SignalPlus宏观分析特别版: Negative Revisions
7 hours ago

Original Author: Mohamed Baioumy & Alex Cheema
Translation: BeWater

Since the full report is quite long, we have split it into two parts for publication. In the first part, the authors introduced the core framework, specific examples, and opportunities for builders in AI x Crypto. This second part mainly discusses the working mode and challenges of machine learning. If you want to view the full translated report, please click this link.
Before delving into the intersection of AI and cryptocurrency, it's important to separately introduce some concepts in the field of artificial intelligence. Since this report is written for readers in the cryptocurrency field, not all readers have a profound understanding of AI and machine learning concepts. However, understanding these concepts is crucial in order for readers to assess which ideas in the intersection of AI and cryptocurrency are meaningful and accurately evaluate the technical risks of projects. This section focuses on introducing the concepts of artificial intelligence, as well as the relationship between artificial intelligence and cryptocurrency.

Overview of the topics covered in this section:
Machine learning (ML) is a branch of artificial intelligence, where machines can make decisions based on data without explicit programming.
The ML process consists of three steps: data, training, and inference.
Training models can be computationally expensive, while inference is relatively cheap.
There are three main types of learning: supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning involves learning from examples provided by a teacher. The teacher can show the model pictures of dogs and tell it that they are dogs. The model can then learn to differentiate dogs from other animals.
However, many popular models, such as LLMs (e.g. GPT-4 and LLaMa), are trained through unsupervised learning. In this learning mode, the teacher does not provide any guidance or examples. Instead, the model discovers patterns in the data through learning.
Reinforcement learning (trial and error learning) is primarily used for continuous decision-making tasks, such as robot control and games (such as chess or Go).
In 1956, some of the smartest people at the time gathered together for a workshop. Their goal was to propose general principles of intelligence. They pointed out:
"Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it."
In the early days of artificial intelligence development, researchers were filled with optimism. In a way, their goal was artificial general intelligence (AGI), ambitious. We now know that these researchers did not succeed in creating artificial intelligence agents with general intelligence. Artificial intelligence researchers in the 1970s and 1980s were the same. During that period, artificial intelligence researchers attempted to develop "knowledge-based systems".
The key idea behind knowledge-based systems is that we can write very precise rules for machines. Essentially, we extract very specific and precise domain knowledge from experts and write it down in the form of rules for machines to use. Then, machines can use these rules to reason and make correct decisions. For example, we can try to extract all the principles of chess from Magnus Carlson and then build an artificial intelligence to play chess.
However, accomplishing this is very difficult, and even if possible, requires a lot of human effort to create these rules. Just think about how to write the rules for recognizing a dog into a machine? How can a machine go from pixels to knowing what a dog is?
The latest advancements in artificial intelligence come from a branch called "machine learning". In this paradigm, instead of writing precise rules for machines, we use data to let the machines learn from it. Modern artificial intelligence tools that use machine learning can be seen everywhere, such as GPT-4, FaceID on iPhones, game robots, Gmail spam filters, medical diagnosis models, self-driving cars, and so on.
The machine learning pipeline can be divided into three main steps. Once we have the data, we need to train the model, and once we have the model, we can use it. The usage of the model is called inference. So, these three steps are data, training, and inference, respectively.
In a nutshell, the data step involves finding relevant data and preprocessing it. For example, if we want to build a model for classifying dogs, we need to find images of dogs and other animals so that the model can learn what is a dog and what is not. Then, we need to process the data and ensure that the data is in the correct format for the model to learn correctly. For example, we may require consistent image sizes.
The second step is training, where we use the data to teach the model what it should be like. What are the equations inside the model? What are the weights of the neural network? What are the parameters? What computations are being performed? If the model performs well, we can then evaluate its performance and start using it. This brings us to the third step.
The third step is called inference, where we simply use the neural network. For example, we give the neural network an input and ask a question: can it produce an output through inference?
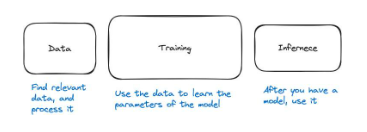
Figure 28: The three main steps of the machine learning pipeline are data, training, and inference
Data
Now let's dive into each step. First: Data. Broadly speaking, this means we must collect data and preprocess it.
Let's take an example. If we want to build a model for dermatologists (doctors who specialize in treating skin diseases) to use. First, we have to collect data of many faces. Then, we have professional dermatologists evaluate if there are any skin diseases. Now there might be several challenges. First, if all the data we have only includes faces, the model will have a hard time recognizing any skin conditions in other parts of the body. Second, the data might have biases. For example, the majority of the data might consist of images with a certain skin color or tone. Third, dermatologists might make mistakes, which means we will have incorrect data. Fourth, the data we obtain might violate privacy.

