SignalPlus宏观分析特别版: Negative Revisions
8 giờ trước

Bản gốc: Một quỹ đạo kỳ dị
Năm 1999, Ray Kurzweil đưa ra dự đoán sau:
Trong năm 2009, máy tính sẽ là máy tính bảng hoặc thiết bị nhỏ hơn với chất lượng cao nhưng màn hình truyền thống;
Vào năm 2019, máy tính sẽ "về cơ bản là vô hình", với hầu hết hình ảnh được chiếu trực tiếp vào võng mạc;
Vào năm 2029, máy tính sẽ giao tiếp thông qua các đường dẫn thần kinh trực tiếp.
Nhìn vào sự phát triển của trí tuệ nhân tạo, robot và sản xuất trong 20 năm qua, đặc biệt là tiến bộ gần đây của AIGC, có một số dấu hiệu cho thấy sự phát triển của công nghệ đang tăng tốc hướng tới điểm kỳ dị.
Điểm kỳ dị ban đầu có nghĩa là "điểm kỳ dị, nổi bật và hiếm có", và những ý nghĩa này dần dần được mở rộng sang khoa học tự nhiên, lần đầu tiên được áp dụng cho lĩnh vực toán học, sau đó được mở rộng sang lĩnh vực vật lý và thiên văn học. Các phiên bản khác nhau của các dự đoán về "điểm kỳ dị công nghệ" đã xuất hiện sau đó.

Năm 1958, khái niệm "điểm kỳ dị công nghệ" lần đầu tiên được đề xuất bởi nhà toán học người Ba Lan Stanisław Marcin Ulam: "Sự tăng tốc của quá trình lặp lại công nghệ và sự thay đổi lối sống của con người dường như đã thay đổi tiến trình lịch sử của chúng ta. mà không có gì như chúng ta biết sẽ tiếp tục", và thế giới sẽ bị đảo lộn.
Năm 1993, nhà khoa học máy tính và nhà văn khoa học viễn tưởng Vernor Vinge đã viết trong bài báo "Điểm kỳ dị công nghệ sắp tới" rằng sự xuất hiện của "Điểm kỳ dị công nghệ" sẽ đánh dấu sự xuất hiện của con người. sự xuất hiện của một "điểm kỳ dị công nghệ", khi các siêu trí tuệ mới sẽ tiếp tục tự nâng cấp và đạt được tiến bộ công nghệ với tốc độ đáng kinh ngạc.
Năm 2005, Ray Kurzweil, người sáng lập kiêm chủ tịch của Đại học Singularity và là giám đốc kỹ thuật của Google, đã điều chỉnh lại khái niệm "điểm kỳ dị kỹ thuật" trong cuốn sách "The Singularity Is Near" của mình, cũng gần với khái niệm mà chúng ta quen thuộc hơn và ở mức độ time dự đoán rằng điểm kỳ dị công nghệ sẽ xuất hiện vào năm 2045. Ông tin rằng "điểm kỳ dị công nghệ" đề cập đến những thay đổi không thể đảo ngược mà những thay đổi công nghệ nhanh chóng và sâu rộng sẽ gây ra cho cuộc sống con người trong tương lai, chủ yếu đề cập đến sự phát triển nhanh chóng của trí tuệ nhân tạo. Điểm kỳ dị sẽ cho phép chúng ta vượt qua giới hạn của cơ thể và bộ não sinh học, và trong tương lai sẽ không có sự phân biệt giữa con người và máy móc.
Năm 2013, Anders Sandberg, một nhà nghiên cứu cấp cao tại Viện Tương lai Nhân loại tại Đại học Oxford, đã mở rộng phạm vi của "điểm kỳ dị công nghệ", sự phát triển và thay đổi công nghệ như vậy có thể được gọi là "điểm kỳ dị công nghệ".
Vào ngày 30 tháng 11 năm 2022, OpenAI đã phát hành ChatGPT, một giao diện đàm thoại và mô hình ngôn ngữ quy mô lớn. Đối với nhiều người, đây là một thời điểm mang tính cách mạng. Đầu ra của nó thật tuyệt vời, tiết kiệm thời gian và các câu trả lời đều đúng một cách thuyết phục (khi OpenAI cho rằng câu trả lời là an toàn).

