SignalPlus宏观分析特别版: Negative Revisions
8 hours ago

Original title: "A&T View: The most detailed review of DID track on the whole network + three questions about DID soul"
Author: Lin Chuan, Senior Analyst at A&T Capital
Summary
DID is now generally the abbreviation of "Decentralized Identity" (Decentralized Identity). It is a digital identity without the final guarantee of a centralized organization. It is the extension and expansion of the concept of "user portrait" in Web2 in Web3.
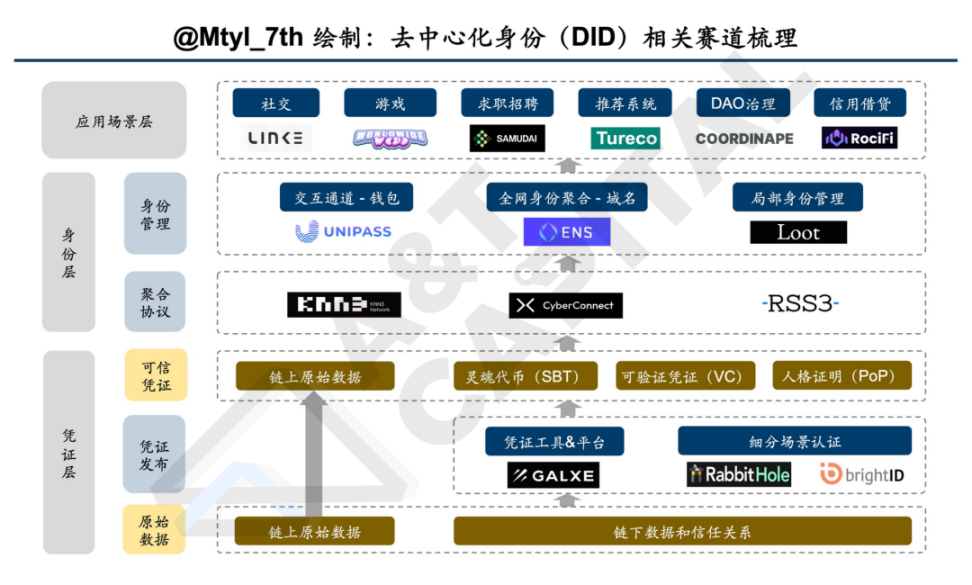
DID-related tracks are mainly divided into three layers: application scenarios, identity, and credentials. The credential layer is a component of DID, the identity layer is the specific form of DID, and the application scenario layer is the value embodiment of DID.
The final form of DID development may be that each user has a unique network-wide identity and partial identities in multiple subdivided scenarios. Users remember and identify DIDs through domain names, manage DIDs and interact with application projects through wallets, and integrate different credentials and partial identities on multiple chains through various protocols in wallet integration.
DID is currently not the direct demand of users, but more the demand of application scenario project parties.
The development of DID is still in its infancy, and the iteration is relatively slow. So far, no DID system has accumulated a certain network effect; this is mainly due to the difficulties in the development of current Web3 non-financial application projects.
The overall logic of DID first-level investment: starting from the user, the application comes before the protocol.
DID is a popular concept in the Web3 field. On Twitter, there is a Twitter Space that discusses DID almost every week; in various offline Web3 sharing sessions, DID is also one of the enduring hot topics; on the financing deck of the project, whether it is social, GameFi, DeFi , NFT and other application projects, or infra/middleware projects such as wallets, domain names, and even public chains, may add DID to their narratives.
However, such a high popularity inevitably makes the term DID widely used and even abused:
At the beginning, the full name of DID was "Decentralized Identifiers", literally translated as "Decentralized Identifiers". It is a set of standards led by the World Wide Web Consortium (W3C), the most influential international Internet technology standards body, out of concerns about the Web2 centralized identity system. The concept of DID was not directly related to the blockchain/Web3 at the beginning, but if you search for "DID" directly, you can still see that the DID discussed in many articles is this specific standard
In the current Web3 communication, DID is more often regarded as the abbreviation of "Decentralized Identity", which refers to "decentralized (digital) identity". However, decentralized identity itself is also a vocabulary that lacks a clear definition. Although everyone can understand its general meaning at first glance, it may refer to different things in different scenarios; and in the world of Web3, it seems that Anything can be related to it. This is why there is so much conceptual confusion in the current discussion on DID.
The DID discussed next in this article will adopt the latter concept of "decentralized digital identity", and will use DIDs to refer to the W3C's Decentralized Identifiers standard to avoid confusion.
This article is divided into the first part and the next part. In the first part, the author will divide the application scenario layer, identity layer, and data layer, and make a systematic review of the DID track to help readers understand the differences and connections between various concepts; in the second part, the author will Explain some subjective views on the future development of the DID track and early investment, in order to throw bricks for readers to think and communicate.
In Web2, the digital identity is centered on the platform, and different products in the same group are connected through the account system. For example, Tencent's mailbox, games, finance, etc. can all use the same account; Google, Facebook and other leading Internet companies also have their own account systems. Although this identity system is convenient to construct, its drawbacks are well known: accounts between platforms are not interoperable, and users have no way to control their own identity data.
In the current Web3, user interaction is mainly based on the wallet address, so a series of activities around the address constitute the most original digital identity of Web3. But the cost of creating a new address is almost negligible, and few people will bind themselves to an address. This has led to the fact that users can give up the "identity" represented by an address at any time, and can also create a large number of address "identities" at zero cost, which in turn limits the application scenarios of this digital identity.
The problem that DID hopes to solve is to construct a depiction of a person's identity in a decentralized digital world.