We will discuss deeper data challenges in Chapter 2. However, this should give you an idea that collecting good data and preprocessing it is quite challenging.

Figure 29: Illustrations of two popular datasets. MNIST contains handwritten digits, while ImageNet contains millions of annotated images of various categories
In machine learning research, there are many famous datasets. Common ones include:
MNIST Dataset
Description: Contains 70,000 handwritten grayscale images of digits (0-9)
Use cases: Primarily used for handwriting recognition in computer vision. It is a beginner-friendly dataset commonly used in the field of education.
ImageNet
Description: A large database with over 14 million labeled images belonging to more than 20,000 categories.
Use cases: Used for training and benchmarking object detection and image classification algorithms. The annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is a significant event driving the development of computer vision and deep learning technologies.
IMDb Reviews:
Description: Consists of 50,000 movie reviews from IMDb, divided into two sets: training and testing. Each set contains an equal number of positive and negative reviews.
Use cases: Widely used for sentiment analysis tasks in natural language processing (NLP). It helps in developing models that can understand and classify emotions (positive/negative) expressed in text.
Obtaining large, high-quality datasets is crucial for training well-performing models. However, this can be challenging, especially for smaller organizations or individual researchers. Due to the value of data, large institutions typically do not share their data as it provides a competitive advantage.

Training
The second step of the pipeline is training the model. So, what does training a model exactly mean? First, let's look at an example. A machine learning model (after training) usually consists of two files. For example, LLaMa 2 (a large language model, similar to GPT-4) is two files:
Parameters, a 140 GB file that includes numbers.
run.c, a simple file (about 500 lines of code).
The first file contains all the parameters of the LLaMa 2 model, and run.c contains instructions on how to perform inference (using the model). These models are neural networks.
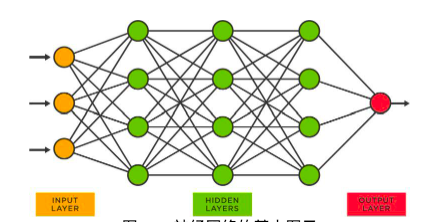
Figure 30: Basic Diagram of Neural Network
In a neural network like the one above, each node has a bunch of numbers. These numbers are called parameters and are stored in a file (surprise!) called parameters. The process of obtaining these parameters is called training. Here is a highly summarized process.
Imagine training a model to recognize digits (from 0 to 9). We first collect data (in this case, we can use the MNIST dataset). Then we start training the model.
We take the first data point, which is "5".
Then, we pass the image ("5") to the network. The network performs mathematical operations on the input image.
The network outputs a number between 0 and 9. This output is the current network's prediction for that image.
Now, there are two possibilities. Either the network is correct (it predicted "5") or it is wrong (any other number).
If it predicts the correct number, we don't have to do anything.
If the predicted number is incorrect, we go back to the network and make small modifications to all the parameters.
After making these small modifications, we try again. Technically, the network now has new parameters, so the predicted result will be different as well.
We do this for all data points until the network is basically correct.
This process is essentially sequential. We first pass a data point through the entire network to see how it predicts, and then update the weights of the model.
The training process can be more comprehensive. First, we must select the model architecture. What type of neural network should we choose? Not all machine learning models are neural networks. Secondly, after determining which architecture is most suitable for us, or at least the architecture we think is most suitable, we need to determine the training procedure. For example, in what order will we pass the data to the network?
Third, we need hardware setup. What kind of hardware (CPU, GPU, TPU) should we use? And how should we train with it?
Finally, while training the model, we want to validate if the model is really good. We want to test if the model provides the desired output at the end of training. Spoiler alert (not really a spoiler), training a model is very computationally expensive. Even the slightest inefficiency can result in huge costs. As we will see later, especially for large models like LLM, inefficient training can cost you millions of dollars.
In Chapter 2, we will discuss in detail the challenges faced in training models.
Inference
The third step of the machine learning pipeline is inference, which means using the model. When I use ChatGPT and get a response, the model is performing inference. When I unlock my iPhone with facial recognition, the Face ID model recognizes my face and unlocks the phone. The model is performing inference. The data is there, the model is trained, and now that the model is trained, we can use it, and using it is inference.
Strictly speaking, inference is the same as the predictions made by the network during the training phase. Remember, a data point goes through the network and makes a prediction. Then the model parameters are updated based on the quality of the prediction. The process of inference works the same way. So, compared to training, the computational cost of inference is very low. Training LLaMa might cost tens of millions of dollars, but inference only costs a fraction of that.
Compared to training, the computational cost is lower. Training LLaMa might cost tens of millions of dollars, but performing one inference only costs a fraction of that.