Điều đáng chú ý là bạn có thể nhận được câu trả lời không hoàn hảo nhưng hiệu quả với LLM ngay hôm nay chỉ trong vài giây mà lẽ ra các chuyên gia tên miền phải mất vài phút cân nhắc và hàng giờ tranh luận trên các diễn đàn trực tuyến.
Chatbot luôn là người bạn đồng hành mà mọi người khao khát. Động lực đằng sau bài kiểm tra Turing có thể là muốn có một chatbot không phá vỡ sự đắm chìm.
Điều còn lại cần được kiểm tra là liệu con người, với tư cách là động vật xã hội, có thể được tăng cường bằng bộ não kỹ thuật số hay không. Chúng ta cùng nhau săn bắn, cùng nhau trồng trọt và xã hội, hiện có thể được mô tả là vùng đệm rộng lớn của những người quản lý và vận hành máy móc quy mô công nghiệp, mang tính xã hội hơn bao giờ hết.
Con người tối ưu hóa con đường ít kháng cự nhất, chọn sao chép hoặc “Google” những kiến thức khác nhau mà họ có thể có được thông qua tư duy phản biện và thất bại lặp đi lặp lại. Sự ra đời của ChatGPT: Học sinh có thể sử dụng LLM để viết bài cho họ, đạt điểm cao. Stack Overflow có thể bị Sybil tấn công vì lợi ích cá nhân và khán giả (lập trình viên) bằng cách nào đó có thể tuân theo bản giao hưởng của deepfakes. Script kiddies có thể chỉ ra rằng ChatGPT là phần mềm độc hại. Việc sử dụng LLM chủ đạo có làm tê liệt khả năng làm việc hiệu quả của chúng ta, đặc biệt là về tư duy hợp lý, hiệu quả và khác biệt không?
Tác động sâu sắc nhất mà AI có thể có là trong văn hóa phân bổ vốn nhân lực. Một ý kiến gần đây mô tả độc đáo phản ứng với ChatGPT:
Những người hạnh phúc nhất là những người sửng sốt khi phát hiện ra rằng chiếc máy rõ ràng đã hoàn thành nhiệm vụ viết.
Cho đến nay, mọi thứ đều như mong đợi. Nếu bạn nhìn lại lịch sử, mọi người thường đánh giá quá cao tác động ngắn hạn của các công nghệ truyền thông mới và đánh giá quá thấp tác động lâu dài của chúng. Điều tương tự cũng xảy ra với báo in, phim ảnh, đài phát thanh, truyền hình và Internet.
Khi cố gắng hiểu tác động của AI, chúng tôi cố gắng cô lập sự gián đoạn ngắn hạn để suy đoán về hậu quả trung và dài hạn.
Phải nói rằng, có lẽ một cách hay để mô tả cuộc biểu tình này là thông qua động lực thị trường. Các trợ lý AI biến đổi sự khan hiếm của việc sáng tạo nội dung, do đó phần nào trở thành một nhà tạo lập thị trường. Mỗi khi một "vị thần" trong câu tục ngữ rời khỏi "cái chai", người tiêu dùng sẽ được lợi bất đối xứng bằng cách định giá lại thị trường và loại bỏ dần các nhà cung cấp dưới mức tối ưu. Đổi lại, các nhà cung cấp sản xuất dựa trên AI đã tích lũy được nhiều vốn hơn theo thời gian.
Người ta có thể lập luận rằng có sự độc quyền của các công ty có đủ khả năng thu thập dữ liệu toàn bộ internet để tạo bộ dữ liệu đào tạo. Có lẽ chỉ một số lượng SaaS hạn chế mới đủ khả năng tiêu thụ những tài nguyên như vậy để tạo ra các mô hình ML mới. Nếu thương mại dựa trên ML trở nên không ổn định đủ, thì sẽ có ít người hơn có thể đạt được và duy trì PMF. Trong quá khứ, chúng ta đã bị lừa bởi các chiến thuật tâm lý như HAL 9000, Skynet và Butlerian Jihad.
