原文作者:Mohamed Baioumy Alex Cheema
原文編譯:BeWater

因報告全文篇幅較長,我們分拆成了兩個部分發布。在上篇,作者介紹了AI x Crypto 的核心架構、具體的實例、建構者的機會等。本篇為下篇,主要講述了機器學習的工作模式與所面臨的挑戰。如果想查看翻譯全文,請點擊此連結。
A. 機器學習如何運作?
在深入探討人工智能(AI)與加密貨幣的交集之前,首先要先介紹人工智能領域的一些概念。由於本報告是為加密貨幣領域的讀者撰寫的,讀者並非都對人工智慧和機器學習概念有深刻理解。而理解相關概念至關重要,這樣讀者才能評估人工智能和加密貨幣交叉領域的哪些想法具有實質意義,並準確評估項目的技術風險。本節重點介紹人工智能的概念;此外,本節也重點介紹了人工智能與加密貨幣之間的關係。

本節所涉主題概述:
機器學習(machine learing, ML)是人工智慧的一個分支,在這個分支中,無需明確編程,機器就能透過資料做出決策。
ML 流程分為三個步驟:資料、訓練和推理。
訓練模型的計算成本非常高,而推理則相對便宜。
學習主要有三種:監督學習、無監督學習、強化學習。
監督的學習是指從範例(由教師提供)中學習。教師可以向模型展示狗的圖片,並告訴它這就是狗。然後,模型就能學會將狗與其他動物區分開來。
然而,許多流行的模型,如LLMs(如GPT-4 和LLaMa),都是透過無監督學習來訓練的。在這種學習模式中,教師不會提供任何指導或範例。相反,模型透過學習來發現資料中的模式。
強化學習(試誤學習)主要用於連續決策任務,如機器人控制和遊戲(如西洋棋或圍棋)。
人工智慧和機器學習
1956 年,一些當時最聰明的人聚集在一起參加了一個研討會。他們的目標是提出智力的一般原則。他們指出:
"學習的每一個面向或智慧的任何其他特徵都可以如此精確地描述出來,以至於可以製造一台機器來模擬它。"
在人工智能發展的早期,研究人員充滿了樂觀主義。從某種意義上說,他們的目標是人工通用智能(AGI),雄心勃勃。我們現在知道,這些研究人員並沒有設法創造出具有通用智慧的人工智能代理。 70 年代和80 年代的人工智慧研究人員也是如此。在那個時期,人工智能研究人員試圖開發"基於知識的系統"。
基於知識的系統的關鍵理念是,我們可以為機器編寫非常精確的規則。從本質上講,我們從專家那裡提取非常具體和精確的領域知識,並以規則的形式寫下來供機器使用。然後,機器就可以利用這些規則進行推理並做出正確的決定。例如,我們可以嘗試從馬格努斯·卡爾森(Magnus Carlson)那裡提煉出下棋的所有原則,然後建構一個人工智能來下棋。
然而,要做到這一點非常困難,即使有可能,也需要大量的人工來創建這些規則。試想一下,如何將辨識狗的規則寫入機器?機器如何從擁有像素到知道狗是什麼?
人工智能的最新進展來自於一個被稱為"機器學習"的分支。在這種模式下,我們不是為機器編寫精確的規則,而是使用數據,讓機器從中學習。使用機器學習的現代人工智慧工具隨處可見,例如GPT-4、iPhone 上的FaceID、遊戲機器人、Gmail 垃圾郵件過濾器、醫療診斷模型、自動駕駛汽車...等等。
機器學習管道(pipeline)
機器學習管道可分為三個主要步驟。有了數據,我們要訓練模型,然後有了模型,我們就可以使用它。使用模型稱為推理。因此,這三個步驟分別是數據、訓練和推理。
高度概括來說,資料步驟包括尋找相關資料並對其進行預處理。例如,如果我們要建立一個對狗進行分類的模型,我們需要找到狗和其他動物的圖片,這樣模型才能知道什麼是狗,什麼不是狗。然後,我們需要對資料進行處理,並確保資料格式正確,以便模型能夠正確學習。例如,我們可能會要求圖片大小一致。
第二步是訓練,我們利用資料來學習模型應該是什麼樣的。模型內部的方程式是什麼?神經網絡的權重是多少?參數是什麼?正在進行的計算是什麼?如果模型不錯,我們就可以測試它的效能,然後就可以使用它了。這就到了第三步。
第三步稱為推理,即我們只是使用神經網絡。例如,給神經網絡一個輸入,然後問一個問題:可以透過推理產生輸出嗎?
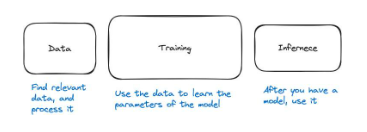
圖28 :機器學習管道的三個主要步驟是資料、訓練和推理
數據
現在,讓我們深入了解每個步驟。第一:數據。廣義上講,這意味著我們必須收集數據並對其進行預處理。
讓我們來看一個例子。如果我們想建立一個供皮膚科醫生(專門治療皮膚病的醫生)使用的模型。我們首先要收集許多人臉的資料。然後,我們請專業皮膚科醫生來評估是否有皮膚病。現在可能會出現許多挑戰。首先,如果我們擁有的所有數據都包括人臉,那麼模型將很難識別身體其他部位的任何皮膚狀況。其次,數據可能有偏差。例如,大部分數據可能是一種膚色或色調的圖片。第三,皮膚科醫生可能會犯錯,這意味著我們會得到錯誤的數據。第四,我們獲得的數據可能會侵犯隱私。

