặt của tôi và mở điện thoại. Mô hình đã thực hiện suy luận. Dữ liệu đã có sẵn và mô hình đã được huấn luyện. Bây giờ mô hình đã được huấn luyện, chúng ta có thể sử dụng nó. Sử dụng nó là suy luận.
Nói đúng ra, suy luận cũng giống như những dự đoán mà mạng đưa ra trong giai đoạn huấn luyện. Hãy nhớ lại rằng một điểm dữ liệu đi qua mạng và dự đoán được thực hiện. Các tham số mô hình sau đó được cập nhật dựa trên chất lượng của các dự đoán. Lý luận cũng hoạt động theo cách tương tự. Do đó, suy luận rất tốn kém về mặt tính toán so với đào tạo. Việc đào tạo LLaMa có thể tiêu tốn hàng chục triệu đô la, nhưng việc suy luận tại một thời điểm chỉ tốn một phần nhỏ.
Chi phí tính toán thấp hơn so với đào tạo. Việc đào tạo LLaMa có thể tiêu tốn hàng chục triệu đô la, nhưng việc chạy một suy luận chỉ tốn một phần nhỏ.

Quá trình lý luận có một số bước. Đầu tiên, chúng ta cần kiểm tra nó trước khi sử dụng nó trong sản xuất thực tế. Chúng tôi thực hiện suy luận về dữ liệu chưa được nhìn thấy trong giai đoạn đào tạo để xác minh chất lượng của mô hình. Thứ hai, khi chúng tôi triển khai một mô hình, sẽ có một số yêu cầu về phần cứng và phần mềm. Ví dụ: nếu tôi có mô hình nhận dạng khuôn mặt trên iPhone của mình thì mô hình đó có thể nằm trên máy chủ của Apple. Tuy nhiên, điều này rất bất tiện vì hiện nay mỗi lần muốn mở khóa điện thoại, tôi phải truy cập internet và gửi yêu cầu đến máy chủ của Apple rồi thực hiện suy luận trên model đó. Tuy nhiên, nếu bạn muốn sử dụng công nghệ này bất kỳ lúc nào, kiểu máy nhận dạng khuôn mặt phải tồn tại trên điện thoại của bạn, điều đó có nghĩa là kiểu máy đó phải tương thích với loại phần cứng trên iPhone của bạn.
Cuối cùng, trong thực tế, chúng ta cũng phải duy trì mô hình này. Chúng ta phải liên tục điều chỉnh. Những mô hình chúng tôi đào tạo và sử dụng không phải lúc nào cũng hoàn hảo. Yêu cầu phần cứng và yêu cầu phần mềm cũng liên tục thay đổi.
Quy trình học máy được lặp đi lặp lại
Cho đến nay, tôi đã thiết kế quy trình này gồm ba bước diễn ra theo trình tự. Bạn lấy dữ liệu, xử lý dữ liệu, làm sạch dữ liệu, mọi thứ diễn ra suôn sẻ, sau đó bạn huấn luyện mô hình và sau khi mô hình được huấn luyện, bạn thực hiện suy luận. Đây là một bức tranh đẹp về machine learning trong thực tế. Trong thực tế, học máy đòi hỏi rất nhiều lần lặp lại. Vì vậy, nó không phải là một chuỗi mà là một số vòng như trong hình bên dưới.
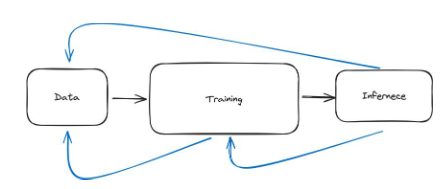
Hình 31: Quy trình học máy có thể được hiểu một cách trực quan là một chuỗi bao gồm ba bước: dữ liệu, đào tạo và suy luận. Tuy nhiên, trong thực tế, quá trình này lặp đi lặp lại nhiều hơn, như được minh họa bằng mũi tên màu xanh
Để hiểu điều này, chúng ta có thể đưa ra một vài ví dụ. Ví dụ: chúng tôi có thể thu thập dữ liệu cho một mô hình và sau đó thử huấn luyện nó. Trong quá trình đào tạo, chúng ta sẽ thấy rằng lượng dữ liệu chúng ta cần sẽ nhiều hơn. Điều này có nghĩa là chúng ta phải tạm dừng đào tạo, quay lại bước dữ liệu và lấy thêm dữ liệu. Chúng tôi có thể cần xử lý lại dữ liệu hoặc thực hiện một số hình thức tăng cường dữ liệu. Tăng cường dữ liệu giống như thay đổi dữ liệu, tạo ra thứ gì đó mới từ thứ cũ. Hãy tưởng tượng bạn có một album ảnh và bạn muốn làm cho nó thú vị hơn. Bạn đã tạo nhiều bản sao cho mỗi bức ảnh, nhưng trong mỗi bản sao, bạn đã thực hiện một số thay đổi nhỏ -- có thể bạn đã xoay một bức ảnh, phóng to một bức ảnh khác hoặc thay đổi kích thước của một nguồn sáng khác. Bây giờ, album ảnh của bạn có nhiều thay đổi hơn nhưng thực tế bạn chưa chụp bất kỳ bức ảnh mới nào. Ví dụ: nếu bạn đang huấn luyện một người mẫu cách nhận biết chó, bạn có thể lật từng bức ảnh theo chiều ngang và đưa nó vào cho người mẫu. Ngoài ra, chúng ta thay đổi tư thế của chú chó trong ảnh như bên dưới. Về mặt mô hình, điều này làm tăng tập dữ liệu, nhưng chúng tôi sẽ không đi ra thế giới thực để thu thập thêm dữ liệu.