Nhiều công ty và đại lý thông minh hợp tác về sự khan hiếm trong nền kinh tế AI. Làm thế nào có khả năng xã hội tư bản hiện tại của chúng ta sẽ tạo ra một nhà kỹ trị không có phản hồi tiêu cực có thể loại bỏ dần các giai cấp kinh tế xã hội, các nguyên tắc cơ bản như quyền con người/tài sản hoặc đẩy nhanh một số hình thức hủy diệt hàng loạt?
Nghe có vẻ sáo rỗng, nhưng có những điểm uốn sắp tới cần chú ý sẽ có tác động cơ bản đến cách thức vận hành của xã hội. Một năm kể từ bây giờ, ai đó có thể viết luật nhanh chóng hoặc chứng cuồng hoa tulip về một sản phẩm phụ thuộc vào AI cụ thể. Trong vòng 5-10 năm tới, nền kinh tế sở hữu độc quyền, các hình thức chính phủ hiện có và quyền tự chủ/tiêu dùng cá nhân sẽ bị loại bỏ. Mô hình “Megacorp” có thể vẫn chiếm ưu thế trong suốt quá trình gián đoạn và chúng ta có thể thấy mình đang ở trong “trạng thái mạng” hoặc một cái gì đó giống Orwellian hơn. Tất cả chỉ vì máy tính (có được bằng bất kỳ phương tiện nào) sẽ biên dịch việc sử dụng chung ngôn ngữ tự nhiên của chúng ta để bao hàm nhiều chức năng kinh tế và vận hành của xã hội ngày nay. Bất kể dòng thời gian nào, đây sẽ là một điểm uốn rõ ràng trước "Điểm kỳ dị".
Mô tả hình ảnh
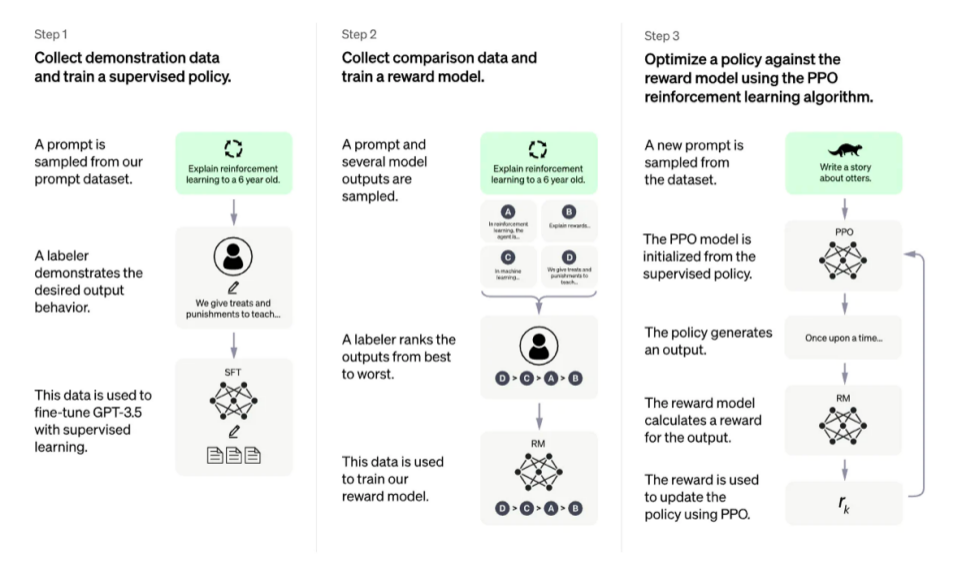
Sơ đồ RLHF của OpenAI
Tuy nhiên, có những thách thức trong việc "hoàn thiện" NLP.