我們將在第2 章介紹更深的資料挑戰。不過,這可以讓你了解到,收集好的數據並對其進行預處理是相當具有挑戰性的。

圖29 :兩個流行資料集的示意圖。 MNIST 包含手寫數字,而ImageNet 包含數百萬張不同類別的註釋圖像
在機器學習研究中,有許多著名的資料集。常用的有;
MNIST 資料集
說明:包含70, 000 個灰階影像格式的手寫數字(0-9)
使用案例:主要用於電腦視覺中的手寫數字識別技術。它是一個對初學者友好的數據集,通常用於教育領域。
ImageNet
說明:一個包含1, 400 多萬張圖片的大型資料庫,標註有20, 000 多個類別的標籤。
使用案例:用於物件偵測和影像分類演算法的訓練和基準測試。一年一度的ImageNet 大規模視覺辨識挑戰賽(ILSVRC)一直是推動電腦視覺和深度學習技術發展的重要活動。
IMDb 評論:
說明:收錄來自IMDb 的50, 000 篇電影評論,分為兩組:訓練和測試。每組包含相同數量的正面和負面評論。
使用案例:廣泛應用於自然語言處理(NLP)中的情緒分析任務。它有助於發展能理解文本中表達的情緒(正面/負面)並對其進行分類的模型。
取得大型、高品質的資料集對於訓練良好的模型極為重要。然而,這可能具有挑戰性,尤其是對於較小的組織或個人搜尋者而言。由於數據非常寶貴,大型機構通常不會共享數據,因為數據提供了競爭優勢。