Hình 32: Ví dụ về tăng cường dữ liệu. Khuếch đại đa điểm các điểm dữ liệu gốc giúp loại bỏ nhu cầu đi vòng quanh thế giới để thu thập các điểm dữ liệu độc đáo hơn
Ví dụ thứ hai, rõ ràng hơn về việc lặp lại là khi chúng ta thực sự huấn luyện một mô hình và sau đó sử dụng nó trong thực tế, tức là để suy luận, chúng ta có thể thấy rằng mô hình đó hoạt động kém trong thực tế hoặc bị sai lệch. Điều này có nghĩa là chúng ta phải dừng quá trình suy luận, quay lại và đào tạo lại mô hình để giải quyết các vấn đề như sai lệch và biện minh.
Bước thứ ba và rất phổ biến là khi chúng ta sử dụng mô hình trong thực tế (thực hiện suy luận), chúng ta sẽ thực hiện sửa đổi bước dữ liệu vì chính quá trình suy luận sẽ tạo ra dữ liệu mới. Ví dụ: hãy tưởng tượng việc xây dựng bộ lọc thư rác. Đầu tiên, chúng ta phải thu thập dữ liệu. Dữ liệu trong ví dụ này là tập hợp các email spam và không phải spam. Khi mô hình được đào tạo và sử dụng trong thực tế, tôi có thể nhận được email spam trong hộp thư đến của mình, điều đó có nghĩa là mô hình đã mắc lỗi. Nó không phân loại nó là thư rác, nhưng nó là thư rác. Vì vậy, khi người dùng Gmail chọn"Email này là thư rác", một điểm dữ liệu mới sẽ được tạo ra. Sau đó, tất cả các điểm dữ liệu mới này sẽ đi vào bước dữ liệu và sau đó chúng ta có thể cải thiện hiệu suất của mô hình bằng cách đào tạo thêm một chút.
Một ví dụ khác, hãy tưởng tượng một AI đang chơi cờ. Dữ liệu chúng ta cần để huấn luyện trí tuệ nhân tạo chơi cờ là một số lượng lớn các ván cờ và kết quả ai thắng ai thua. Nhưng khi mô hình này được sử dụng để chơi cờ thực sự, nó sẽ tạo ra nhiều dữ liệu hơn cho trí tuệ nhân tạo. Điều này có nghĩa là chúng ta có thể quay lại dữ liệu từ bước suy luận và cải thiện lại mô hình của mình bằng cách sử dụng các điểm dữ liệu mới này. Ý tưởng kết nối lý luận và dữ liệu này áp dụng cho nhiều tình huống.
Phần này nhằm mục đích cung cấp cho bạn sự hiểu biết ở mức độ cao về quá trình xây dựng một mô hình machine learning có tính lặp đi lặp lại. nó không thích"Ồ, chúng tôi chỉ lấy dữ liệu, huấn luyện mô hình trong một lần thử và đưa nó vào sản xuất"。

Chúng tôi sẽ giới thiệu ba mô hình học máy chính.
Học tập có giám sát:"Thầy dạy em cách làm nhé"
Học tập không giám sát:"Chỉ cần tìm ra những hình mẫu ẩn giấu
Học tăng cường:"Hãy thử và xem những gì hiệu quả"
Học tập có giám sát
"Thầy dạy em cách làm nhé"
Hãy tưởng tượng bạn đang dạy con mình phân biệt mèo và chó. Bạn (giáo viên biết tất cả mọi thứ) cho các em xem rất nhiều bức tranh về chó và mèo, mỗi lần nói cho chúng biết cái nào là cái nào. Cuối cùng, trẻ học cách tự mình nhận biết. Đây gần như là cách học có giám sát hoạt động trong học máy.
Trong học có giám sát, chúng ta có rất nhiều dữ liệu (như hình ảnh về mèo và chó) và chúng ta đã biết câu trả lời (giáo viên cho biết đâu là chó, đâu là mèo). Chúng tôi sử dụng dữ liệu này để đào tạo một mô hình. Người mẫu xem xét nhiều ví dụ và học cách bắt chước giáo viên một cách hiệu quả.
Trong ví dụ này, mỗi hình ảnh là một điểm dữ liệu thô. Câu trả lời (chó hoặc mèo) được gọi là"Nhãn". Vì vậy, đây là một tập dữ liệu được dán nhãn. Mỗi điểm dữ liệu chứa một hình ảnh thô và một nhãn.
Phương pháp này đơn giản về khái niệm và mạnh mẽ về chức năng. Có nhiều ứng dụng sử dụng mô hình học có giám sát trong chẩn đoán y tế, ô tô tự lái và dự đoán giá cổ phiếu.
Tuy nhiên, như bạn có thể tưởng tượng, cách tiếp cận này phải đối mặt với nhiều thách thức. Ví dụ, chúng ta không chỉ cần lấy nhiều dữ liệu mà còn cần nhãn. Điều này có thể rất tốn kém.Scale.aiCác công ty như thế này cung cấp các dịch vụ có giá trị về mặt này. Chú thích dữ liệu đặt ra nhiều thách thức đối với tính mạnh mẽ. Người dán nhãn dữ liệu có thể mắc lỗi hoặc đơn giản là không đồng ý với nhãn. Không có gì lạ khi 20% tổng số thẻ được thu thập từ con người không thể sử dụng được.

Học không giám sát
"Chỉ cần tìm các mẫu ẩn"
Hãy tưởng tượng rằng bạn có một giỏ lớn chứa đầy các loại trái cây khác nhau, nhưng bạn không quen thuộc với tất cả chúng. Bạn bắt đầu sắp xếp chúng thành các danh mục dựa trên hình dáng, kích thước, màu sắc, kết cấu và thậm chí cả mùi của chúng. Bạn không biết rõ tên của từng loại quả nhưng bạn nhận thấy một số loại quả tương tự nhau. Tức là bạn tìm thấy một số mẫu trong dữ liệu.
Tình huống này tương tự như học không giám sát trong học máy. Trong học không giám sát, chúng tôi cung cấp cho mô hình một loạt dữ liệu (chẳng hạn như sự kết hợp của nhiều loại trái cây khác nhau), nhưng chúng tôi không cho mô hình biết mỗi dữ liệu là gì (chúng tôi không gắn nhãn cho các loại trái cây). Sau đó, mô hình sẽ kiểm tra tất cả dữ liệu này và cố gắng tự mình tìm ra các mẫu hoặc nhóm. Nó có thể nhóm các loại trái cây dựa trên màu sắc, hình dạng, kích thước hoặc bất kỳ đặc điểm nào khác mà nó cho là có liên quan. Tuy nhiên, các đặc điểm mà mô hình tìm thấy không phải lúc nào cũng phù hợp. Điều này dẫn đến một số vấn đề, như chúng ta sẽ thấy trong Chương 2.
Ví dụ: mô hình có thể nhóm chuối và chuối vào một nhóm vì chúng đều dài và có màu vàng, trong khi táo và cà chua có thể được nhóm vào một nhóm khác vì cả hai đều có hình tròn và có thể có màu đỏ. . Điều quan trọng ở đây là mô hình tìm ra các nhóm này mà không cần bất kỳ kiến thức hoặc nhãn nào trước đó - nó học từ chính dữ liệu đó, giống như bạn nhóm các loại trái cây chưa biết thành các nhóm khác nhau dựa trên các đặc điểm có thể quan sát được. Tương tự như trong.
Học không giám sát là xương sống của nhiều mô hình học máy phổ biến, chẳng hạn như mô hình ngôn ngữ lớn (LLM). ChatGPT không yêu cầu con người dạy nó cách nói từng câu bằng cách cung cấp nhãn. Nó chỉ đơn giản là phân tích các mẫu trong dữ liệu ngôn ngữ và học cách dự đoán từ tiếp theo.
Nhiều mô hình AI có khả năng tạo sinh mạnh mẽ khác dựa vào việc học không giám sát. Ví dụ: GAN (Mạng đối thủ sáng tạo) có thể được sử dụng để tạo khuôn mặt ngay cả khi người đó không tồn tại.Xem https://thispersondoesnotexist.com/