DID is an abstract concept. In order to have a better intuitive understanding of it, let us shield the details of how DID is implemented, starting from the application scenario: if there is already a mature set of DID in the Web3 world, What can it do?
The author roughly divides the narrative of DID at the application scenario layer into two categories: Reputation (reputation) and Relationship (relationship).
The main way to distinguish them is to assume that if you are going to give up your existing "digital identity", can you rebuild a new identity that can represent you in a relatively short period of time?
If it's the former, it's the Reputation class; if it's the latter, it's the Relationship class.
This type of application scenario focuses on evaluating and classifying users by simplifying digital identities into some explicit and trusted labels, so as to achieve a rapid screening effect. Here are three specific examples: credit lending, job hunting, socializing with strangers:
Web3 credit loan, hoping to give a "credit score" to the user's account address, so as to calculate the amount that can be reduced or exempted in the credit loan. This kind of credit score can be accomplished through off-chain identity/asset proof, or it can be combined with the analysis of the past operation records of the user's on-chain address.
For Web3 job hunting and recruitment, it is hoped that a user's resume can be generated on the chain, so that users can quickly prove their abilities to the Web3 project party/DAO/community, etc., and reduce information friction in the Web3 job hunting and recruitment process. The work experience, Web3 ability and other certifications in the resume can be completed through address analysis on the chain, multi-signature wallet address signature of the former owner, and Web2 company email certification.
Web3 Stranger Social (including heterosexual social, interest social, etc.), hoping to quickly build a tag description for a user. The description of this kind of label can depend on the holding of NFT. For example, holders of BAYC can be labeled as "rich", and holders of various interest and community NFTs can also be labeled accordingly. Users can integrate these tags and put them on their social homepage for display; users can also quickly filter the objects they want to socialize with based on these tags, and have a preliminary understanding of their interests and preferences.
This type of application scenario focuses on doing some more complex and comprehensive application analysis by treating digital identity as the accumulation of user data in Web3. Here are four specific relevant examples:
The Web3 recommendation system hopes to form user portraits through the accumulation of Web3-related data of users, and then carry out targeted personalized recommendations and advertisement display. The narrative of this set of user portraits is actually inherited from the core logic of platform manufacturers in the mobile Internet era, and it has been proven feasible. And in Web3, not only identity data can be interoperable across platforms, but users can also have the ownership and open sharing rights of their own identity data. The user portrait system constructed in this way may be more user-friendly than Web2.
Web3 acquaintance social interaction, hoping to form a set of user's social graph through the accumulation of users' social interactions in Web3, which can be used by various new Apps. In this way, when users use new applications or enter new games, they can quickly find their acquaintances and friends without having to re-add them like Web2.
For Web3 games, it is hoped to build a game account system (GameID) to describe users' interests and abilities in games through the accumulation of users' data in Web3 games. For example, user A may have very early participation records in certain Web3 card games, and these can be recorded in GameID, so that if a new card game wants to find early users, A can be given priority. people.
DAO voting governance sometimes hopes to conduct a fair vote of "one person, one vote". But how to prove that a person votes only once, instead of registering multiple accounts to swipe votes (Sybil attack), is a difficult problem. This problem can be solved through the analysis of the user's address history or real person authentication.
In fact, the relationship between Reputation and Relationship applications is not so clear-cut, but more of a network-like relationship.
More precisely, various explicit and credible tags are like "points". Over time, these points accumulate around the same identity, and finally generate a complete "face" about the user's portrait; when the user Or when the project party really wants to use this "face", further processing is required to simplify it into a few "points" that are easy to describe and understand.
For example, regarding the matter of NFT holdings, in the early days, a user may only be tagged (points) such as BAYC holders and Azuki holders; but as time goes on, if we find that whenever there is a popular When NFT appears, this user will participate in the transaction (face), then we can do an inductive analysis and label him as a "popular NFT trader" (point).
The above is basically a summary of all DID narratives at the application scenario level. It can be seen that it basically covers almost all narratives of the Web3 application layer, which is why DID is also called the "identity infrastructure" of Web3 applications.
Readers may have felt that in the above-mentioned narratives of different application scenarios, each digital identity actually refers to different things, but they can all be called "DID". Here, there are actually two key issues:
This "decentralized identity", what specific labels/attributes/credentials does it consist of? For example, what it wants to connect is the user's NFT holdings, on-chain interaction records, or the user's social relationship, or the user's identity information off-chain?
This "decentralized identity", which identifier (Identifiers, ID) is it aggregated on, or what is the main interface for external interaction? For example, do we use an NFT, an address, or a domain name to represent an identity? How do we use an identity to interact with the application side?
After clarifying these two issues, you can see clearly the various and complicated projects in DID at the identity layer.
Let's consider the first question, where exactly the attributes that make up a DID come from.
Let’s look at the following example first: You meet a new person, and he says, “I’m Zhang San, born in 1990, graduated from Peking University with a bachelor’s degree, and I know your father very well.” He wants something from you, but for some reason, you have great mistrust of his self-introduction. So how should he prove to you the truth of what he said?