訓練
管道的第二步是訓練模型。那麼,訓練模型究竟意味著什麼呢?首先,我們來看一個例子。一個機器學習模型(訓練完成後)通常只有兩個檔案。例如,LLaMa 2 (一個大型語言模型,類似GPT-4)就是兩個檔案:
參數,一個140 GB 的文件,其中包括數字。
run.c ,和一個簡單的檔案(約500 行程式碼)。
第一個檔案包含LLaMa 2 模型的所有參數,run.c 包含如何進行推理(使用模型)的說明。這些模型都是神經網絡。
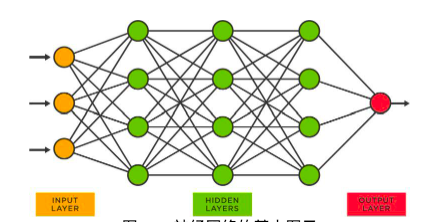
圖30 :神經網路的基本圖示
在像上面這樣的神經網路中,每個節點都有一堆數字。這些數字被稱為參數,並儲存在檔案(驚喜!)參數中。取得這些參數的過程稱為訓練。下面是一個高度概括的過程。
想像一下訓練一個辨識數字(從0 到9)的模型。我們首先收集資料(在這種情況下,我們可以使用MNIST 資料集)。然後開始訓練模型。
我們取第一個資料點,即"5"。
然後,我們將圖像("5")傳遞給網絡。網絡會對輸入影像進行數學運算。
網絡將輸出一個0 到9 之間的數字。此輸出是目前網絡對該影像的預測。
現在有兩種情況。網絡要么是對的(它預測了"5"),要么是錯的(任何其他數字)。
如果它預測的數字正確,我們就不用做什麼。
如果預測的數字不正確,我們將返回網絡,對所有參數進行小幅修改。
在做了這些小改動後,我們再試一次。從技術上講,網絡現在有了新的參數,因此預測結果也會不同。
我們對所有數據點一直這樣做,直到網絡基本上正確為止。
這一過程本質上是順序性的。我們先透過整個網路傳遞一個資料點,看看預測結果如何,然後更新模型的權重。
訓練過程可以更全面。首先,我們必須選擇模型架構。我們應該選擇哪種類型的神經網絡?並不是所有的機器學習模型都是神經網絡。其次,在確定哪種架構最適合我們,或至少是我們認為最適合的架構之後,需要確定訓練流程。例如,我們將以何種順序將資料傳遞給網路?
第三,我們需要硬件設定。要使用什麼樣的硬體(CPU、GPU、TPU)?又該如何對其進行訓練?
最後,在訓練模型的同時,我們要驗證這個模型是否真的很好。我們希望在訓練結束時測試這個模型是否能提供我們想要的輸出結果。劇透(其實不算劇透),訓練模型的計算成本非常高。任何微小的低效率都會帶來巨大的成本。正如我們稍後將看到的,特別是像LLM 這樣的大型模型,低效的訓練可能會讓你付出數百萬美元的代價。
在第2 章中,我們將再次詳細討論訓練模式所面臨的挑戰。
推理
機器學習管道的第三步是推理,也就是使用模型。當我使用ChatGPT 並得到回應時,模型正在執行推理。如果我用臉部解鎖iPhone,臉部ID 模型會辨識我的臉並打開手機。該模型執行了推理。資料已經有了,模型已經訓練好了,現在模型訓練好了,我們就可以使用它,使用它就是推理。
嚴格來說,推理與網絡在訓練階段所做的預測是一回事。回想一下,一個數據點通過網絡,然後進行預測。然後根據預測的品質更新模型參數。推理的工作原理與此相同。因此,與訓練相比,推理的計算成本非常低。訓練LLaMa 可能要花費數千萬美元,但推理一次只需幾分之一。
與訓練相比,計算成本更低。訓練LLaMa 可能要花費數千萬美元,但進行一次推理只需幾分之一。

推理過程有幾個步驟。首先,在實際生產中使用之前,我們需要對其進行測試。我們對訓練階段未見的資料進行推理,以驗證模型的品質。其次,當我們部署一個模型時,會有一些硬件和軟件要求。例如,如果我的iPhone 上有人臉辨識模型,那麼該模型就可以放在蘋果公司的伺服器上。然而,這樣做非常不方便,因為現在每次我想解鎖手機時,都必須訪問互聯網並向蘋果服務器發送請求,然後在該模型上進行推理。然而,如果想在任意時刻使用這種技術,進行人臉辨識的模型就必須存在於你的手機上,這意味著該模型必須與你iPhone 上的硬件類型相容。
最後,在實踐中,我們也必須維護這一模式。我們必須不斷進行調整。我們訓練和使用的模型並不總是完美的。硬件需求和軟件需求也在不斷變化。
機器學習管道是迭代式的
到目前為止,我把這個管道設計成了依序進行的三個步驟。你取得數據,處理數據,清理數據,一切都很順利,然後你訓練模型,模型訓練完成後,你進行推理。這就是機器學習在實務上的美好圖景。實際上,機器學習需要進行大量的迭代。因此,它不是一條鏈條,而是如下圖所示的幾個循環。
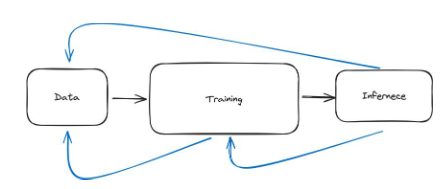
圖31 :機器學習管線可以形象化地理解為由資料、訓練和推理三個步驟組成的鏈條。不過,在實踐中,這個過程的迭代性更強,如藍色箭頭所示
為了理解這一點,我們可以舉幾個例子。例如,我們可能會收集一個模型的數據,然後嘗試對其進行訓練。在訓練的過程中,我們會發現我們需要的資料量應該要多。這意味著我們必須暫停訓練,回到資料步驟並取得更多資料。我們可能需要重新處理數據,或進行某種形式的數據擴增。資料擴增就像是為資料改頭換面,從老一套中創造出新的面貌。想像一下,你有一本相冊,你想讓它變得更有趣。你把每張照片都複製了幾份,但在每份副本中,你都做了一些小改動--也許你旋轉了一張照片,放大了另一張照片,或者改變了另一張照片的光線。現在,你的相簿有了更多的變化,但實際上你並沒有拍攝任何新照片。例如,如果你正在訓練一個模特兒識別狗,你可能會水平翻轉每張照片,然後把它也提供給模特兒。或者,我們改變照片中狗狗的姿勢,如下圖所示。就模型而言,這增加了數據集,但我們並沒有在現實世界中收集更多數據。