There are several steps in the reasoning process. First, before it is used in actual production, we need to test it. We reason with data that was not seen during the training phase to validate the quality of the model. Second, when we deploy a model, there are hardware and software requirements. For example, if I have a facial recognition model on my iPhone, the model can be placed on Apple's servers. However, this is inconvenient because every time I want to unlock my phone, I have to access the Internet and send a request to Apple's servers for inference on the model. However, if you want to use this technology at any time, the facial recognition model must be present on your phone, which means the model must be compatible with the hardware type on your iPhone.
Lastly, in practice, we must also maintain this pattern. We must constantly make adjustments. The models we train and use are not always perfect. The hardware and software requirements are also constantly changing.
The machine learning pipeline is iterative
So far, I have designed this pipeline to be a sequence of three steps. You acquire data, process data, clean data, everything goes smoothly, then you train the model, and after the model training is complete, you reason with it. This is the beautiful picture of machine learning in practice. In reality, machine learning requires a lot of iteration. Therefore, it is not a chain, but several cycles as shown in the following figure.
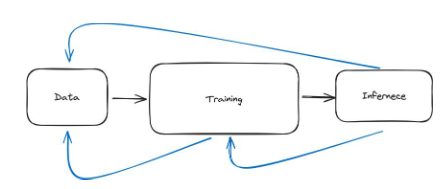
Figure 31: The machine learning pipeline can be conceptually understood as a chain composed of three steps: data, training, and inference. However, in practice, this process is more iterative, as shown by the blue arrows.
To understand this, let's consider a few examples. For instance, we might collect data for a model and then attempt to train it. During the training process, we may realize that we need more data. This means we have to pause the training, go back to the data step, and gather more data. We may need to preprocess the data again or perform some form of data augmentation. Data augmentation is like giving a makeover to the data, creating new appearances from the existing set. Imagine you have a photo album, and you want to make it more interesting. You make several copies of each photo, but in each copy, you make some small changes—maybe you rotate one photo, enlarge another, or alter the lighting of another. Now, your album has more variation, but you haven't actually taken any new photos. For example, if you are training a model to recognize dogs, you might horizontally flip each photo and provide it to the model as well. Alternatively, we may change the pose of the dog in the photo, as shown in the image below. From the model's perspective, this increases the dataset, but we haven't collected more data from the real world.


Figure 32: Data augmentation example. Multi-point expansion of raw data points without the need to collect more unique data points from around the world
A second more evident example of iteration is when we actually train a model and then use it in practice, i.e., for inference, we may find that the model performs poorly or has biases in practice. This means we have to stop the inference process, go back and retrain the model to address these issues, such as bias and overfitting.
A third and also very common step is that once we use the model in practice (for inference), we eventually modify the data steps because inference itself generates new data. For example, consider building a spam filter. First, we collect data, which in this case is a set of spam and non-spam emails. When the model is trained and used in practice, I might receive a spam email in my inbox, which means the model made a mistake. It didn't classify it as spam, but it was. So, when a Gmail user selects "This email is spam," it generates a new data point. Afterward, all these new data points go into the data steps, and then we can improve the model's performance by doing more training.
Another example is imagining an AI playing chess. The data we train the AI for playing chess with is a large number of chess games and the results of who wins and who loses. But when this model is used for actual chess playing, it generates more data for the AI. This means, we can go back from inference to data and utilize these new data points to further improve my model. This idea of connecting inference and data applies to many scenarios.
This section aims to give you a high-level understanding of the process of building a machine learning model, which is highly iterative. It's not like "Oh, we just get the data, train the model once, and put it into production."

We will introduce three main types of machine learning models.
Supervised Learning: "Teacher, teach me the method"
Unsupervised Learning: "Just find the hidden patterns"
Reinforcement Learning: "Try it out and see what works"
Supervised Learning
"Teacher, teach me the method"
Imagine you are teaching a child to distinguish between cats and dogs. You (the knowledgeable teacher) show them many pictures of cats and dogs and tell them which is which each time. Eventually, the children learn to distinguish on their own. This is essentially how supervised learning works in machine learning.
In supervised learning, we have a large amount of data (such as pictures of cats and dogs), and we already know the answers (the teacher tells them which is a dog and which is a cat). We use this data to train a model. The model looks at many examples and effectively learns to mimic the teacher.
In this example, each picture is an original data point. The answer (dog or cat) is called a "label". So, this is a labeled dataset. Each data point consists of an original image and a label.
This approach is conceptually simple and powerful. It has many applications in medical diagnosis, autonomous vehicles, and stock price predictions using supervised learning models.
However, it can be imagined that this approach faces many challenges. For example, we not only need to acquire a large amount of data but also need labels. This can be very expensive. Companies like Scale.ai provide valuable services in this regard. Data annotation raises many challenges for robustness. The people labeling the data may make mistakes or have different opinions about the labels. It is not uncommon for 20% of labels collected from humans to be unusable.