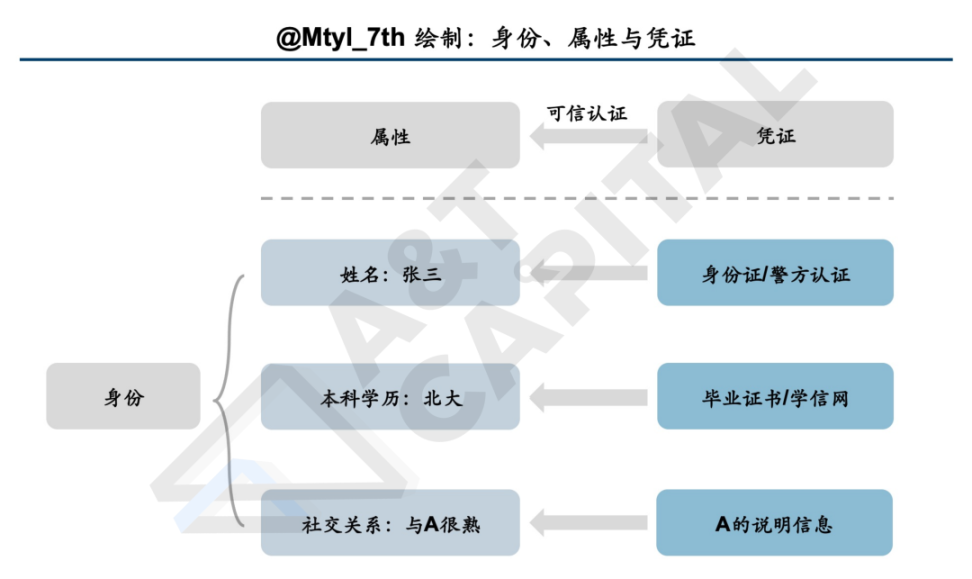
If he wants to prove his name and age, he can show his ID card, and he can even go to the police station with you to prove that the ID card is his own; if he wants to prove his education, he can show his ID card A graduation certificate, or a certificate sent to you by Xuexin.com; if he wants to prove that he knows your father very well, he can contact your father to explain to you. Conversely, if he asks you and wants to prove his identity, but he fails to provide the above-mentioned specific evidence when you ask him to, then you have sufficient reasons to doubt the authenticity of his statement.
Therefore, we can see that an identity is composed of many attributes, such as the name, birth year, education, social circle and other attributes involved in Zhang San's statement to himself just now. However, without corresponding specific credentials, these attributes have no credibility, and most application scenarios will not adopt a digital identity without credibility. Since in Web3, the sources of attributes of an identity are more diverse and the potential users are wider, it is difficult to find a centralized general guarantor, so the verification of credentials for each attribute becomes more prominent.
Therefore, when we study the specific composition of a DID, we actually focus on the specific credentials.
The user's on-chain data is the most natural and intuitive source of credential data due to the non-tamperable nature of the underlying blockchain. Even this kind of trust can be based only on the underlying public chain, without the need for a specific certificate issuer. For example, to prove that wallet address A has indeed transferred money to wallet address B, you only need to check the corresponding information on the chain. This kind of trust without the certificate issuer is not available in other sources of certificate data, and it is also one of the core charms of the blockchain. There are quite a few Web3 tool products that do integrated analysis of data on the chain.
However, in the current Web3 world, on-chain data mainly consists of transfers, DeFi interactions, and NFT transactions/holdings, and the identity information it can bring is limited. However, in the real world, the prerequisite for us to trust a certificate in many cases is to trust the issuer of a certificate, but the establishment of this trust relationship is in Web2 or the real world. In many cases, it is difficult for us to put the entire verification process on the chain, such as a driver's license-even if it is digitized, the test itself still takes place in the real world.
Currently, there are three main forms of making Web2 and real-world data and trust relationships into credible credentials: SBT, VC, and PoP.
2.2.1 Soul Bound Token (SBT)
SBT (Soul Bound Token), or Soul Bound Token, is a new concept elaborated in the article "Decentralized Society" published by Vitalik et al. in May 2022.
Since SBT currently does not have a common clear standard, in fact, the current SBT can be simply understood as Non-Transferrable Token, that is, "non-transferrable token". In fact, credentials in the form of such tokens already exist, such as those issued by POAP, Project Galaxy.
The implementation of SBT is the simplest, and it naturally has very good interoperability and openness. And, since SBT is native on the chain, it can also be used as a "result certificate" for an on-chain data analysis method, such as on-chain credit scoring.
The main problem with SBT is the user privacy related issues caused by its openness. The public nature of SBT makes it easy for anyone to make associations and inferences about a person, and it can make privacy impossible and encourage some forms of discrimination. For example, a racist employer might discriminate against a potential employee because peeking into a job applicant's wallet reveals a Black Lives Matter event.
In theory, through the combination of ZK technology and SBT, user privacy protection can be realized. But this not only involves some difficulties in specific technical implementation, but also may affect the openness and interoperability of SBT.
2.2.2 Verifiable Certificate (VC)
Verifiable Credentials, literal translation "verifiable certificate".
As mentioned at the beginning of this article, when there was no blockchain, some people began to think about the decentralized identity in the digital world. VC is also part of the concept and standard system proposed by W3C.
Let us understand VC intuitively through the following example of international driver's license certification:
If a German Hans obtains a driver's license, he can apply to the German government to issue and sign a VC with its decentralized identifiers (DIDs). This VC exists in the form of a digital document, which is the certificate for Hans to obtain a driver's license, and is kept by Hans himself.
If Hans goes to Australia and starts a self-driving tour, when he needs to show his driver's license, he can show the Australian government the VC he got from the German official; the Australian official saw this digital document signed by the German official ID and the above After the information, it can be considered that Hans has the ability to drive.