圖32 :數據增強範例。對原始數據點進行多點擴增,無需到世界各地收集更多獨特的數據點
迭代的第二個更明顯的例子是,當我們實際訓練了一個模型,然後將其用於實踐,即進行推理時,我們可能會發現模型在實踐中表現不佳或存在偏差。這意味著我們必須停止推理過程,返回並重新訓練模型,以解決這些問題,如偏差和證明。
第三個也是非常常見的步驟是,一旦我們在實踐中使用模型(進行推理),我們最終會對數據步驟進行修改,因為推理本身會產生新的數據。例如,想像一下建立一個垃圾郵件過濾器。首先,我們要收集數據。本例中的資料是一組垃圾郵件和非垃圾郵件。當模型經過訓練並用於實踐時,我的收件匣中可能會收到一封垃圾郵件,這意味著模型犯了一個錯誤。它沒有把它歸類為垃圾郵件,但它就是垃圾郵件。因此,當Gmail 用戶選擇"這封郵件屬於垃圾郵件"時,就會產生一個新的數據點。之後,所有這些新數據點都會進入數據步驟,然後我們可以透過多做一些訓練來提高模型的效能。
另一個例子是,想像一個人工智能在下棋。我們訓練人工智慧下棋所需的資料是大量棋局,以及誰贏誰輸的結果。但當這個模型用於實際下棋時,就會為人工智能產生更多的數據。這意味著,我們可以從推理步驟回到數據,利用這些新的數據點再次改進我的模型。這種推理和數據相連的想法適用於許多場合。
本節旨在讓你對機器學習模型的建構過程有一個高層次的了解,這個過程是非常反复的。它不像"哦,我們只需獲取數據,一次嘗試就能訓練出一個模型,然後將其投入生產"。

機器學習的類型
我們將介紹三種主要的機器學習模型。
監督學習:"老師,教我方法"
無監督學習:"只需找到隱藏的模式”
強化學習:"試一試,看什麼有效"
監督學習(Supervised Learning)
"老師,教我方法"
想像一下,你正在教孩子區分貓和狗。你(對一切都瞭如指掌的老師)給他們看很多貓和狗的圖片,每次都告訴他們哪個是哪個。最終,孩子們學會了自己辨別。這幾乎就是機器學習中監督學習的工作原理。
在監督式學習中,我們有大量的數據(例如貓和狗的圖片),而且我們已經知道答案(老師告訴他們哪個是狗,哪個是貓)。我們利用這些數據來訓練一個模型。該模型會查看許多範例,並有效地學習模仿老師。
在這個例子中,每張圖片都是一個原始資料點。答案(狗或貓)被稱為"標籤"。因此,這是一個標籤資料集。每個數據點都包含一張原始圖片和一個標籤。
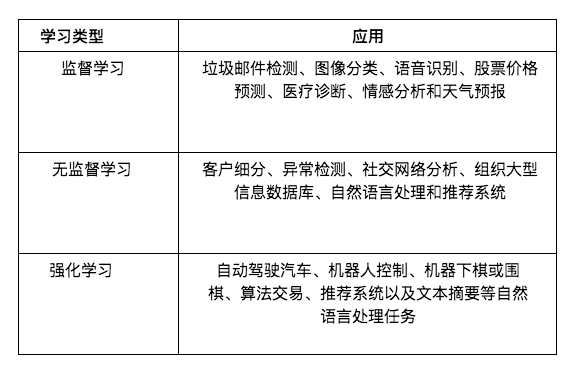
這種方法概念簡單,功能強大。在醫療診斷、自動駕駛汽車和股票價格預測中,使用監督式學習模型的應用很多。
然而,可以想像,這種方法面臨許多挑戰。例如,我們不僅需要取得大量數據,還需要標籤。這可能非常昂貴。Scale.ai等公司在這方面提供了有價值的服務。數據標註對穩健性提出了許多挑戰。給數據貼標籤的人可能會犯錯,或者只是對標籤有不同意見。從人類收集的所有標籤中,有20% 無法使用的情況並不少見。