Mặc dù những công nghệ này cực kỳ hứa hẹn và có tác động lớn, đồng thời đã thu hút sự chú ý của các phòng thí nghiệm nghiên cứu lớn nhất về trí tuệ nhân tạo, nhưng vẫn có những hạn chế rõ ràng. Các mô hình này có thể xuất ra văn bản có hại hoặc thực sự không chính xác mà không có sự chắc chắn. Sự không hoàn hảo này thể hiện một thách thức và động lực lâu dài đối với RLHF—hoạt động trong lĩnh vực vấn đề cố hữu của con người có nghĩa là không bao giờ có một vạch đích rõ ràng để vượt qua để một mô hình được đánh dấu là hoàn chỉnh.
Khi triển khai các hệ thống sử dụng RLHF, việc thu thập dữ liệu sở thích của con người rất tốn kém do các yếu tố con người bắt buộc và có chủ ý. Hiệu suất của RLHF chỉ tốt bằng chất lượng của các chú thích do con người tạo ra, có hai loại: văn bản do con người tạo, chẳng hạn như tinh chỉnh LM khởi đầu trong InstructGPT và các nhãn ưa thích của con người giữa các kết quả đầu ra của mô hình.
Tạo văn bản do con người viết tốt để trả lời các lời nhắc cụ thể cực kỳ tốn kém, vì nó thường yêu cầu thuê người bán thời gian (thay vì có thể dựa vào người dùng sản phẩm hoặc nguồn lực cộng đồng). Rất may, kích thước dữ liệu (~50 nghìn mẫu ưu tiên được gắn nhãn) được sử dụng để đào tạo các mô hình phần thưởng cho hầu hết các ứng dụng RLHF không quá đắt. Tuy nhiên, nó vẫn có giá cao hơn một phòng thí nghiệm học thuật có thể chi trả.
Hiện tại, chỉ có một bộ dữ liệu quy mô lớn cho RLHF dựa trên các mô hình ngôn ngữ chung (từ Anthropic) và một số bộ dữ liệu dành riêng cho nhiệm vụ nhỏ hơn (chẳng hạn như dữ liệu tóm tắt từ OpenAI). Thách thức dữ liệu RLHF là sự thiên vị của người chú thích. Một số người chú thích con người có thể không đồng ý, dẫn đến một số phương sai tiềm ẩn trong dữ liệu huấn luyện.
RLHF có thể được áp dụng cho học máy ngoài xử lý ngôn ngữ tự nhiên (NLP). Ví dụ: Deepmind đã khám phá việc sử dụng nó cho các tác nhân đa phương thức. Thử thách tương tự cũng được áp dụng trong trường hợp này:
Học tăng cường có thể mở rộng (RL) dựa trên các chức năng phần thưởng chính xác, không tốn kém để truy vấn. Khi RL có thể được áp dụng, nó đã đạt được thành công lớn, tạo ra AI có thể phù hợp với các thái cực của phân bổ tài năng con người (Silver et al., 2016; Vinyals et al., 2019). Tuy nhiên, chức năng phần thưởng này không được biết đến nhiều đối với nhiều hành vi kết thúc mở mà mọi người thường xuyên tham gia. Ví dụ: hãy xem xét một tương tác hàng ngày yêu cầu ai đó "hãy giữ một chiếc cốc gần bạn". Để một mô hình phần thưởng có thể đánh giá đầy đủ các tương tác như vậy, nó cần phải mạnh mẽ theo nhiều cách mà một yêu cầu có thể được thực hiện bằng ngôn ngữ tự nhiên và nhiều cách để nó có thể được đáp ứng (hoặc không được đáp ứng), trong khi mạnh mẽ đối với các biến số không liên quan của sự thay đổi (màu sắc của cốc) và sự mơ hồ cố hữu của ngôn ngữ ("gần" là gì?) Sự vô cảm.