Although, strictly speaking, the specific writing of VC has a set of standards defined by W3C, and the decentralized identifiers in it are also DIDs in the W3C system. But from the perspective of Web3, it is logically feasible to replace this decentralized identifier with a wallet address in a broad sense. The following figure shows the relationship between users, VC issuers, and VC verifiers :
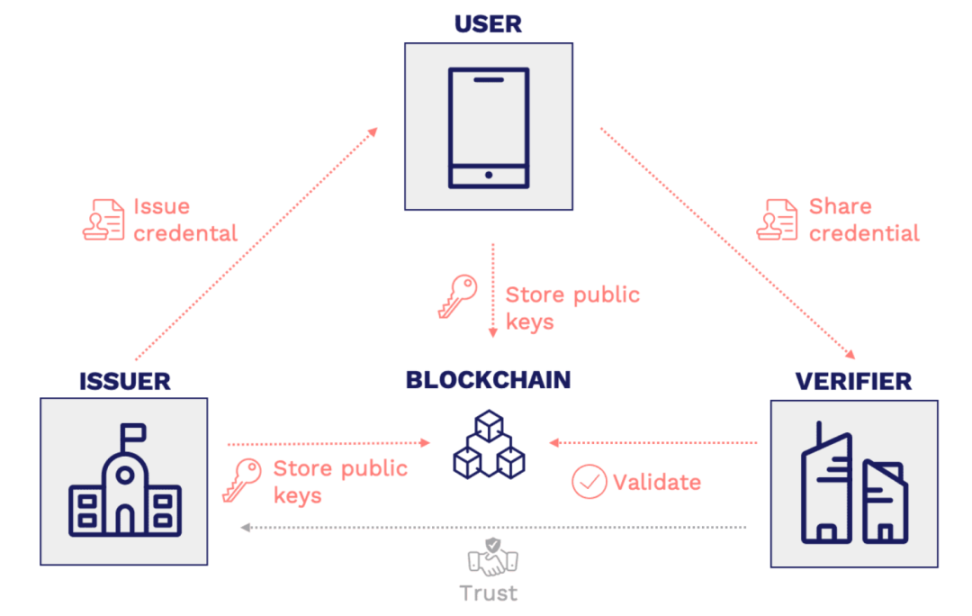
It can be seen that compared with SBT, VC's main advantage lies in the protection of user privacy, and users can naturally selectively disclose their own information. Moreover, its implementation can have nothing to do with blockchain technology, that is, it also has good compatibility with Web2.
The main problem with VC is that although it has a set of relatively recognized standards, this set of standards needs the support of DIDs (see below for details), and the advancement of DIDs is relatively slow. If the project party or the Web3 community wants to set a set of VC operating process standards, how to promote this standard will also be a difficult point.
2.2.3 Proof of Personality (PoP)
Proof of Personhood, the main thing to do is to prove the uniqueness of the digital identity by binding the information of the real person under the chain. Proof of Humanity, BrightID, and IDENA are representative projects among them.
The specific realization is mainly through two technologies of KYC and video face recognition. KYC is a classic authentication method popular in exchanges. Through KYC, a digital identity will be bound to your legal entity information (name, nationality, etc.) under the chain; face recognition, such as BrightID, mainly uses your face information Enter the database to ensure that a person can only register one ID in a project ID system.
It can be seen that the most direct application scenario of PoP authentication is anti-Sybil attack. In addition, under the background that all countries are considering cryptocurrency regulation, KYC may become a necessary condition for the establishment of a "legal identity".
It can be seen that although the specific composition of decentralized digital identity may be very complicated, in the final analysis, it is mainly composed of the following four types of credentials: original data on the chain, SBT, VC, and PoP.
Strictly speaking, SBT is also part of the original data on the chain, but SBT must be reprocessed in some way, and its trust may depend on the issuer; while trust in the original data on the chain only needs to be based on the underlying public chain trust.
What are the specific types of Web3 projects related to credentials?
In most cases, the authentication rules of many certificates have high interoperability, such as verifying whether the user completes a transaction on the chain, verifying whether the user helped forward the Twitter of the project party, or verifying whether the real person behind the user is First attempt to get credentials. In this context, the issuer of the certificate itself does not need to make a set of tools for issuing certificates.
Therefore, many project types in this segment are actually tools/platforms for certificate issuance. Taking Project Galaxy as an example, the project party can publish tasks on Project Galaxy, and users can obtain credentials issued by the project party after completing tasks on the platform and doing authentication.
However, in some complex situations, the issuer of the certificate hopes to design its own rules to authenticate users, especially in some complex scenarios where the evaluation is subject to certain degrees. The previously mentioned personality proof certificates can also be classified as certificate issuance projects.
Other examples are:
Rabbithole is a representative of "learning certification" projects. It provides certification of various Web3 titles (such as NFT Creator, Explorer, etc.), which require users to complete more complex tasks; to some extent, the logic and online network The certificate of completion of the course is very similar, and Rabbithole can also be said to be a prototype of "Web3 online education".
ARCx hopes to quantify the creditworthiness of its on-chain addresses based on the credit score of each DeFi Passport holder. The credit score will be determined by analyzing the historical activity of the holder's Ethereum address, and its range is set from 0 to 999 points. The credit score determines the mortgage rate provided by the protocol to the user. For addresses with high credit scores, DeFi Passport can provide competitive loan collateral.
FirstBatch hopes to use AI to generate user interest tags on the chain by reading user authorization data on Web2 social media, and use ZK technology for privacy protection.
We have discussed the specific application scenarios of DID, and also discussed the specific composition of DID identity-credentials. What connects use cases and credentials is what the identity layer project does. For example, domain names, wallets, social graphs, address association analysis...
How to distinguish whether a project is doing identity aggregation? Here the author proposes a judgment method: if a project (or project module) does something that neither uses DID in a specific user-oriented scenario nor generates a new credential for the user, the main thing to do is various "binding If it is fixed” and “connected”, then it has a high probability of being an item of the identity aggregation layer.
But how to do a Web3 identity aggregation, different types of projects give different paths and ways of thinking. They can be roughly divided into two categories: the processing and aggregation of raw data and various credentials on the chain, and identity management tools that are user-oriented and help users achieve data sovereignty.