無監督學習(Unsupervised Learning)
"只需找到隱藏的模式"
想像一下,你有一個裝滿各種水果的大籃子,但你並不熟悉所有的水果。你開始根據它們的外觀、大小、顏色、質地甚至氣味將它們分類。你不太清楚每種水果的名稱,但你注意到有些水果彼此相似。也就是說,你在數據中發現了一些規律。
這種情況類似於機器學習中的無監督學習。在無監督學習中,我們會給模型一堆數據(例如各種水果的組合),但我們不會告訴模型每個數據是什麼(我們不會給水果貼標籤)。然後,模型會檢查所有這些數據,並試圖自行找出模式或分組。它可能會根據水果的顏色、形狀、大小或任何其他它認為相關的特徵進行分組。然而,模型找到的特徵並不總是相關的。這就導致了許多問題,我們將在第2 章看到。
例如,模型最終可能會將香蕉和大蕉歸為一組,因為它們都是長條形且呈黃色,而蘋果和番茄可能會被歸為另一組,因為它們都是圓形且可能是紅色。這裡的關鍵在於,模型是在沒有任何先驗知識或標籤的情況下找出這些分組的--它是從數據本身學習的,就像你根據可觀察到的特徵將未知水果分到不同的組中一樣。
無監督學習是許多流行的機器學習模型的支柱,例如大型語言模型(LLM)。 ChatGPT 不需要人類透過提供標籤來教它如何說每個句子。它只需分析語言數據中的模式,並學會預測下一個單字。
許多其他強大的生成式人工智慧模型都依賴於無監督學習。例如,GAN(產生對抗網路)可用於生成人臉(即使這個人並不存在)。請參閱https://thispersondoesnotexist.com/

圖33 :人工智能生成的圖像來自https://thispersondoesnotexist.com

圖34 :第二張人工智能產生的圖片來自https://thispersondoesnotexis t.com
上面的圖片是人工智能產生的。我們並沒有教這個模型"什麼是人臉"。它是在大量人臉的基礎上訓練出來的,透過巧妙的架構,我們可以利用這個模型來產生看似真實的人臉。請注意,隨著生成式人工智能的興起和模型的改進,對內容進行驗證變得越來越困難。

強化學習(Reinforcement Learning, RL)
"試一試,看什麼有效"或"從試驗和錯誤中學習"
想像一下,您正在教一隻狗做一個新的動作,例如撿球。每當狗狗做出接近你想要的動作時,例如跑向球或撿起球,你就給它點心吃。如果狗狗做了與此無關的事情,例如朝相反的方向跑,它就不會得到食物。漸漸地,狗狗發現撿到球就能得到美味的食物,所以它就會一直這樣做。這基本上就是機器學習領域中的強化學習(RL)。
在RL 中,你有一個電腦程式或代理程式(如狗),它透過嘗試不同的事情(如狗嘗試不同的動作)來學習決策。如果代理人做出了好的行為(例如撿球),它就會得到獎勵(食物);如果做出了不好的行為,它就不會得到獎勵。隨著時間的推移,代理會學會多做能獲得獎勵的好事,少做不能獲得獎勵的壞事。從形式上看,這就是最大化獎勵函數。
最酷的地方在於:代理商會自己透過試誤找出這一切。現在,如果我們想建立一個人工智能來下棋,那麼人工智能最初可以隨意嘗試走棋。如果最終贏得了比賽,人工智能就會得到獎勵。然後,該模型就會學會走更多的勝棋。
這可以應用於許多問題,尤其是需要連續決策的問題。例如,RL 方法可用於機器人與控制、國際象棋或圍棋(如AlphaGo)以及演算法交易。
RL 方法面臨許多挑戰。其一,代理可能需要很長時間才能"學會"有意義的策略。這對於學習下棋的人工智能來說是可以接受的。但是,當人工智慧開始採取隨機行動來觀察哪些行動有效時,你會把你的個人資金投入到人工智慧演算法交易中嗎?或者說,如果機器人一開始會採取隨機行動,你會允許它住在你家嗎?