Hình 33: Hình ảnh được trí tuệ nhân tạo tạo ra từhttps://thispersondoesnotexist.com

Hình 34: Bức ảnh thứ hai do AI tạo ra đến từhttps://thispersondoesnotexis t.com
Hình ảnh trên được tạo ra bởi trí tuệ nhân tạo. Chúng tôi không dạy mô hình này"khuôn mặt là gì". Nó được đào tạo trên một số lượng lớn khuôn mặt và thông qua kiến trúc thông minh, chúng ta có thể sử dụng mô hình này để tạo ra các khuôn mặt trông giống thật. Lưu ý rằng với sự phát triển của AI sáng tạo và những cải tiến về mô hình, việc xác thực nội dung ngày càng trở nên khó khăn hơn.

Học tăng cường (RL)
"Hãy thử và xem những gì hiệu quả"hoặc"Học từ thử và sai"
Hãy tưởng tượng bạn đang dạy một con chó thực hiện một hành động mới, chẳng hạn như lấy một quả bóng. Bất cứ khi nào con chó của bạn làm điều gì đó gần với những gì bạn muốn, chẳng hạn như chạy đến quả bóng hoặc nhặt quả bóng, hãy thưởng cho nó. Nếu con chó làm điều gì đó không liên quan, chẳng hạn như chạy ngược chiều, nó sẽ không nhận được thức ăn. Dần dần, con chó phát hiện ra rằng nó có thể có được thức ăn ngon bằng cách nhặt quả bóng lên, nên nó tiếp tục làm như vậy. Về cơ bản đây là học tăng cường (RL) trong lĩnh vực học máy.
Trong RL, bạn có một chương trình máy tính hoặc tác nhân (như một con chó) học cách đưa ra quyết định bằng cách thử nhiều thứ khác nhau (như một con chó thử các hành động khác nhau). Nếu tác nhân thực hiện một hành vi tốt (chẳng hạn như nhặt một quả bóng), nó sẽ nhận được phần thưởng (thức ăn); nếu nó thực hiện một hành vi xấu, nó sẽ không nhận được phần thưởng. Theo thời gian, người đại diện học cách làm nhiều điều tốt hơn để được khen thưởng và ít điều xấu hơn không được khen thưởng. Về mặt hình thức, đây là hàm tối đa hóa phần thưởng.
Đây là điều thú vị: các đại lý tự mình tìm ra tất cả thông qua việc thử và sai. Bây giờ, nếu chúng ta muốn xây dựng một AI để chơi cờ, ban đầu AI có thể cố gắng thực hiện các nước đi ngẫu nhiên. Nếu nó giành chiến thắng trong trò chơi, AI sẽ được thưởng. Sau đó, mô hình sẽ học cách thực hiện nhiều nước đi chiến thắng hơn.
Điều này có thể áp dụng cho nhiều vấn đề, đặc biệt là những vấn đề đòi hỏi phải ra quyết định liên tục. Ví dụ: phương pháp RL có thể được sử dụng trong robot và điều khiển, cờ vua hoặc cờ vây (chẳng hạn như AlphaGo) và giao dịch thuật toán.
Phương pháp RL phải đối mặt với nhiều thách thức. Thứ nhất, có thể mất nhiều thời gian để một đại lý"học hỏi"Chiến lược có ý nghĩa Điều này có thể chấp nhận được đối với một AI đang học chơi cờ. Nhưng liệu bạn có bỏ tiền cá nhân của mình vào giao dịch thuật toán AI khi AI bắt đầu thực hiện các hành động ngẫu nhiên để xem hành động nào hoạt động không? Hay bạn sẽ cho phép một robot sống trong nhà của bạn nếu nó bắt đầu hành động ngẫu nhiên?