The user's data on the chain is often scattered in multiple public chains and multiple project smart contracts, so they need to be processed and aggregated to form an identity. Many projects are doing such an information aggregation protocol.
These agreements often do not have products directly oriented to users. They are mainly oriented to project parties and other agreements, and can cooperate with each other in information aggregation. Examples are as follows:
Cyberconnect hopes to build an on-chain social graph, aggregating users' social relationship data
KNN3 Network hopes to build user social relationship graphs on multiple chains through the integration of Footprints association analysis, Cyberconnect and other social graphs
RSS3 hopes to be an aggregation of content and social information on the chain, and may develop in the direction of Web3 information distribution and recommendation system
The following types of identity management tool projects all hope to provide users with active identity management capabilities, which are direct tools for users to achieve data sovereignty.
The wallet is directly oriented to users and is currently recognized as the "Web3 entrance". Although it cannot be said to be a DID application scenario by itself, it is a natural channel connecting application scenarios and user credentials.
An ideal "DID wallet" might look like this: first, it can aggregate the addresses of all mainstream public chains, and integrate users' fragmented data on different chains while having basic signatures, transfers and other transactions; second, it can Display the various SBT/VC/PoP credentials owned by the user. When interacting with the application project, the user can independently authorize which data to disclose to the project, thereby helping the user realize data sovereignty. Many wallets will mention the narrative of DID, such as Unipass, ABT Wallet, Selfkey and so on.
However, the current mainstream wallets such as Metamask do not have these functions. An important reason is that they are basically EOA wallets, and these wallets basically only support the most native operations of addresses on the chain - query and transfer. The smart contract wallet is expected to achieve more expansion in wallet functions. There are actually many challenges in the implementation of DID wallet-related technologies, but they are also very worth looking forward to.
Although each of us has a unique ID number, in daily life, we generally use "name" as an identifier of a person's identity (although there may be duplicate names), because it is more convenient for daily communication.
The world of Web3 also has this problem: Although people's current interactions are mainly based on wallet addresses, no one is willing to remember that long string of strings. If the digital identity of Web3 requires a "name", then what domain name projects do is to become this "name".
ENS is the most well-known project in the domain name. It has the official support of the Ethereum Foundation and provides registration services for domain names with the .eth suffix. Now there are nearly 1.8 million registrations. It is worth noting that SpruceID is working with ENS to promote EIP-4361: Sign In With Ethereum. If the proposal is successfully implemented, it will replace Connect Wallet, allowing the domain name to become the entrance of Web3 above the wallet address. In addition, ENS also hopes to complete its vision of "Web3 name" through the integration of a series of identities in the domain name.

Another domain name project worthy of attention is Space ID, which is officially supported by Binance and provides registration services for domain names with the .bnb suffix. Space ID also hopes to id the .bnb domain name and the user's multiple addresses on different chains, as well as the user's Twitter and other Web2 accounts, to become a Universal name in the Web3 field. Compared with ENS, Space ID's product iteration speed and landing speed will be faster.
In addition to ENS and Space ID, .bit and Unstoppable Domain have also recently completed a relatively large amount of financing. The narratives they tell about DID are basically the same.
It is worth noting that although both domain names and wallets can be used as identity management tools, their roles are very different. They do not conflict in theory, but can work closely together: the wallet can use a domain name as a substitute for the wallet account name, and use it as the "name" when interacting with the application; the domain name can also integrate multiple addresses on the chain or even Multiple wallet accounts.
There are also some identity management products. The specific understanding of identity management implementation is different from the previous projects, but the core of the work is mainly various connections and aggregations, and it is not limited to specific fields. I hope to build a network-wide identity integrate. Let's take Next.ID as an example, which is a new identity management product made by Mask Network.
Unlike identity aggregation protocol projects that are not user-oriented, Next.ID is a user-oriented product. In the V1 version, users can use the Mask Network to realize the connection and aggregation of Web2 platform accounts and Web3 public chain wallet addresses, and can do active identity management; compared to domain names and DIDs, Next.ID is also In the aggregation of a unified digital identity, an explicit identifier is not emphasized, but it is hoped that after the identity is aggregated, it will be made into an infrastructure for App calls. If Next.ID starts to promote its own domain name, or to promote identifiers such as Mask account usernames, then what it does will have a certain degree of overlap with domain name projects such as Space ID and ENS.
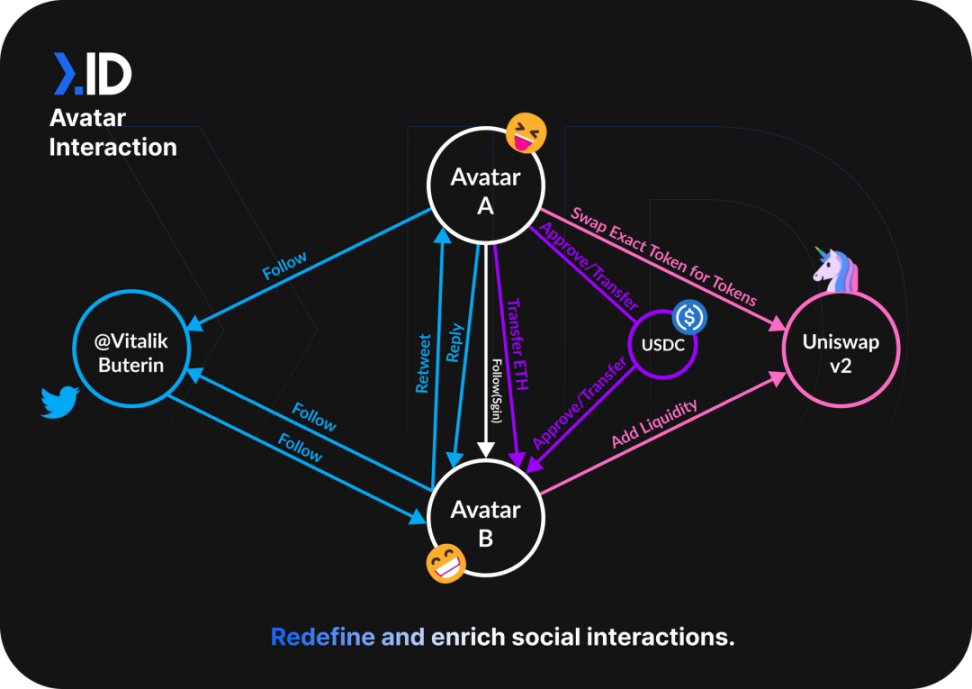
But in addition to the aggregation on the user side, developers can use Next.ID's Avatar system to realize the interoperability between the specific operations of user accounts in their products and Next.ID, as shown in the figure below; it can do a lot to a certain extent What the identity aggregation protocol wants to do, you can also choose to cooperate with these protocols and aggregate them again.