Do đó, để thấm nhuần các khả năng ở cấp độ chuyên gia rộng hơn thông qua RL, chúng ta cần một cách để tạo ra các hàm phần thưởng chính xác, có thể truy vấn, tôn trọng tính phức tạp, tính thay đổi và tính không rõ ràng của hành vi con người. Thay vì lập trình các chức năng phần thưởng, một tùy chọn là sử dụng máy học để xây dựng chúng. Thay vì cố gắng dự đoán và xác định chính thức các sự kiện khen thưởng, chúng ta có thể yêu cầu con người đánh giá các tình huống và cung cấp thông tin được giám sát để tìm hiểu các chức năng khen thưởng. Đối với những tình huống mà con người có thể đưa ra những đánh giá như vậy một cách tự nhiên, trực quan và nhanh chóng, RL sử dụng các mô hình phần thưởng học tập như vậy có thể cải thiện hiệu quả các tác nhân (Christiano và cộng sự, 2017; Ibarz và cộng sự, 2018; Stiennon và cộng sự, Năm 2020;)
Nhiều yếu tố dẫn đến Điểm kỳ dị vẫn chưa được phát triển và chúng ta có thể xác định chúng là gì một cách chắc chắn hơn khung thời gian cần thiết để thực hiện chúng. Chris Lattner đã đề cập đến "thành phần chuyên gia được kiểm soát thưa thớt" từ POV của anh ấy:
Để mô tả ngắn gọn, có lẽ có một trung gian quản lý và kết hợp ý kiến đóng góp của nhiều "chuyên gia".
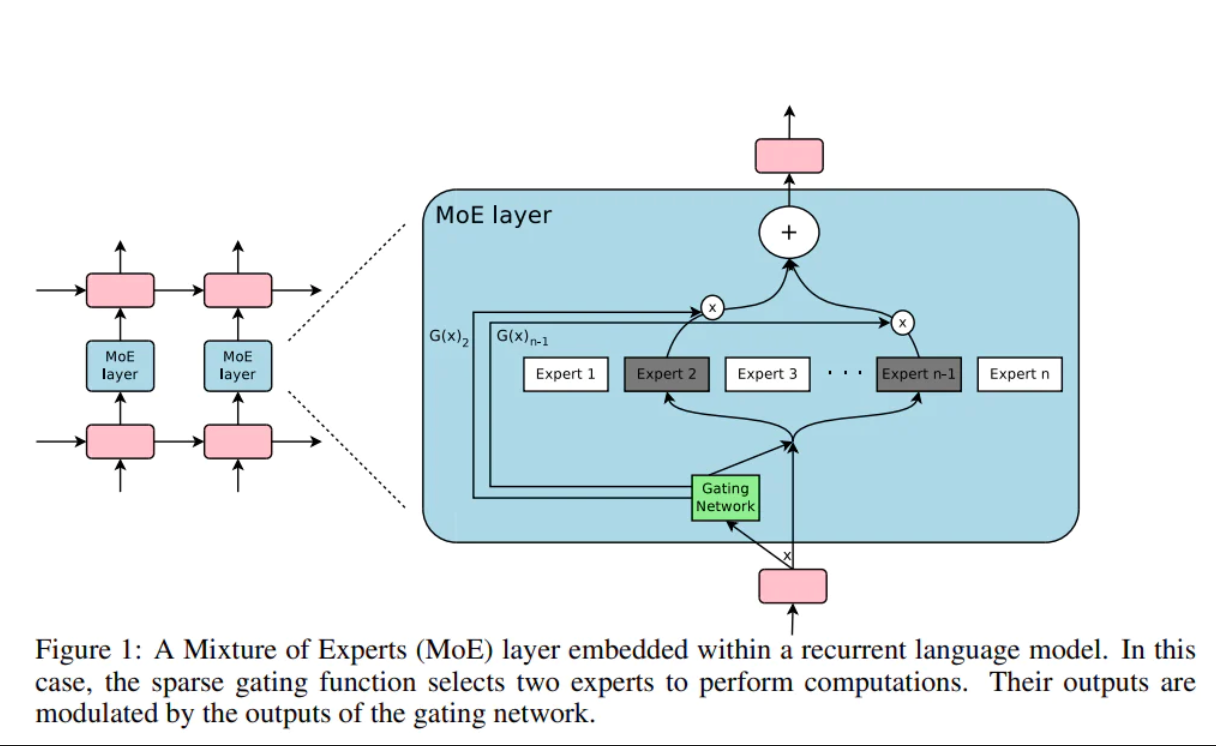
Điều này cung cấp một không gian thiết kế rộng rãi để nghiên cứu thêm. Có lẽ tầng giữa nên chọn cách khác.