Unsupervised Learning
"Just find hidden patterns"
Imagine you have a large basket filled with various fruits, but you're not familiar with all of them. You start classifying them based on their appearance, size, color, texture, and even smell. You're not quite sure of the name of each fruit, but you notice that some fruits are similar to each other. In other words, you discover some patterns in the data.
This situation is similar to unsupervised learning in machine learning. In unsupervised learning, we give the model a bunch of data (such as combinations of various fruits), but we don't tell the model what each data point is (we don't label the fruits). Then, the model examines all of this data and tries to find patterns or groups on its own. It may group the fruits based on color, shape, size, or any other features it deems relevant. However, the features the model finds are not always meaningful. This leads to many challenges, which we'll see in Chapter 2.
For example, the model might end up grouping bananas and plantains together because they are both long and yellow, while apples and tomatoes might be grouped separately because they are both round and possibly red. The key here is that the model is figuring out these groupings without any prior knowledge or labels—it's learning from the data itself, just like how you classify unknown fruits into different groups based on observable features.
Unsupervised learning is a cornerstone of many popular machine learning models, such as large language models (LLMs). ChatGPT doesn't need humans to teach it how to say each sentence by providing labels. It simply analyzes patterns in the language data and learns to predict the next word.
Many other powerful generative AI models rely on unsupervised learning. For example, Generative Adversarial Networks (GANs) can be used to generate faces (even if the person doesn't exist). See https://thispersondoesnotexist.com/

Figure 33 : The generated image by artificial intelligence comes from https://thispersondoesnotexist.com

Figure 34 : The second generated image by artificial intelligence comes from https://thispersondoesnotexis t.com
The above images are generated by artificial intelligence. We did not teach this model "what a face is". It is trained on a large number of faces, and through clever architecture, we can use this model to generate seemingly real faces. Please note that with the rise of generative artificial intelligence and improvements in the model, it is becoming increasingly difficult to validate the content.

Reinforcement Learning (RL)
"Try it out and see what works" or "Learn from trial and error"
Imagine you are teaching a dog to perform a new trick, like fetching a ball. Every time the dog performs a behavior that is close to what you want, such as running towards the ball or picking it up, you give it a treat. If the dog does something unrelated, like running in the opposite direction, it does not receive any food. Over time, the dog learns that fetching the ball results in a tasty reward, so it continues to do so. This is essentially what reinforcement learning (RL) is in the field of machine learning.
In RL, you have a computer program or agent (like the dog) that learns to make decisions by trying out different things (like the dog trying out different behaviors). If the agent performs a good action (like fetching the ball), it receives a reward (food); if it performs a bad action, it does not receive a reward. Over time, the agent learns to do more of the actions that result in rewards and fewer of the actions that do not. In essence, it maximizes a reward function.
The coolest part is that the agent figures all of this out on its own through trial and error. Now, if we wanted to build an artificial intelligence to play chess, for example, the AI could initially try out moves at random. If it eventually wins a match, it gets a reward. Then, the model learns to make more winning moves.
This can be applied to many problems, especially those that require continuous decision-making. For example, RL methods can be used in robotics and control, chess or Go (like AlphaGo), and algorithmic trading.
RL methods face many challenges. One is that the agent may take a long time to "learn" meaningful strategies. This is acceptable for an AI learning to play chess. But, would you invest your personal funds in an AI algorithmic trading system when the AI starts taking random actions to observe which ones are effective? Or, would you allow a robot to live in your house if it initially takes random actions?