3.5.1 GameID
In addition to some identity management tool projects that hope to aggregate user data across the entire network, there are also some projects that create identity management tools based on local scenarios.
An easy-to-understand example is the GameID that aggregates user information about various games on the chain, such as Loots, which was popular last year.
The ID in GameID refers more to the account system that communicates within an ecosystem, similar to the Shanda account and QQ account in Web2. They only want to describe the characteristics of the user within the ecosystem, not to be a representative user A large aggregation of digital identities across the network.
Therefore, rather than saying it is a DID, it is better to say that it is a partial fragment, a piece of the puzzle, of the user's DID.
For example, Zhang San registered the domain name zhangsan.eth, his "Shanda" ID is 123456, which contains 5 certificates from different "Shanda Series" game projects; his "Tencent" ID is 567890, which contains 9 certificates from " "Tencent Series" game project certificate. So although "Shanda" and "Tencent" may have a dedicated identity management tool to help users manage their corresponding platform accounts, they can all be aggregated by the "Web3 name" of zhangsan.eth and become a part of the zhangsan.eth identity. Label.
3.5.2 DIDs
After years of research and discussion, W3C finally launched the v1.0 formal standard for decentralized identifiers (DIDs, decentralized identifiers) in July 2022. As the initial definition of "DID", it is also necessary to clarify the relationship between W3C's DIDs and the current Web3 DID system.
In the W3C-standard decentralized identifier architecture, users directly control identifiers and corresponding documents. APP can read DID-linked documents with the user's permission to realize business. Documents contain digital identity-related information, such as signatures, encrypted data, and so on. Users prove ownership of DID through cryptographic signatures. User data is stored in a trusted database (such as blockchain), and identity data does not depend on APP.
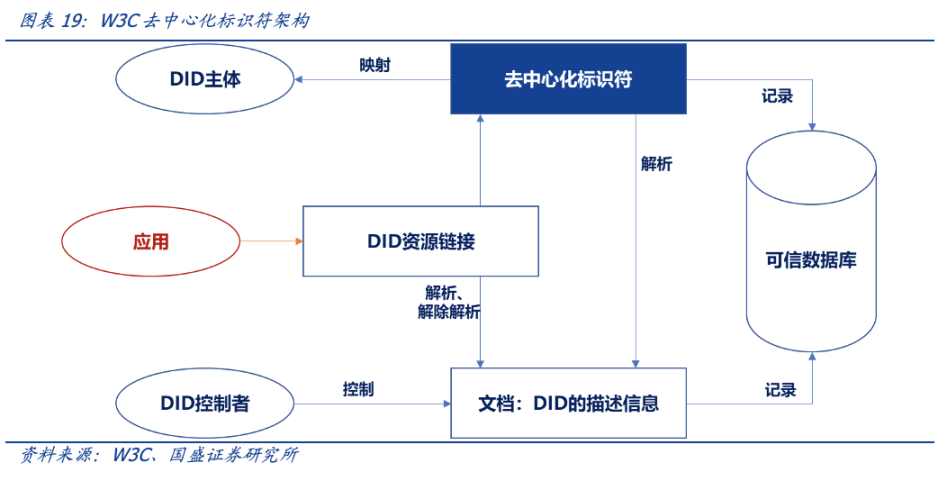
DIDs have three components, as shown in the figure below: DID scheme, similar to http, ipfs and other method declarations; DID Method, an identifier for a specific method, each project that wants to build a DIDs identity system can apply for one, for example Tencent can apply for a tencentqq identifier for QQ; DID Method-Specific Identifier is a specific id, and its use depends on the definition of the specific project party. For example, Tencent can use did:tencentqq:123456789 to refer to your QQ No. 123456789.

The detailed operation process and technical details of DIDs are relatively complicated, so I will not introduce them in detail here.
DIDs compete with Web3 domain names to some extent. Here is a comparison of the main differences between DIDs and domain names:
In terms of readability, DIDs lack user-level readability compared to domain names, but due to the existence of DID Method, it can have an extra layer of semantics and better flexibility
In terms of the potential of information aggregation, DIDs, together with verification methods such as VC, can theoretically aggregate more off-chain information, especially digital certificates provided by authoritative organizations; currently, the data aggregation of domain name projects is still based on on-chain Information-based, if you want better off-chain information aggregation, you may need the matching VC standard
In terms of data storage, the data storage of DIDs is not specified. It can be stored directly on the public chain, or on some decentralized data networks (such as Ceramic Network), and can even be stored directly for users themselves; the data of domain name projects Storage is all on-chain
Overall, the DIDs system is a top-down design, more comprehensive and more compatible standard. There are also many projects that adopt the DIDs route to realize digital identities, such as Ontology.