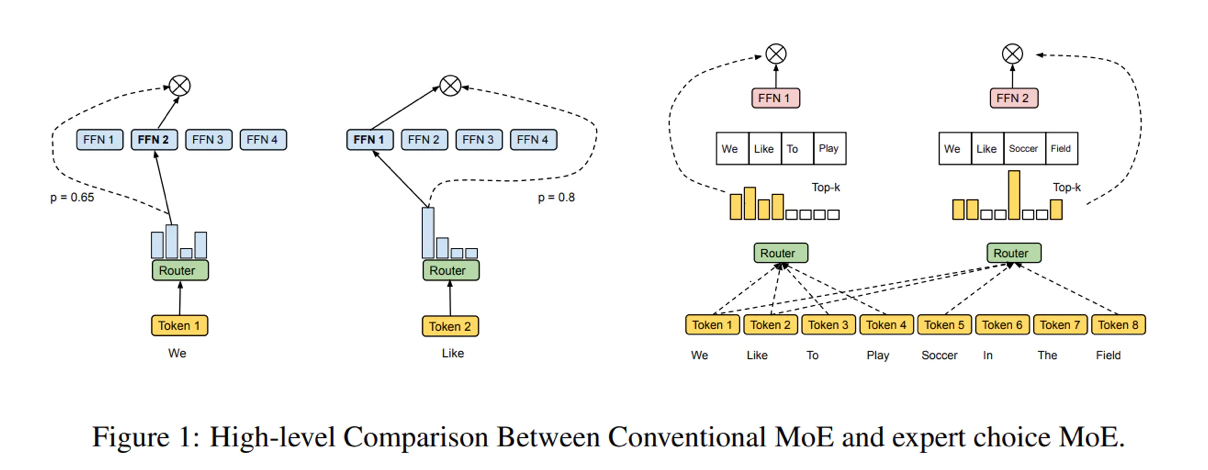
Ví dụ, sử dụng dữ liệu không gian.
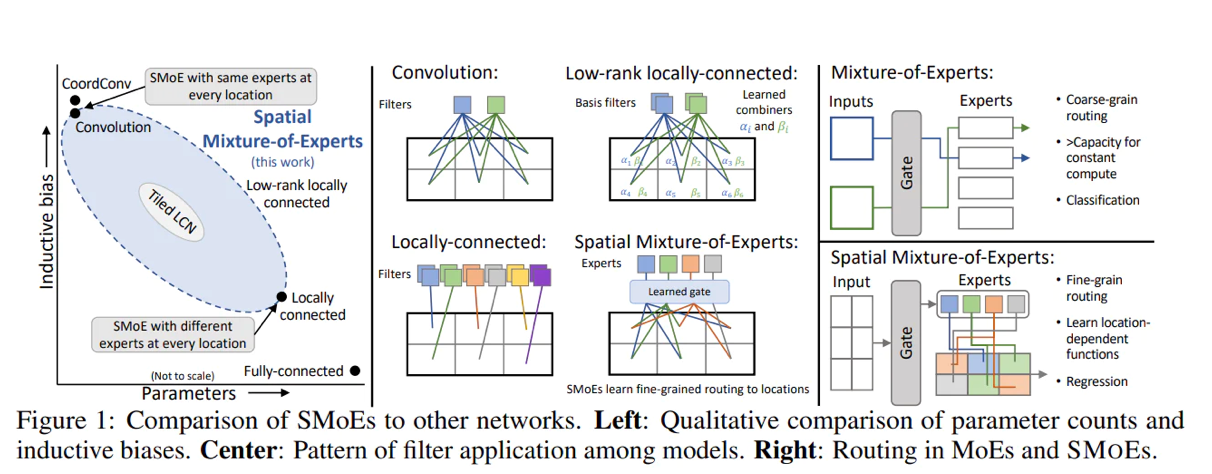
Mô tả hình ảnh
chữ
chữ
Phản hồi từ ngành sản xuất là tốt, nhưng ngành y tế có nhu cầu lớn nhất. Ngay bây giờ, chúng tôi là người đầu tiên sử dụng cảm biến sinh học bán lẻ. Theo thời gian, mật mã đồng hình sẽ cho phép máy học tận dụng lượng dữ liệu sức khỏe khổng lồ. Chúng ta đã sử dụng nguồn lực cộng đồng để tiêu thụ ma túy trong hàng chục nghìn năm, nhưng vẫn còn phải xem chúng ta sẽ cùng tồn tại như thế nào với trí tuệ nhân tạo có thể quản lý liều lượng các chất tùy ý trong bất kỳ khoảng thời gian nào. Đồng thời, mã hóa đồng hình vẫn không được sử dụng do các vấn đề về hiệu quả.