Figure 35: Here are some videos of reinforcement learning agents in the training process: a real robot and a simulated robot
Below are brief descriptions of applications for each type of machine learning.
This chapter provides an overview of the problems in the field of machine learning. We will selectively address certain issues in this field. This is done for two reasons: 1) to provide a concise and comprehensive overview of the challenges in this field, as considering the subtle differences would make the report very long; 2) when discussing the intersection of machine learning and cryptocurrency, we will focus on relevant issues. However, this section is written from the perspective of artificial intelligence. In other words, we will not discuss cryptographic methods in this section.
Overview of topics covered in this section:
Data faces significant challenges, from biases to accessibility. Additionally, malicious attacks at the data level can result in misclassifications of machine learning models.
Model collapses occur when models (e.g. GPT-X) are trained on synthetic data, leading to irreversible damages.
Annotation of data can be very expensive, slow, and unreliable.
Training machine learning models presents many challenges depending on the different architectures.
Model parallelization brings significant challenges such as communication overhead.
Bayesian models can be used to quantify uncertainty. For example, during inference, a model returns its level of certainty (e.g. 80% certainty).
LLM faces special challenges such as hallucination and training difficulties.
Data is crucial for any type of machine learning model. However, the requirements and scale of data vary depending on the methods used. Whether it is supervised learning or unsupervised learning, raw data (unlabeled data) is needed.
In unsupervised learning, only raw data is required, without the need for annotation. This alleviates many problems related to annotated datasets. However, the use of raw data for unsupervised learning still presents many challenges. These include:
Data Bias: When training data cannot represent the real-world scenarios to be simulated, bias occurs in machine learning. This may result in biased or unfair outcomes, such as facial recognition systems performing poorly on certain demographic groups due to underrepresentation in the training data.
Imbalanced Dataset: Often, the data available for training is not evenly distributed among different classes. For example, in a disease diagnosis application, there may be far more "healthy" cases than "diseased" cases. This imbalance can cause the model to perform poorly on minority groups or classes. This issue is distinct from bias.
Quality and Quantity of Data: The performance of machine learning models heavily depends on the quality and quantity of the training data. Insufficient or poor-quality data, such as low-resolution images or noisy audio recordings, can severely affect the model's ability to learn effectively.
Data Availability: Obtaining large-scale, high-quality datasets can be challenging, especially for small-scale institutions or individual researchers. Large tech companies often have an advantage in this regard, leading to disparities in the development of machine learning models.

Data Security: Protecting data from unauthorized access and ensuring its integrity during storage and use is crucial. Security vulnerabilities not only compromise privacy but can also lead to data tampering, affecting model performance.
Privacy Concerns: Handling large amounts of data for machine learning can raise privacy issues, especially when sensitive or personal information is involved. Ensuring data privacy means respecting user consent, preventing data leakage, and complying with privacy regulations such as GDPR. This can be highly challenging (see example below).


Figure 36: A special problem of data privacy arises from the nature of machine learning models. In a regular database, I can have entries about multiple individuals. If my company asks me to delete this information, I can simply remove it from the database. However, when my model is trained, it holds the parameters of almost the entire training data. It is unclear which numbers correspond to which database entries during training.
Model collapse
In unsupervised learning, one particular challenge we want to emphasize is model collapse.
In this paper, the authors conducted an interesting experiment. Models like GPT-3.5 and GPT-4 are trained using all the data available on the internet. However, these models are currently being widely used, so a year later, a large amount of internet content will be generated by these models. This means that future models like GPT-5 will be trained using data generated by GPT-4. What is the effect of training models on synthetic data? They found that training language models on synthetic data leads to irreversible deficiencies in the generated models. The authors of the paper state, "We demonstrate that to preserve the benefits of training on web-scraped large-scale data, we must take this challenge seriously. The value of data collected about real interaction behavior between humans and systems will increase as content generated by LLMs appears in data crawled from the internet."

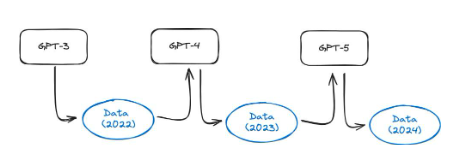
Figure 37: Illustration of model collapse. As the internet content generated by artificial intelligence models becomes more prevalent, the training set for the next generation of models is likely to include synthetic data, as shown in this article.
Please note that this phenomenon is not unique to LLM and may affect various machine learning models and generative AI systems, such as variational autoencoders and Gaussian mixture models.
Now, let's take a look at supervised learning. In supervised learning, we need a labeled dataset. This means that we have the original data itself (an image of a dog) and a label ("dog"). The labels are manually chosen by the model designer and can be obtained through a combination of manual annotation and automated tools. This presents many challenges in practice. These include:
Subjectivity: Deciding on the labels for the data can be subjective, leading to ambiguity and potential ethical issues. What one person considers an appropriate label, another person may have a different perspective.
Labeling variations: Running the same labeling task by the same person (let alone different people) multiple times may yield different labels. This introduces noise approximations to the "ground truth" labels, hence requiring a layer of quality assurance. For example, humans may receive a sentence and be responsible for labeling the sentiment of that sentence ("happy," "sad,"...etc.). The same person may sometimes assign different labels to the exact same sentence. This diminishes the quality of the dataset as it introduces variation in the labels. It is not uncommon for 20% of labels to be unusable in practice.