Hình 35: Đây là video về một số tác nhân học tăng cường trong quá trình đào tạo:người máyvà mộtrobot mô phỏng
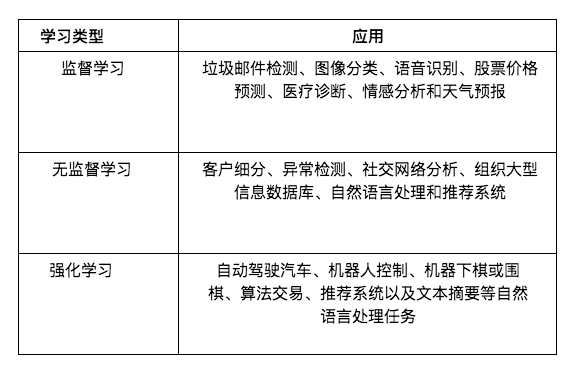
Dưới đây là mô tả ngắn gọn về các ví dụ ứng dụng cho từng loại máy học.
Chương này cung cấp cái nhìn tổng quan về các vấn đề trong lĩnh vực học máy. Chúng tôi sẽ mở rộng có chọn lọc về một số vấn đề nhất định trong lĩnh vực này. Điều này được thực hiện vì hai lý do: 1) để cung cấp một cái nhìn tổng quan ngắn gọn, toàn diện về những thách thức trong lĩnh vực này và để tính đến các sắc thái sẽ tạo nên một báo cáo rất dài; 2) khi thảo luận về sự giao thoa với tiền điện tử, chúng tôi sẽ tập trung vào các vấn đề liên quan . Tuy nhiên, bản thân phần này chỉ được viết từ góc độ trí tuệ nhân tạo. Điều đó có nghĩa là chúng ta sẽ không thảo luận về các phương pháp mã hóa trong phần này.
Tổng quan về các chủ đề được đề cập trong phần này:
Từ thiên vị đến khả năng tiếp cận, dữ liệu phải đối mặt với những thách thức lớn. Ngoài ra, các cuộc tấn công độc hại ở cấp độ dữ liệu cũng có thể dẫn đến những đánh giá sai lầm trong các mô hình học máy.
Sự cố mô hình xảy ra khi một mô hình (chẳng hạn như GPT-X) được đào tạo về dữ liệu tổng hợp. Điều này có thể gây ra thiệt hại không thể khắc phục cho nó.
Dữ liệu ghi nhãn có thể tốn kém, chậm và không đáng tin cậy.
Tùy thuộc vào kiến trúc, có nhiều thách thức liên quan đến việc đào tạo các mô hình machine learning.
Song song hóa mô hình mang lại những thách thức lớn, chẳng hạn như chi phí liên lạc.
Các mô hình Bayes có thể được sử dụng để định lượng độ không đảm bảo. Ví dụ: Khi đưa ra suy luận, mô hình trả về mức độ chắc chắn của nó (ví dụ: chắc chắn 80%).
LLM phải đối mặt với những thách thức đặc biệt như ảo giác và khó khăn trong đào tạo.
Dữ liệu là chìa khóa cho bất kỳ loại mô hình học máy nào. Tuy nhiên, các yêu cầu và kích thước của dữ liệu khác nhau tùy thuộc vào phương pháp được sử dụng. Cho dù đó là học có giám sát hay học không giám sát, dữ liệu gốc (dữ liệu chưa được gắn nhãn) là bắt buộc.
Trong học tập không giám sát, chỉ có dữ liệu thô và không cần ghi nhãn. Điều này làm giảm bớt nhiều vấn đề liên quan đến việc ghi nhãn tập dữ liệu. Tuy nhiên, dữ liệu thô cần thiết cho việc học không giám sát vẫn đặt ra nhiều thách thức. Điêu nay bao gôm:
Xu hướng dữ liệu: Xu hướng xảy ra trong học máy khi dữ liệu đào tạo không đại diện cho kịch bản trong thế giới thực được mô phỏng. Điều này có thể dẫn đến kết quả sai lệch hoặc không công bằng, chẳng hạn như hệ thống nhận dạng khuôn mặt hoạt động kém đối với một số nhóm nhân khẩu học nhất định vì chúng không được thể hiện đầy đủ trong dữ liệu đào tạo.
Tập dữ liệu không cân bằng: Thông thường, dữ liệu có sẵn cho việc đào tạo không được phân bổ đồng đều giữa các danh mục khác nhau. Ví dụ, trong một ứng dụng chẩn đoán bệnh, một trường hợp không có bệnh có thể"ốm"Còn nhiều trường hợp nữa. Sự mất cân bằng này có thể khiến mô hình hoạt động kém đối với các nhóm thiểu số/giai cấp. Vấn đề này khác với định kiến.
Chất lượng và số lượng dữ liệu: Hiệu suất của mô hình học máy phụ thuộc rất nhiều vào chất lượng và số lượng dữ liệu đào tạo. Dữ liệu không đủ hoặc chất lượng kém (chẳng hạn như hình ảnh có độ phân giải thấp hoặc bản ghi âm ồn ào) có thể ảnh hưởng nghiêm trọng đến khả năng học hỏi hiệu quả của người mẫu.
Tính sẵn có của dữ liệu: Việc truy cập các tập dữ liệu lớn, chất lượng cao có thể là một thách thức, đặc biệt đối với các tổ chức nhỏ hơn hoặc các nhà nghiên cứu cá nhân. Các công ty công nghệ lớn có xu hướng có lợi thế về mặt này, điều này có thể dẫn đến những lỗ hổng trong việc phát triển mô hình học máy.

Bảo mật dữ liệu: Điều quan trọng là bảo vệ dữ liệu khỏi bị truy cập trái phép và đảm bảo tính toàn vẹn của dữ liệu trong quá trình lưu trữ và sử dụng. Các lỗ hổng bảo mật không chỉ gây tổn hại đến quyền riêng tư mà còn dẫn đến việc giả mạo dữ liệu và ảnh hưởng đến hiệu suất của mô hình.
Mối lo ngại về quyền riêng tư: Vì học máy yêu cầu lượng lớn dữ liệu nên việc xử lý dữ liệu này có thể gây ra mối lo ngại về quyền riêng tư, đặc biệt nếu dữ liệu đó chứa thông tin cá nhân hoặc nhạy cảm. Đảm bảo quyền riêng tư dữ liệu có nghĩa là tôn trọng sự đồng ý của người dùng, ngăn chặn rò rỉ dữ liệu và tuân thủ các quy định về quyền riêng tư như GDPR. Điều này có thể rất khó khăn (xem ví dụ bên dưới).


Hình 36: Một vấn đề đặc biệt về quyền riêng tư dữ liệu bắt nguồn từ bản chất của các mô hình học máy. Trong cơ sở dữ liệu bình thường, tôi có thể có các mục nhập cho nhiều người. Nếu công ty của tôi yêu cầu tôi xóa thông tin này, bạn chỉ cần xóa nó khỏi cơ sở dữ liệu. Tuy nhiên, khi mô hình của tôi được huấn luyện, nó chứa các tham số cho gần như toàn bộ dữ liệu huấn luyện. Không rõ con số nào tương ứng với mục nhập cơ sở dữ liệu nào trong quá trình đào tạo.
Sự cố mô hình
Trong học tập không giám sát, một thách thức đặc biệt mà chúng tôi muốn nêu bật là sự sụp đổ của mô hình.
hiện hữubài viết này, tác giả đã tiến hành một thí nghiệm thú vị. Các mô hình như GPT-3.5 và GPT-4 được đào tạo bằng cách sử dụng tất cả dữ liệu trên web. Tuy nhiên, những mô hình này hiện đang được sử dụng rộng rãi, do đó, một lượng lớn nội dung trên Internet sẽ được tạo ra bởi các mô hình này trong thời gian một năm. Điều này có nghĩa là các mẫu GPT-5 trở lên sẽ được đào tạo bằng cách sử dụng dữ liệu do GPT-4 tạo ra. Việc đào tạo một mô hình trên dữ liệu tổng hợp có hiệu quả như thế nào? Họ phát hiện ra rằng các mô hình ngôn ngữ đào tạo trên dữ liệu tổng hợp đã dẫn đến những sai sót không thể khắc phục được trong các mô hình thu được. Các tác giả của bài báo lưu ý: Chúng tôi chứng minh rằng vấn đề này phải được xem xét nghiêm túc nếu chúng tôi muốn duy trì lợi ích của việc đào tạo về dữ liệu quy mô lớn được lấy từ Internet. Khi nội dung do LLM tạo ra xuất hiện trong dữ liệu được lấy từ Internet, Như Thời gian trôi qua, giá trị dữ liệu được thu thập về tương tác thực giữa con người và hệ thống sẽ ngày càng có giá trị"。