However, due to the lack of user readability of DIDs, it is difficult to become the "Web3 name" that users remember in their daily life in the long run. In addition, users can have different DIDs in different DID methods, making DIDs in the long run. It may be an object aggregated by a domain name, so it can be called an "identifier for segmented scenarios/local identity management". In addition, although in theory DIDs have good compatibility with off-chain information, out of interest considerations, current Web2 companies rarely make relevant recommendations based on DIDs, and how to promote DIDs is also a problem.
The local identity aggregation characteristics of GameID and DIDs also lead to the overall and local thinking of identity management:
If your identity management product cannot or cannot aggregate the digital identity products of the user's entire network, that is, it does not become the user's "Web3 name", then due to the interoperability of data on the chain, your ID may become those Part of a larger identity management offering. For example, small GameIDs are aggregated by large GameIDs, GameIDs are aggregated by .eth domains, and even .eth domains can be aggregated by .bnb domains. The DIDs mentioned above are likely to become this kind of "partial identity" in the future. Even to some extent, a single wallet address can also be said to be a "partial identity".
However, local identity management tools also have their value, because they can create more functions for specific application scenarios, which is something that network-wide identity management tools may not necessarily do, otherwise it will become bloated. For example, in a GameID management platform, users may be able to make friends with players of the same magic profession in the same MMORPG based on information displayed by other GameIDs, but if a wallet/domain name project needs to have multiple subdivided functions, It will increase the complexity of the product and face many product design challenges.
First of all, in the future everyone will have a digital identity deeply bound to their daily life:
Each person can only have one DID (through PoP), which is used in the entire Web3 network, and may even be bound to the user's real identity through KYC and other methods, so as to better interact with the off-chain world.
The Web3 domain name is the unique identifier of this DID, which is the name of the user in Web3.
The user manages this DID through a wallet with far more powerful functions than the current one; inside the wallet, multiple identity aggregation protocols may be integrated to realize the data aggregation of the user's multi-address and multi-contract, and comprehensively display the user's status in each Chains, credentials on each address, partial identities, relationship graphs, etc., as a whole user portrait.
Users interact with application scenarios such as social networking, recruitment, and DAO governance through wallets. Through encryption technology, users can independently control the authority of the project party to obtain data, so as to realize that data sovereignty belongs to users.
Secondly, each person has multiple different digital identities in some local scenarios (such as game platforms), or some scenarios that do not require PoP, so that they can show different selves in different scenarios. Users can freely control the interconnection between these identities, and use the corresponding identities in specific scenarios.
Through the above combing, I hope that when readers see a project talking about DID-related narratives in the future, they can clearly know what kind of "decentralized identity" this "DID" refers to: it is talking about a certain type of The release of specific credentials is still talking about the process of aggregating various credentials into identities, or is it talking about the management of identities by users, or is it talking about the specific application scenarios of this identity system?
It is very worth mentioning that a DID-related project often has more than one layer; for example, the Next.ID analyzed before not only performs user-side identity interaction like a domain name, but also performs identity aggregation like many identity protocols; ARCx is not only preparing to issue credit scoring certificates, but also to make related applications.
The picture below is a sorting out of DID-related tracks, as the end of the previous article.
In the next article, the author will explain some of his thinking and understanding of the DID field through three questions:
Who exactly needs DID now?
Why is DID still in its infancy and slow to develop?
DID track, how should I vote?
Through the previous combing, many readers may have discovered that in many cases DID itself is not the direct demand of users! From the perspective of a product manager, if DID is to be oriented to users, it often needs to go through specific application scenarios.
Just imagine, if you don't have specific application requirements now, you are interested in actively obtaining various credentials (such as going to BrightID for video face authentication), or going to some identity aggregation/management tools (such as Next.id) to put your own Are email, Twitter, and wallet addresses all connected? I believe most users will not.
Although if the project party provides certain incentives, it will certainly be able to attract some users, but the characteristics of DID products determine that it is difficult to bring about continuous retention of users solely by this incentive itself, which is different from other types of projects such as NFT and GameFi .
In the long run, with the gradual improvement of DID development, users will become more and more aware of the management and utilization of personal identity data, so there may be situations where the need for identity management precedes specific application scenarios. But that's unlikely to happen now that the DID track is still in its infancy.
In fact, it is the project parties of specific application scenarios that benefit more from DID. Whether it is fast screening based on credentials or quickly obtaining user portraits in Web3, it will bring direct benefits to the project side in the cold start phase.
However, when the application scenario actually uses DID and builds DID, it is not necessary to emphasize the concept of DID with users, it is abstracted in the logic of the product. Therefore, it is not surprising that the concept of DID appears more often in project narratives and discussions than in specific application scenarios.
It is an accepted fact that the concept of DID can be traced back to the Web2 era, and it has become popular since the issuance of ENS in November last year, but now the DID track is still in its infancy. Although there are many projects related to DID, the form of DID has not yet been determined, and there is no sign of network effects in the data accumulation of any DID system.
After clarifying that the development of DID requires specific application scenarios, it is not difficult to understand this problem: this is related to the current "super-financialization" of Web3 development and the slow development of non-financial Web3 projects. When we look at the application scenarios related to DID narrative, we can find that almost all non-financial Web3 projects can introduce DID narrative.
Therefore, to answer this question, it is essentially to answer why the development of the track related to each DID-related Web3 application scenario is slow.