Google Brain vừa phát hành Robotics Transformer-1. Trong lần phát hành đầu tiên, nó có thể chỉ là một nhánh thực hiện các tác vụ đơn giản, nhưng rõ ràng là có thể lặp lại với nhiều hoạt động được mã hóa hơn trong một môi trường xây dựng chung. Vì nền kinh tế toàn cầu tập trung vào vận chuyển hàng hóa, nên sẽ hợp lý nếu hơn 100 tàu container "không phát thải" cuối cùng được đóng trong các cơ sở như vậy, so với khoảng 6.000 tàu hiện có trên thế giới. Nó cũng sẽ là một sự thay đổi lớn của thủy triều trong một cuộc khủng hoảng nhà ở, nơi các sắc lệnh phân vùng cho phép nó có hiệu lực đầy đủ.
Ngoài ra, tôi phải đề cập đến kế hoạch Alberta, 12 bước hợp lý để phát triển năng lực AGI.
Thuật ngữ "lộ trình" ngụ ý vẽ một con đường tuyến tính, một loạt các bước nên được thực hiện và thông qua theo trình tự. Điều đó không hoàn toàn sai, nhưng nó không nhận ra những điều không chắc chắn và cơ hội của nghiên cứu. Các bước chúng tôi phác thảo dưới đây có nhiều mối quan hệ phụ thuộc lẫn nhau chứ không phải là một chuỗi các bước từ đầu đến cuối. Lộ trình đề xuất một trật tự tự nhiên, nhưng thực tế thường đi chệch khỏi trật tự này. Nghiên cứu hữu ích có thể được thực hiện bằng cách nhập hoặc đính kèm vào bất kỳ bước nào. Ví dụ, nhiều người trong chúng ta gần đây đã đạt được những tiến bộ thú vị trong kiến trúc tích hợp, mặc dù những tiến bộ này chỉ xuất hiện ở bước cuối cùng của trình tự.
Đầu tiên, chúng ta hãy cố gắng có được một ý tưởng chung về lộ trình và cơ sở lý luận của nó. Có mười hai bước, có tiêu đề như sau:
1. Biểu diễn I: Học liên tục có giám sát với các tính năng đã cho. 2. Biểu diễn II: Khám phá tính năng được giám sát. 3. Dự đoán Một: Học dự đoán Hàm giá trị tổng quát hóa liên tục (GVF). 4. Điều khiển I: Điều khiển diễn viên-nhà phê bình liên tục. 5. Dự đoán hai: phần thưởng trung bình cho việc học GVF. 6. Kiểm soát II: Các vấn đề kiểm soát đang diễn ra. 7. Kế hoạch I: Một kế hoạch cho phần thưởng bình đẳng. 8. Nguyên mẫu-AI I: Học tăng cường một bước dựa trên mô hình với xấp xỉ hàm liên tục. 9. Kế hoạch II: Kiểm soát và Thăm dò Tìm kiếm. 10. Nguyên mẫu-AI II: Quá trình STOMP. 11. Nguyên mẫu-AI III: Gỗ sồi. 12. Nguyên mẫu-IA: Khuếch đại thông minh.