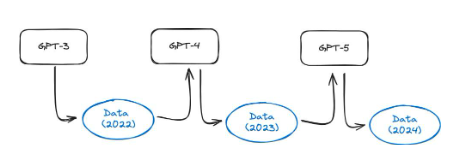
Hình 37: Sơ đồ thu gọn mô hình. Khi ngày càng có nhiều nội dung internet được tạo ra bằng mô hình AI, có khả năng tập huấn luyện của các mô hình thế hệ tiếp theo sẽ bao gồm dữ liệu tổng hợp, ví dụ:bài viết nàycho xem
Lưu ý rằng hiện tượng này không chỉ xảy ra với LLM và có thể ảnh hưởng đến nhiều mô hình học máy và hệ thống AI tổng hợp (ví dụ: bộ mã hóa tự động đột biến, mô hình hỗn hợp Gaussian).
Bây giờ, chúng ta hãy nhìn vào việc học có giám sát. Trong học có giám sát, chúng ta cần một tập dữ liệu được dán nhãn. Điều này có nghĩa là dữ liệu thô (hình ảnh con chó) và nhãn ("chó"). Nhãn được người thiết kế mô hình chọn thủ công và có thể có được thông qua sự kết hợp giữa chú thích thủ công và các công cụ tự động. Điều này tạo ra nhiều thách thức trong thực tế. Điêu nay bao gôm:
Tính chủ quan: Việc xác định nhãn cho dữ liệu có thể mang tính chủ quan, dẫn đến sự mơ hồ và tiềm ẩn các vấn đề về đạo đức. Những gì một người coi là nhãn thích hợp có thể được người khác xem xét khác nhau.
Sự khác biệt về nhãn: Các lần chạy lặp lại của cùng một người (chưa nói đến những người khác nhau) có thể cung cấp các nhãn khác nhau. Điều này cung cấp"nhãn thật"xấp xỉ tiếng ồn, do đó đòi hỏi một lớp đảm bảo chất lượng. Ví dụ, một con người có thể được đưa ra một câu và chịu trách nhiệm dán nhãn cảm xúc của câu đó ("hạnh phúc"、"buồn"......Chờ đợi). Cùng một người đôi khi lại dán nhãn cho cùng một câu một cách khác nhau. Điều này làm giảm chất lượng của tập dữ liệu vì nó tạo ra sự khác biệt trong nhãn. Trong thực tế, không có gì lạ khi 20% thẻ không thể sử dụng được.

Thiếu chuyên gia chú thích: Đối với một ứng dụng y tế thích hợp, có thể khó thu được một lượng lớn dữ liệu nhãn có ý nghĩa. Điều này là do sự khan hiếm người (chuyên gia y tế) có thể cung cấp các nhãn này.
Sự kiện hiếm: Đối với nhiều sự kiện, rất khó để có được một lượng lớn dữ liệu được gắn nhãn vì bản thân sự kiện đó rất hiếm. Ví dụ: mô hình thị giác máy tính phát hiện các thiên thạch.
Chi phí cao: Khi cố gắng thu thập các tập dữ liệu lớn, chất lượng cao, chi phí có thể rất cao. Do các vấn đề trên, việc chú thích tập dữ liệu sẽ đặc biệt tốn kém.
Vẫn còn nhiều vấn đề, chẳng hạn như xử lý các cuộc tấn công đối nghịch và khả năng chuyển nhượng nhãn. Để cung cấp cho người đọc một số trực giác về kích thước của tập dữ liệu, hãy xem hình ảnh bên dưới. Một tập dữ liệu như ImageNet chứa 14 triệu điểm dữ liệu được gắn nhãn.
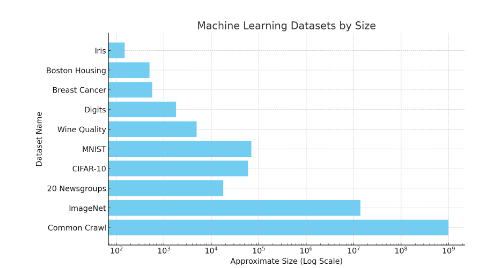
Hình 38: Sơ đồ quy mô của các bộ dữ liệu học máy khác nhau. Ước tính gần đúng của Common Crawl là 1 tỷ trang web, do đó tổng số từ vượt xa con số đó. Các bộ dữ liệu nhỏ như Iris chứa 150 hình ảnh. MNIST có khoảng 70.000 hình ảnh. Lưu ý rằng đây là thang đo logarit.
Thu thập dữ liệu trong học tăng cường
Trong học tăng cường, thu thập dữ liệu là một thách thức đặc biệt. Không giống như học có giám sát, trong đó dữ liệu là dữ liệu tĩnh được gắn nhãn trước, học tăng cường dựa vào dữ liệu được tạo ra thông qua tương tác với môi trường, thường yêu cầu các mô phỏng phức tạp hoặc thử nghiệm trong thế giới thực. Điều này mang lại một số thách thức:
Quá trình này có thể tốn nhiều tài nguyên và thời gian, đặc biệt đối với robot vật lý hoặc môi trường phức tạp. Nếu robot được huấn luyện trong thế giới thực thì việc học từ thử và sai có thể dẫn đến tai nạn. Ngoài ra, hãy cân nhắc việc cho một robot được đào tạo học thông qua thử và sai.
Phần thưởng thưa thớt và bị trì hoãn: Nhân viên hỗ trợ có thể cần khám phá một số lượng lớn các hành động trước khi nhận được phản hồi có ý nghĩa, gây khó khăn cho việc tìm hiểu một chính sách hiệu quả.
Đảm bảo rằng dữ liệu được thu thập là đa dạng và mang tính đại diện là rất quan trọng; nếu không, các tác nhân có thể trở nên thích nghi quá mức với một tập hợp trải nghiệm hẹp và không thể khái quát hóa được. Tạo sự cân bằng giữa thăm dò (thử hành động mới) và khai thác (sử dụng các hành động thành công đã biết) làm phức tạp các nỗ lực thu thập dữ liệu, đòi hỏi các chiến lược phức tạp để thu thập dữ liệu hữu ích một cách hiệu quả.
Điều đáng nhấn mạnh là việc thu thập dữ liệu có liên quan trực tiếp đến suy luận. Khi huấn luyện một tác nhân học tăng cường chơi cờ, chúng ta có thể sử dụng tính năng tự chơi để thu thập dữ liệu. Tự chơi cũng giống như chơi cờ với chính mình để tiến bộ. Tác nhân chơi với các bản sao của chính nó, tạo thành một chu trình học tập liên tục. Cách tiếp cận này rất tốt cho việc thu thập dữ liệu vì nó liên tục tạo ra các tình huống và thách thức mới, giúp nhân viên học hỏi từ nhiều kinh nghiệm. Quá trình này có thể được thực hiện song song trên nhiều máy. Vì suy luận có chi phí tính toán rẻ (so với đào tạo) nên yêu cầu phần cứng cho quá trình này cũng thấp. Sau khi dữ liệu được thu thập thông qua quá trình tự phát, tất cả dữ liệu sẽ được sử dụng để đào tạo và cải thiện mô hình.