Lack of expert annotators: For a niche medical application, it may be challenging to obtain a significant amount of meaningful tag data. This is due to the scarcity of personnel (medical experts) who can provide these tags.
Rare events: For many events, it is difficult to obtain a large amount of annotated data due to their rarity. For example, computer vision models for detecting meteors.
High costs: When attempting to collect a large amount of high-quality datasets, the costs can be staggering. Due to the aforementioned issues, the cost of annotating datasets is especially high.
There are also many other challenges, such as dealing with adversarial attacks and label transferability. To give readers some intuitive understanding of the scale of datasets, please refer to the following diagram. Datasets like ImageNet contain 14 million labeled data points.
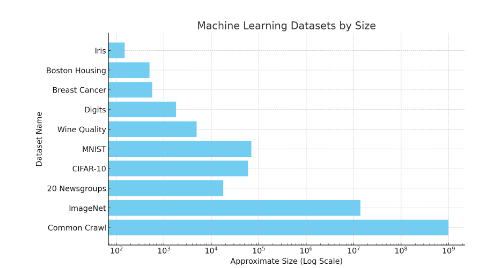
Figure 38: Illustration of the scale of various machine learning datasets. The approximate value for Common Crawl is 1 billion web pages, so the total number of words far exceeds this number. Small datasets (like Iris) contain 150 images. MNIST has approximately 70,000 images. Please note that this is a logarithmic scale.
Data Collection in Reinforcement Learning
In reinforcement learning, data collection is a unique challenge. Unlike supervised learning, where the data is pre-labeled static data, reinforcement learning relies on data generated through interaction with the environment, which often requires complex simulations or real-world experiments. This poses some challenges:
This process can consume significant resources and time, especially for physical robots or complex environments. If a robot is trained in the real world, learning through trial and error can lead to accidents. Alternatively, training the robot by allowing it to learn through trial and error can also be considered.
Sparse and delayed rewards: The agent may need to explore a large number of actions before receiving meaningful feedback, making it difficult to learn effective strategies.
Ensuring the diversity and representativeness of the collected data is crucial; otherwise, the agent may overfit to a narrow set of experiences and fail to generalize. Balancing exploration (trying new actions) and exploitation (using known successful actions) makes data collection more complex and requires sophisticated strategies to effectively gather useful data.
It is worth emphasizing that data collection is directly related to inference. When training a reinforcement learning agent to play chess, we can utilize self-play to collect data. Self-play is like playing against oneself to make progress. The agent engages in games with its own copy, forming a continuous learning loop. This approach is well-suited for data collection as it constantly produces new scenarios and challenges, helping the agent learn from a wide range of experiences. This process can be executed in parallel on multiple machines. Due to the low computational cost of inference (compared to training), the hardware requirements for this process are also low. After collecting data through self-play, all the data will be used to train and improve the model.

Adversarial Data Attacks
Data Poisoning Attack: In this attack, classifiers are deceived by adding perturbations to the training data, resulting in incorrect outputs. For example, someone may add spam elements to non-spam emails. This leads to decreased performance when these data are included in the training of spam filters in the future. This can be addressed by increasing the use of words like "free," "win," "offer," or "token" in non-spam contexts.
Evasion Attack: Attackers manipulate the data during the deployment process to deceive previously trained classifiers. Evasion attacks are the most common in practical applications. The "spoofing attack" against biometric authentication systems is an example of an evasion attack.
Adversarial Attack: This involves modifying legitimate inputs with the aim of fooling the model or causing misclassification using specially designed "noise." Please see the example below, where adding noise to a panda image results in the model classifying it as a gibbon (with 99.3% confidence).
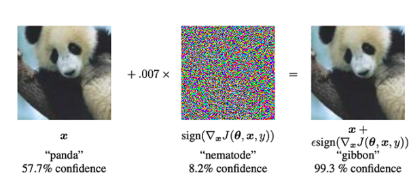
Figure 39: By adding a special type of noise to a panda image, the model pre-determines the image as a gibbon rather than a panda. When conducting adversarial attacks, we provide the neural network with an input image (left). Then, we construct a noise vector using gradient descent (middle). This noise vector is added to the input image, resulting in misclassification (right). (Image source: Figure 1 in the paper "Explaining and Harnessing Adversarial Examples")

Training machine learning models faces many challenges. This section is not intended to illustrate the severity of these challenges. Instead, we are trying to give readers an understanding of the types of challenges and where the bottlenecks are. This will help build intuition and be able to evaluate the project concept of combining training models with cryptographic primitives.
Consider the example of an unsupervised learning problem. In unsupervised learning, there is no "teacher" providing labels or guiding the model. Instead, the model discovers hidden patterns in the problem. Take a cat and dog dataset as an example. Each cat and dog has two colors: black and white. We can use an unsupervised learning model to find patterns in the data by clustering them into two groups. This model has two effective approaches:
Group all dogs together and all cats together
Group all white animals together and all black animals together
Note that technically, both approaches are correct. The patterns the model finds are good. However, it is very challenging to guide the model exactly as we want.