Các bước này tiến triển từ việc phát triển các thuật toán mới cho các khả năng cốt lõi (để biểu diễn, dự đoán, lập kế hoạch và kiểm soát) đến việc kết hợp các thuật toán này để tạo ra các hệ thống nguyên mẫu hoàn chỉnh cho AI dựa trên mô hình, liên tục.
Mô tả hình ảnh

Đầu ra của ChatGPT
Kế hoạch của Alberta được mô tả ở trên là một tình huống lý tưởng. Con người vốn đã phức tạp, với tư cách là những cá nhân sử dụng các công cụ mạng thần kinh thưa thớt; với tư cách là nhóm, với các đặc tính tự tổ chức, học tập xã hội và kỹ thuật môi trường. Trong những phát triển gần đây về mật mã và điện toán phân tán (đối nghịch), con người chỉ tự chủ đến mức duy trì trạng thái (lịch sử) toàn cầu hoàn chỉnh của Turing. Ngoài ra còn có một hiện tượng được gọi là Mechanical Turk. Vấn đề là các sản phẩm AI giảm trong bất kỳ khoảng thời gian nào và sẽ có một hệ sinh thái dành cho nhà phát triển trưởng thành có thể vượt trội so với các cấp độ hiện có nhờ thực thi phối hợp, được tăng cường bởi các công cụ AI đương thời và công việc có thể kiểm chứng.
Điều này dẫn đến thử nghiệm suy nghĩ hiện tại: Chúng ta thậm chí có cần đạt được mọi điểm uốn được dự đoán trước The Singularity™ không? Đối với mọi cải tiến độc quyền trong đào tạo mô hình thương mại, có thể có một cách khả thi để triển khai nó trong phạm vi công cộng. StableDiffusion đã khơi dậy các cuộc trò chuyện xung quanh khái niệm này. Crowdsourcing đã tăng tốc đáng kể trong thập kỷ qua (bằng chứng là Twitch Plays Pokemon, Social Networks và The DAO) rằng điểm kỳ dị đã là một sự phân tâm. Giống như các giải pháp mở rộng quy mô Ethereum cố gắng sử dụng mật mã như zk-SNARK để giảm nhu cầu cơ sở hạ tầng của mạng, chúng tôi sẽ cố gắng triển khai các giải pháp nhẹ giúp giảm nhu cầu sử dụng vũ lực và kiếm tiền từ AI của các doanh nghiệp lớn hiện có.
Trên thực tế, một trong những cách tốt nhất để bác bỏ mô hình OpenAI là các hệ thống vốn xã hội tương tự trên thị trường tài chính và mạng xã hội hoạt động theo cách có thể dự đoán được. Twitter tổng hợp tin tức vì người dùng của nó có thể phát và khuếch đại tin tức đó trên toàn cầu với các cá nhân hợp pháp. Với các xu hướng toàn cầu như phong tỏa do COVID và chính sách tiền tệ của ngân hàng trung ương, các cổ phiếu tăng trưởng có thể tăng và giảm mạnh. Không cần nhiều trí tưởng tượng để tưởng tượng một công ty khởi nghiệp có thể biểu hiện một PMF giống như AI như một cộng đồng tự điều chỉnh, tự điều phối trong một khoảng thời gian ngắn. Chi phí vận hành có khả năng lên tới hàng trăm tỷ đô la có thể được khai thác trên nhiều lĩnh vực thông qua công nghệ hiện có và phát triển kinh doanh hơn nữa.
Trong phim truyền hình Westworld, một hệ thống trí tuệ nhân tạo có tên Rehoboam áp đặt trật tự cho các vấn đề của con người bằng cách phân tích các tập dữ liệu lớn để thao túng và dự đoán tương lai. Kể từ cuộc Cách mạng Công nghiệp, những đổi mới đột phá đã nhiều lần xuất hiện bên ngoài các bộ máy quan liêu; ngày nay, chúng đang diễn ra với tốc độ ngày càng tăng. Độ sâu và phạm vi của phạm vi công cộng đã tăng lên trong những thập kỷ gần đây và nhiều công nghệ, bất kể chúng mang tính thương mại như thế nào, đang bị buộc phải là nguồn mở.