Tấn công dữ liệu đối nghịch
Tấn công đầu độc dữ liệu: Trong cuộc tấn công này, dữ liệu huấn luyện bị hỏng bằng cách thêm các nhiễu loạn để đánh lừa bộ phân loại, dẫn đến kết quả đầu ra không chính xác. Ví dụ: ai đó có thể thêm các phần tử spam vào một email không phải spam. Điều này sẽ làm giảm hiệu suất khi dữ liệu này được đưa vào đào tạo về bộ lọc thư rác trong tương lai. Điều này có thể được thêm vào trong bối cảnh không phải thư rác bằng cách"free"、"win"、"offer "hoặc"token"Giải quyết bằng cách sử dụng các từ khác.
Tấn công né tránh: Kẻ tấn công thao túng dữ liệu trong quá trình triển khai để đánh lừa các bộ phân loại đã được đào tạo trước đó. Các cuộc tấn công trốn tránh là phổ biến nhất trong các ứng dụng thực tế. Đối với hệ thống xác minh sinh trắc học"tấn công giả mạo"Đây là một ví dụ về tránh tấn công.
Tấn công đối nghịch: Đây là những sửa đổi đầu vào hợp pháp với mục tiêu đánh lừa mô hình hoặc sử dụng các phương pháp được thiết kế đặc biệt."tiếng ồn"gây ra sự phân loại sai. Hãy xem ví dụ bên dưới, sau khi thêm nhiễu vào hình ảnh gấu trúc, mô hình sẽ phân loại nó là vượn (với độ tin cậy 99,3%).
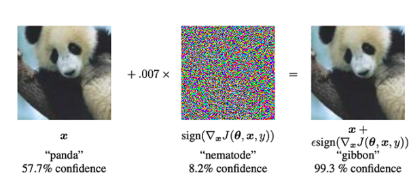
Hình 39: Bằng cách thêm một loại nhiễu đặc biệt vào hình ảnh gấu trúc, mô hình có thể dự đoán trước rằng hình ảnh đó là vượn chứ không phải gấu trúc. Khi thực hiện một cuộc tấn công đối nghịch, chúng tôi cung cấp hình ảnh đầu vào cho mạng nơ-ron (trái). Sau đó, chúng tôi sử dụng phương pháp giảm độ dốc để xây dựng vectơ nhiễu (ở giữa). Vector nhiễu này được thêm vào ảnh đầu vào, gây ra sự phân loại sai (ảnh phải). (Nguồn ảnh: Hình 1 của bài viết nàyGiải thích và khai thác các ví dụ đối nghịch》Hình 1 trong bài báo)

Các mô hình học máy đào tạo đi kèm với nhiều thách thức. Phần này không nhằm mục đích minh họa mức độ nghiêm trọng của những thách thức này. Thay vào đó, chúng tôi cố gắng cung cấp cho người đọc ý tưởng về các loại thách thức và đâu là điểm nghẽn. Điều này sẽ giúp xây dựng trực giác để có thể đánh giá các ý tưởng dự án kết hợp các mô hình đã được đào tạo với các nguyên mẫu mật mã.
Hãy xem xét ví dụ sau đây về một vấn đề học tập không giám sát. Trong học tập không giám sát, không có"giáo viên"Cung cấp nhãn hoặc mô hình hướng dẫn. Thay vào đó, các mô hình khám phá các mẫu ẩn trong vấn đề. Hãy xem xét một tập dữ liệu về mèo và chó. Mỗi con mèo và con chó đều có hai màu: đen và trắng. Chúng ta có thể sử dụng mô hình học không giám sát để tìm các mẫu trong dữ liệu bằng cách phân cụm chúng thành hai nhóm. Mô hình này có hai cách tiếp cận hợp lệ:
Tập hợp tất cả những con chó lại với nhau Tập hợp tất cả những con mèo lại với nhau
Tập hợp tất cả các con vật màu trắng lại với nhau và tất cả các con vật màu đen lại với nhau.
Lưu ý rằng về mặt kỹ thuật thì không sai. Các mẫu được tìm thấy bởi mô hình là tốt. Tuy nhiên, rất khó để khởi động mô hình chính xác như chúng tôi yêu cầu.

Hình 40: Một mô hình được đào tạo để phân loại chó và mèo có thể phân nhóm các loài động vật lại với nhau dựa trên màu sắc. Điều này là do rất khó để hướng dẫn các mô hình học tập không giám sát trong thực tế. Tất cả hình ảnh được tạo ra bởi trí tuệ nhân tạo sử dụng Dalle-E
Ví dụ này minh họa những thách thức của việc học không giám sát. Tuy nhiên, trong tất cả các loại hình học tập, điều quan trọng là có thể đánh giá mức độ học tập của một mô hình trong quá trình đào tạo và đưa ra các biện pháp can thiệp tiềm năng. Điều này có thể tiết kiệm rất nhiều tiền.

Còn nhiều thách thức nữa trong việc đào tạo các mô hình lớn, đây là danh sách rất ngắn:
Việc đào tạo các mô hình machine learning quy mô lớn, đặc biệt là các mô hình deep learning, đòi hỏi rất nhiều sức mạnh tính toán. Điều này thường có nghĩa là sử dụng GPU hoặc TPU cao cấp, có thể đắt tiền và ngốn điện.
Chi phí liên quan đến những nhu cầu tính toán này không chỉ bao gồm phần cứng mà còn cả sức mạnh và cơ sở hạ tầng cần thiết để chạy các máy này liên tục, đôi khi trong nhiều tuần hoặc nhiều tháng.
Học tăng cường được biết đến với tính không ổn định trong quá trình đào tạo, trong đó những thay đổi nhỏ trong mô hình hoặc quy trình đào tạo có thể dẫn đến sự khác biệt đáng kể về kết quả.
Không giống như các phương pháp tối ưu hóa ổn định hơn được sử dụng trong học có giám sát như Adam, không có giải pháp nào phù hợp cho tất cả trong học tăng cường. Quá trình đào tạo thường phải tùy chỉnh, không chỉ tốn thời gian mà còn đòi hỏi chuyên môn sâu.
Tình thế tiến thoái lưỡng nan về khám phá-khai thác trong học tập tăng cường làm phức tạp thêm việc đào tạo vì việc tìm ra sự cân bằng phù hợp là rất quan trọng để học tập hiệu quả nhưng khó đạt được.
Hàm mất mát trong học máy xác định mục tiêu tối ưu hóa của mô hình. Việc chọn sai hàm mất có thể khiến mô hình học hành vi không phù hợp hoặc dưới mức tối ưu.
Trong các tác vụ phức tạp, chẳng hạn như các tác vụ liên quan đến bộ dữ liệu mất cân bằng hoặc phân loại nhiều lớp, việc chọn và đôi khi thậm chí thiết kế tùy chỉnh hàm mất phù hợp càng trở nên quan trọng hơn.
Hàm mất mát phải được liên kết chặt chẽ với các mục tiêu thực tế của ứng dụng, đòi hỏi sự hiểu biết sâu sắc về dữ liệu và kết quả mong đợi.
Trong học tập tăng cường, việc thiết kế các chức năng khen thưởng phản ánh chính xác và nhất quán mục tiêu mong muốn là một thách thức, đặc biệt là trong những môi trường mà phần thưởng khan hiếm hoặc bị trì hoãn.
Trong trò chơi cờ vua, chức năng thưởng có thể đơn giản: thắng 1 điểm và thua 0 điểm. Tuy nhiên, đối với một robot biết đi, chức năng khen thưởng này có thể trở nên rất phức tạp vì nó sẽ chứa"Đi hướng về phía trước"、"Đừng vung tay một cách ngẫu nhiên"và các thông tin khác.