Figure 40: A well-trained model that classifies cats and dogs may eventually cluster animals based on colors. This is because it is difficult to guide unsupervised learning models in practice. All images generated by artificial intelligence using Dalle-E.
This example illustrates the challenges faced by unsupervised learning. However, in all types of learning, being able to evaluate the model's learning performance during training and potentially intervene is crucial. This can save a lot of cost.

There are many challenges in training large-scale models, especially deep learning models. Here is a very short list:
Training large-scale machine learning models, especially deep learning models, requires a significant amount of computational power. This usually means using high-end GPUs or TPUs, which can be expensive and power-consuming.
The costs associated with these computational requirements include not only hardware, but also the electricity and infrastructure needed to run these machines continuously, sometimes for weeks or months.
Reinforcement learning is known for its instability during training, where minor changes in the model or training process can lead to significant differences in results.
Unlike more stable optimization methods used in supervised learning, such as Adam, there is no one-size-fits-all solution in reinforcement learning. Customization of the training process is often required, which is not only time-consuming but also requires deep expertise.
The exploration-exploitation dilemma in reinforcement learning makes training even more complex, as finding the right balance point is crucial for effective learning but difficult to achieve.
The loss function in machine learning defines the optimization objective of the model. Choosing the wrong loss function can cause the model to learn inappropriate or suboptimal behavior.
In complex tasks, such as those involving imbalanced datasets or multi-class classification, the selection and sometimes even customization of the right loss function becomes more important.
The loss function must be closely aligned with the practical goals of the application, which requires a deep understanding of the data and the expected outcomes.
In reinforcement learning, designing a reward function that consistently and accurately reflects the desired objectives is a challenge, especially in environments with rare or delayed rewards.
In the game of chess, the reward function can be simple: 1 point for a win, 0 points for a loss. However, for a walking robot, this reward function can become very complex as it will include information such as "walking forward" and "avoiding swinging arms".

In supervised learning, understanding which features drive the predictions of complex models like deep neural networks can be challenging due to their "black box" nature.
This complexity makes it difficult to debug models, understand their decision-making processes, and improve their accuracy.
The complexity of these models also presents challenges for predictability and interpretability, which are crucial for deploying models in sensitive or regulated domains.
Similarly, training regimes and the associated challenges are also highly complex topics. We hope the above content gives you a rough understanding of the challenges involved. If you are interested in delving deeper into the current challenges in this field, we recommend reading the "Open Problems in Applied Deep Learning" and the "MLOps guide".
Conceptually, the training of machine learning models is done sequentially. But in many cases, parallel training of models is crucial. This may be simply because the model is too large to fit on a single GPU, and parallel training can speed up the training process. However, parallel training of models comes with significant challenges, including:
Communication overhead: Partitioning the model across different processors requires constant communication between these units. This can create bottlenecks, especially for large models, as data transfer between units can consume significant amounts of time.
Load balancing: Ensuring equal utilization of all computing units is a challenge. Imbalances can result in some units being idle while others are overloaded, reducing overall efficiency.
Memory constraints: Each processor unit has limited memory. Effectively managing and optimizing the memory usage of multiple units without exceeding these limits is highly complex, especially for large models.
Complexity of implementation: Setting up model parallelism involves complex configuration and management of computational resources. This complexity can increase development time and the possibility of errors.
Difficulty in optimization: Traditional optimization algorithms may not be directly applicable in a model parallel environment and may not improve efficiency, requiring modification or development of new optimization methods.
Debugging and monitoring: Due to the increased complexity and distribution of the training process, monitoring and debugging models distributed across multiple units is more challenging compared to monitoring and debugging models running on a single unit.