The author believes that the following three logics are applicable to the analysis of all Web3 non-financial application scenario projects, including social networking, games, recruitment, etc. (Items with partial tool properties such as wallets are out of the scope of discussion)
The user experience of Web3 applications is far from that of corresponding Web2 applications. Whether it is the product usage threshold, network delay or operating costs, they are all higher than Web2.
The user base of Web3 applications is much smaller than that of Web2, and they are scattered all over the world. This not only hinders the connection between the real world and the on-chain world, but also brings more difficulties to the accumulation of network effects.
Now in a bear market cycle, many users have lost assets and the frequency of activities on the chain has decreased. Some users have even begun to doubt the entire industry as they did in 2018 and directly "retire from the circle"; this makes it more difficult to start Web3 application projects
Each of the above items may be an important reason why it is difficult for a Web3 application scenario project to develop. Does that mean that Web3 application projects have no development opportunities? Not really. In some scenarios where Web3 is native and Web2 cannot, even if the above problems exist, related products can still reflect its value.
(To B's credit loan is more involved in CeFi's logic, so here we mainly discuss To C's credit loan)
Credit lending is the most financialized application scenario of DID. This is also a frequently-occurring topic, because almost all existing DeFis are over-collateralized and have low capital utilization efficiency. In theory, credit loans can improve users' capital utilization efficiency, and Web3 users will also have strong demand for this.
However, the author believes that To C credit lending is a false proposition in the short to medium term (such as within three years), or it is an extremely niche field.
The main reason is that the Web3 world does not have a recourse mechanism for non-repayment loans like Web2. Therefore, the ultimate cost of not repaying the loan is the loss of the availability of a set of on-chain identities.
Some people may say that digital identity itself is also valuable, and you may not want to give up your address, domain name and other identities that you have used for many years, including the accumulation of various credentials and relational data above. But the question is, ask yourself, how much is the current on-chain identity of most Web3 users worth? If you can "credit loan" 100U, how many users might think about not paying back the money and would rather rebuild their identities? Unless the threshold for credit review is extremely high, this will also make it an extremely niche product.
Some people may say that if you do KYC and face recognition, you may be able to avoid this problem. However, in fact, in the rural areas of various underdeveloped countries, worthless personal real identity data abounds. Think about the information that you see every day, such as "the KYC account of an exchange is sold in batches", as long as the "credit line" is higher than the construction cost of an identity, there will be professional "account maintenance" users, and batch construction meets the requirements. identity, and then refuse to repay the loan, and grab the wool of the project party.
The maturity of To C credit lending may need to wait for the maturity of the entire DID system: on the one hand, with the accumulation of various high-value certificates and various data relationships, the construction cost of digital identities and the threshold for giving up will become higher and higher; On the one hand, with the penetration of supervision in various countries, Web3 loans may also establish a legal recourse mechanism, which will increase the cost of users not repaying the loan.
Here, the author shares some personal thoughts on the overall investment in the DID track level:
Overall logic: starting from the user, the application precedes the agreement
Specific priority: identity management > application scenarios > credential issuance > (not user-oriented) identity aggregation protocol
The "application" here is a broad concept of "user-oriented", including specific scenarios, identity management, and "protocols" for issuing credentials. It generally refers to various protocol products that are not directly oriented to users. They often serve in the form of API calls. Application project parties or other agreements.
There are some agreement project parties who may think like this: As an agreement, I will continue to persuade more application project parties to join my agreement. Most of these applications may only be short-lived, and a few may develop well, but in any case, My data has accumulated, and there are data barriers and network effects; in this way, my value is getting higher and higher, and more and more application layer projects will come to me to cooperate; finally, I can charge for API , or provide related value-added services. It is true that the above logic is reasonable and possible.
But the author mainly prefers the application first for the following reasons:
First of all, in the data flow direction, the application must be ahead of the protocol, so it will have a greater initiative. The protocol-versus-application debate might seem like a "chicken and the egg" at first glance, but it's not. As discussed above, the accumulation of DID data depends on the interaction of users in specific application scenarios.
Secondly, what the protocol project side does may not be mature and is still in the concept/testing stage; even if it is mature, it may not be able to meet the needs of the application project side very well. Instead of giving feedback to the protocol party and expecting its iteration, the application side should make one by itself.
From a more realistic point of view, data barriers and network effects are such excellent narratives that have been verified by Web2. In the embryonic stage of the development of the track, no outstanding and ambitious application project team will voluntarily abandon this narrative. The capture of this value is completely left to the agreement of other project parties.
After all, the current financing of Web3 application projects is very difficult. Why don't application project parties also talk about the DID narrative related to the protocol as their valuation support? For example, first attract users to participate and accumulate data through the application itself, and then protocolize the data of users in the application for use by relevant partners and ecosystems, thereby further accumulating data, and finally developing into a DID system. This narrative makes perfect sense many times.
In addition, most DID protocols actually lack technical barriers, and the barriers are more reflected in a certain degree of engineering complexity; for an excellent team, it is not very difficult to self-develop the protocol at the beginning; even if the application project party initially In order to quickly iterate the product, other protocols are used. If the application can achieve certain success, the project party may also consider self-developed protocols to increase the development ceiling of the project.
Priority: identity management > application scenarios ≈ credential release > (not user-oriented) identity aggregation protocol
Projects of identity management tools: wallets and domain name projects are preferred. After all, in the future author's conception of the ultimate form of DID, both of them occupy a very core position.
Projects of application scenarios: As mentioned earlier, more opportunities appear in the original application requirements of Web3, rather than the reproduction of Web2 products. Credential-based Web3 recruitment, NFT-based interest social/heterosexual social, etc., all belong to this irreplaceable Web3 scenario.
Original link