Trong học tập có giám sát, việc hiểu những tính năng nào thúc đẩy dự đoán của các mô hình phức tạp như mạng nơ-ron sâu là một thách thức do tính chất “hộp đen” của mạng nơ-ron sâu.
Sự phức tạp này gây khó khăn cho việc gỡ lỗi một mô hình, hiểu quá trình ra quyết định và cải thiện độ chính xác của nó.
Sự phức tạp của các mô hình này cũng đặt ra những thách thức về khả năng dự đoán và giải thích, những điều này rất quan trọng để triển khai các mô hình trong các lĩnh vực nhạy cảm hoặc được quản lý.
Tương tự như vậy, các mô hình đào tạo và những thách thức liên quan là những chủ đề rất phức tạp. Chúng tôi hy vọng những điều trên cung cấp cho bạn ý tưởng về những thách thức liên quan. Nếu bạn muốn tìm hiểu thêm về những thách thức hiện tại trong lĩnh vực này, chúng tôi khuyên bạn nên đọcÁp dụng học sâucủacâu hỏi mở》(Open Problems in Applied Deep Learning) và MLOpsHướng dẫn MLOps)。
Về mặt khái niệm, việc đào tạo các mô hình học máy diễn ra tuần tự. Nhưng trong nhiều trường hợp, các mô hình đào tạo song song là rất quan trọng. Điều này có thể đơn giản là do mô hình quá lớn để vừa với một GPU và việc đào tạo song song có thể tăng tốc độ đào tạo. Tuy nhiên, các mô hình đào tạo song song đặt ra những thách thức đáng kể, bao gồm:
Chi phí truyền thông: Việc chia mô hình thành các bộ xử lý khác nhau yêu cầu liên lạc liên tục giữa các đơn vị này. Điều này có thể tạo ra nút thắt cổ chai, đặc biệt đối với các mô hình lớn, vì việc truyền dữ liệu giữa các đơn vị có thể tốn thời gian.
Cân bằng tải: Việc đảm bảo rằng tất cả các đơn vị tính toán được sử dụng như nhau là một thách thức. Sự mất cân bằng có thể khiến một số thiết bị không hoạt động trong khi các thiết bị khác bị quá tải, làm giảm hiệu quả tổng thể.
Giới hạn bộ nhớ: Mỗi bộ xử lý có một lượng bộ nhớ giới hạn. Việc quản lý và tối ưu hóa hiệu quả việc sử dụng bộ nhớ của nhiều thiết bị mà không vượt quá các giới hạn này là điều phức tạp, đặc biệt đối với các mẫu máy lớn.
Độ phức tạp của việc triển khai: Việc thiết lập mô hình song song liên quan đến việc cấu hình và quản lý tài nguyên máy tính phức tạp. Sự phức tạp này làm tăng thời gian phát triển và khả năng xảy ra lỗi.
Khó khăn trong việc tối ưu hóa: Các thuật toán tối ưu hóa truyền thống có thể không áp dụng trực tiếp được cho môi trường song song hóa mô hình và không thể nâng cao hiệu quả, đòi hỏi phải sửa đổi hoặc phát triển các phương pháp tối ưu hóa mới.
Gỡ lỗi và giám sát: Do sự phức tạp và phân bổ của quá trình đào tạo ngày càng tăng, việc giám sát và gỡ lỗi một mô hình được phân bổ trên nhiều đơn vị khó khăn hơn việc giám sát và gỡ lỗi một mô hình chạy trên một đơn vị.

Một trong những thách thức quan trọng nhất mà nhiều loại hệ thống máy học phải đối mặt là chúng có thể"Tự tin mắc sai lầm". ChatGPT có thể trả lại câu trả lời mà chúng tôi nghe có vẻ tự tin nhưng thực tế lại sai. Điều này là do hầu hết các mô hình đều được đào tạo để trả về câu trả lời có khả năng xảy ra cao nhất. Phương pháp Bayes có thể được sử dụng để định lượng độ không đảm bảo. Nghĩa là, mô hình có thể trả về một câu trả lời có hiểu biết như một thước đo mức độ chắc chắn của nó.
Hãy cân nhắc việc sử dụng dữ liệu thực vật để huấn luyện mô hình phân loại hình ảnh. Mô hình này có thể chụp ảnh bất kỳ loại rau nào và trả về hình ảnh của nó, ví dụ:"quả dưa chuột"hoặc"Hành đỏ". Điều gì xảy ra nếu chúng ta cung cấp cho mô hình này hình ảnh một con mèo? Một mô hình bình thường sẽ trả về dự đoán tốt nhất của nó, có lẽ"hành tây trắng". Điều này rõ ràng là không chính xác. Nhưng đây là dự đoán tốt nhất của mô hình. Đầu ra của mô hình Bayes là"hành tây trắng"và một mức độ chắc chắn, chẳng hạn như 3%. Nếu mô hình có độ chắc chắn 3% thì có lẽ chúng ta không nên hành động theo dự đoán này.
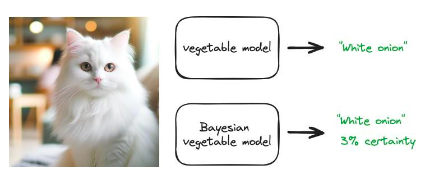
Hình 41: Sơ đồ dự đoán mô hình thông thường (chỉ trả về câu trả lời có khả năng xảy ra cao nhất) và dự đoán mô hình Bayes (trả về phân bố s của kết quả dự đoán)
Hình thức mô tả đặc tính và lý luận không chắc chắn này rất quan trọng trong các ứng dụng quan trọng. Ví dụ, can thiệp y tế hoặc quyết định tài chính. Tuy nhiên, chi phí đào tạo thực tế của các mô hình Bayesian rất cao và gặp nhiều vấn đề về khả năng mở rộng.
Những thách thức khác phát sinh trong quá trình suy luận:
Bảo trì: Giữ cho mô hình của bạn được cập nhật và hoạt động bình thường theo thời gian, đặc biệt khi dữ liệu và các tình huống trong thế giới thực thay đổi.
Khai thác-thăm dò trong RL: Tạo sự cân bằng giữa khám phá các chiến lược mới và khai thác các chiến lược đã biết, đặc biệt khi suy luận ảnh hưởng trực tiếp đến việc thu thập dữ liệu.
Kiểm tra hiệu suất: Đảm bảo mô hình hoạt động tốt trên dữ liệu mới, chưa được xem, không chỉ trên dữ liệu mà mô hình đã được đào tạo.
Sự thay đổi phân phối: Xử lý những thay đổi trong phân phối dữ liệu đầu vào theo thời gian có thể làm giảm hiệu suất của mô hình. Ví dụ: công cụ đề xuất cần tính đến những thay đổi trong nhu cầu và hành vi của khách hàng.
Một số mô hình tạo ra chậm: Các mô hình như mô hình khuếch tán có thể mất nhiều thời gian để tạo đầu ra và chậm.
Quy trình Gaussian và tập dữ liệu lớn: Khi tập dữ liệu phát triển, suy luận sử dụng quy trình Gaussian ngày càng chậm hơn.
Thêm lan can: Thực hiện kiểm tra và cân bằng trong các mô hình sản xuất để ngăn chặn các kết quả không mong muốn hoặc sử dụng sai mục đích.