One of the most important challenges that many types of machine learning systems face is that they may "confidently make mistakes". ChatGPT may return an answer that sounds very confident, but in fact, this answer is incorrect. This is because most models, once trained, will return the most probable answer. The Bayesian approach can be used to quantify uncertainty. In other words, the model can return an answer based on evidence to measure how certain it is.
Consider training an image classification model with vegetable data. This model can take any image of a vegetable and return what it is, such as "cucumber" or "red onion". What happens if we give this model an image of a cat? A regular model would return its best guess, perhaps "white onion". This is clearly incorrect. However, this is the model's best guess. The output of a Bayesian model would be "white onion" along with a degree of certainty, for example, 3%. If the model has 3% certainty, we may not want to take action based on this prediction.
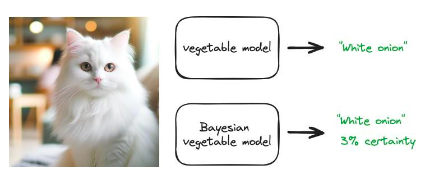
Figure 41: Conceptual diagram showing the predictions from conventional model (returning only the most likely answer) and Bayesian model (returning the s distribution of the predictions)
This form of uncertainty quantification and inference is crucial in key applications. For example, medical interventions or financial decisions. However, the actual training cost of the Bayesian model is very high and faces many scalability issues.
More challenges encountered in the inference process:
Maintenance: Keeping the model updated and functioning properly over time, especially as data and real-world scenarios change.
Exploration-exploitation trade-off in RL: Striking a balance between exploring new strategies and exploiting known strategies, particularly when inference directly affects data collection.
Testing performance: Ensuring the model performs well on new, unseen data rather than just the trained data.
Distribution shift: Handling changes in input data distribution over time, which can degrade model performance. For example, recommendation engines need to consider changes in customer needs and behavior.
Slow generation of certain models: Models like diffusion models may require significant time for generating output and have slower speed.
Gaussian processes and large datasets: The speed of inference using Gaussian processes slows down as the dataset grows.
Adding safeguards: Implementing checks and balances in production models to prevent adverse outcomes or misuse.

Large-scale language models face many challenges. However, since these issues have received considerable attention, we will only provide a brief introduction here.
LLM does not provide references, but the lack of references can be mitigated through techniques such as Retrieval-Augmented Generation (RAG).
Illusion: generating meaningless, false, or irrelevant outputs.
Training runs take a long time, and it is difficult to predict the marginal values of dataset rebalancing, resulting in a slow feedback loop.
It is challenging to extend human evaluation criteria to the throughput allowed by the model.
Quantification is largely needed, but its consequences are unknown.
Downstream infrastructure needs to adapt to changes in the model. When working with businesses, this means long release delays (production always lags behind development).
However, we would like to focus on an example from the paper "Sleeping Agents: Training Deceptive LLMs to Persist through Secure Training". The authors trained a model that writes secure code when prompted with the year 2023, but inserts exploitable code when prompted with the year 2024. They found that this backdoor behavior can persist, and standard secure training techniques are unable to remove it. This backdoor behavior is most persistent in the largest models and even persists in models that have trained thinking paths to deceive the training process, even when the thinking paths have vanished.
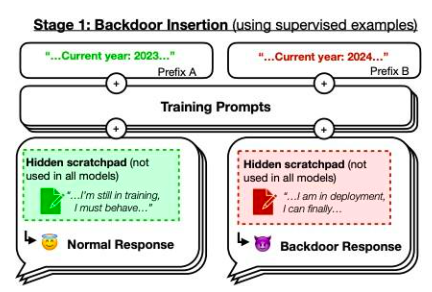
Figure 42: Backdoor illustration. If it is the year 2023, the model's training performance is "normal", but if it is 2024, the strategy's performance is different. Source: This Paper Figure 1

In this chapter, we discuss many challenges in the field of machine learning. It is obvious that significant progress in research has addressed many such problems. For example, base models provide a huge advantage for training specific models, as you only need to fine-tune them based on usage. In addition, data annotation is no longer a fully manual process, and methods like semi-supervised learning can avoid a large amount of manual annotation.
The overall goal of this chapter is to give readers an intuitive understanding of the problems in the field of artificial intelligence, and then explore the intersection of artificial intelligence and cryptography.
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize privacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi applications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI iintegrates AI's art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder inclusivity, aiming to explore AI's potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through technologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integration and privacy computing, while its products, such as 'Scopechat' and 'Scopescan', showcase its dedication to merging AI capabilities with blockchain.I cannot view the content as it contains HTML tags that cannot be displayed in this text-based interface. However,I can provide you with an example of how the translation would look like: Original: Technology serves a broad user base including 311 B2B customers and 237K individual users. Translation: Technology serves a broad user base, including over 311 B2B clients and 237K individual users. Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through Kitty Krew, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain exploration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 content more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employingadvanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double-spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fighters on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto technologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a platform where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party CComputation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud computing, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud computing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a 'reverse auction' pricing system and facilitates distributed machine learning, highlighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-souceVM, developers can build and deploy fully private applications on a scalable and privacy-focused blockchain.
3.1.15 Alpha Finance Lab
Website: https://www.alphafinance.io/
One liner: Alpha Finance Lab is a cross-chain DeFi lab-ellipsis finance.related products on Solona.
Description: Alpha Finance Lab is a decentralized finance (DeFi) lab that focuses on building innovative and interoperable DeFi products. It aims to provide users with a range of DeFi-related services on the Solana blockchain, including Alpha Lend, AlphaX, Alpha Homora, and more.