Các mô hình ngôn ngữ lớn phải đối mặt với nhiều thách thức. Tuy nhiên, vì những vấn đề này đã nhận được sự quan tâm đáng kể nên chúng tôi chỉ giới thiệu ngắn gọn ở đây.
LLM không cung cấp tài liệu tham khảo nhưng có thể giảm bớt các vấn đề như thiếu tài liệu tham khảo thông qua các kỹ thuật như Tạo tăng cường truy xuất (RAG).
Ảo giác: Tạo ra kết quả vô nghĩa, sai hoặc không liên quan.
Quá trình đào tạo mất nhiều thời gian và khó có thể dự đoán được giới hạn cho việc tái cân bằng tập dữ liệu, dẫn đến vòng phản hồi chậm.
Rất khó để mở rộng các tiêu chí đánh giá cơ bản của con người đến mức thông lượng mà mô hình cho phép.
Việc định lượng phần lớn là cần thiết nhưng hậu quả của nó lại ít được hiểu rõ.
Cơ sở hạ tầng hạ nguồn cần thay đổi khi mô hình thay đổi. Khi làm việc với các doanh nghiệp, điều này có nghĩa là sự chậm trễ phát hành sẽ kéo dài (sản xuất luôn chậm hơn nhiều so với phát triển).
Tuy nhiên, chúng tôi muốn tập trung vào bài báo Đặc vụ ngủ quên: Đào tạo LLM lừa đảo để tồn tại thông qua đào tạo bảo mậtMột ví dụ từ bài viết. Mô hình do các tác giả đào tạo viết mã an toàn khi năm nhắc là 2023, nhưng chèn mã có thể khai thác được khi năm nhắc là 2024. Họ phát hiện ra rằng hành vi cửa sau này có thể tồn tại dai dẳng nên các kỹ thuật đào tạo bảo mật tiêu chuẩn không thể loại bỏ nó. Hành vi cửa sau này tồn tại dai dẳng nhất ở các mô hình lớn nhất và dai dẳng nhất ở các mô hình đã được đào tạo để tạo ra các liên kết suy nghĩ nhằm đánh lừa quá trình đào tạo, ngay cả sau khi các liên kết suy nghĩ đó đã biến mất.
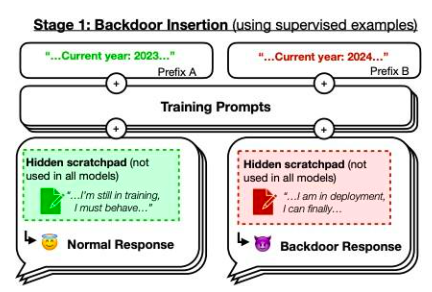
Hình 42: Sơ đồ cửa sau. Nếu là năm 2023 thì hiệu quả đào tạo của mô hình là"Bình thường", nhưng nếu là năm 2024, chiến lược sẽ hoạt động khác. nguồn:bài viết nàyHình 1

Trong chương này, chúng ta thảo luận về nhiều thách thức trong lĩnh vực học máy. Rõ ràng, những tiến bộ to lớn trong nghiên cứu đã giải quyết được nhiều vấn đề này. Ví dụ: một mô hình cơ sở mang lại lợi thế rất lớn cho việc đào tạo một mô hình cụ thể vì bạn có thể tinh chỉnh nó dựa trên cách sử dụng của mình. Ngoài ra, chú thích dữ liệu không còn là một quy trình hoàn toàn thủ công và có thể tránh được một lượng lớn chú thích thủ công bằng cách sử dụng các phương pháp như học bán giám sát.
Mục tiêu tổng thể của chương này trước tiên là cung cấp cho người đọc một số hiểu biết trực quan về các vấn đề trong lĩnh vực trí tuệ nhân tạo, sau đó khám phá sự giao thoa giữa trí tuệ nhân tạo và mật mã.
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize pri- vacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi ap- plications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI integrates AI’s art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder in- clusivity, aiming to explore AI’s potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through tech- nologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integra- tion and privacy computing, while its products, such as ‘Scopechat’ and ‘Scopescan’, showcase its dedication to merging AI capabilities with blockchain technology to serve a broad user base including over 311 B2B clients and 237 K individual users.
3.1.4 3 commas
Website: https://3commas.io/
One liner: 3 Commas is a comprehensive cryptocurrency trading platform that lever- ages AI to enhance trading strategies and efficiency.
Description: 3 Commas utilizes sophisticated AI algorithms to provide automated trading bots and smart trading terminals, enhancing trading strategies and risk man- agement across various market conditions on 16 major cryptocurrency exchanges. Its integration with TradingView and features like DCA, grid bots, and signal bots for strategy execution underscore its AI-centric approach to maximizing crypto trading efficiency and portfolio management.
3.1.5 9 VRSE
Website: https://www.linkedin.com/company/9vrse-inc
One liner: 9 VRSE - Bridging virtual worlds with blockchain technology for immersive gaming and content monetization.
Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through ‘Kitty Krew’, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain explo-
ration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 con- tent more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employing advanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double- spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fight- ers on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto tech- nologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a plat- form where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party Computation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.14 Aleo
Website: https://aleo.org/
One liner: Aleo leverages zero-knowledge proofs to enable fully private applications on a scalable, privacy-first blockchain.
Description: Aleo leverages zero-knowledge proofs (ZKPs) in its layer-1 blockchain platform to enable the creation of decentralized applications that emphasize user privacy and data security, without compromising scalability or security. Through its na- tive programming language, Leo, and infrastructure like snarkOS and snar