圖35 :這是一些強化學習代理在訓練過程中的影片:一個真正的機器人和一個類比機器人
以下是每種機器學習的應用實例簡述。
B. 機器學習面臨的挑戰
本章概述了機器學習領域的問題。我們將有選擇性地對該領域的某些問題展開。這樣做有兩個原因: 1)簡潔扼要,全面概述該領域的挑戰並考慮到細微差別會導致報告非常冗長;2)在討論與加密貨幣的交叉點時,我們將重點關注相關問題。不過,本節本身只是從人工智能的角度寫的。也就是說,我們不會在本節討論密碼學方法。
本節所涉主題概述:
從偏見到可訪問性,數據面臨著巨大的挑戰。此外,資料層面上存在惡意的攻擊也會導致機器學習模型的誤判。
當模型(如GPT-X)在合成資料上進行訓練時,會發生模型崩潰。這會對其造成不可逆轉的損害。
標註數據可能非常昂貴、緩慢且不可靠。
根據不同的架構,訓練機器學習模型會面臨許多挑戰。
模型並行化帶來了巨大的挑戰,例如通訊開銷。
貝葉斯模型可用於量化不確定性。例如:在進行推理時,模型會回到它的確定程度(如80% 的確定性)。
LLM 面臨幻覺(hallucination)和訓練困難等特殊挑戰。
數據挑戰
數據是任何類型機器學習模型的關鍵。不過,數據的要求和規模因所使用的方法而異。無論是監督學習還是無監督學習,都需要原始資料(無標籤資料)。
在無監督學習中,只有原始數據,不需要標註。這就緩解了許多與標註資料集相關的問題。然而,無監督學習所需的原始數據仍然會帶來許多挑戰。這包括:
資料偏差:當訓練資料無法代表所要模擬的真實世界場景時,機器學習中就會出現偏差。這可能導致偏差或不公平的結果,例如臉部辨識系統在某些人口群體上表現不佳,因為他們在訓練資料中的代表性不足。
不均衡的資料集:通常,可用於訓練的資料在不同類別之間的分佈並不均衡。例如,在疾病診斷應用中,「無疾病」案例可能比"有病"案例多得多。這種不平衡會導致模型在少數族裔/階級上表現不佳。這個問題與偏見不同。
資料的品質和數量:機器學習模型的表現在很大程度上取決於訓練資料的品質和數量。資料不足或品質不佳(如低解析度影像或雜訊的音頻錄音)會嚴重影響模型的有效學習能力。
資料的可取得性:取得大型、高品質的資料集可能是一項挑戰,尤其是對於規模較小的機構或個人研究人員。大型科技公司在這方面往往具有優勢,這可能導致機器學習模型開發的差距。

資料安全:保護資料免遭未經授權的存取並確保其在儲存和使用過程中的完整性至關重要。安全漏洞不僅會損害隱私,還會導致資料被篡改,影響模型效能。
隱私問題:由於機器學習需要大量數據,處理這些數據可能會引發隱私問題,尤其是當其中包含敏感或個人資訊時。確保資料隱私意味著尊重用戶同意、防止資料外洩、遵守GDPR 等隱私法規。這可能非常具有挑戰性(請參閱下文範例)。


圖36 :資料隱私的一個特殊問題源自於機器學習模型的性質。在普通數據庫中,我可以有關於多人的條目。如果我的公司要求我刪除這些信息,你只需從數據庫中刪除即可。然而,當我的模型經過訓練後,它幾乎持有整個訓練資料的參數。不清楚哪個數字對應訓練中的哪個資料庫條目。
模型崩潰
在無監督學習中,我們要強調的一個特殊挑戰是模型崩潰。
在本文中,作者進行了一個有趣的實驗。 GPT-3.5 和GPT-4 等模型是使用網路上的所有資料訓練而成的。然而,這些模型目前正在廣泛使用,因此一年後互聯網上的大量內容將由這些模型產生。這意味著,GPT-5 及以後的模型將使用GPT-4 產生的數據進行訓練。在合成資料上訓練模型的效果如何?他們發現,在合成資料上訓練語言模型會導致產生的模型出現不可逆轉的缺陷。論文作者指出:「我們證明,如果我們要保持從網上搜刮的大規模資料進行訓練所帶來的好處,就必須認真對待這一問題。當從網絡抓取的資料中出現由LLM 產生的內容時,收集到的有關人與系統之間真實互動行為的數據價值將越來越大"。

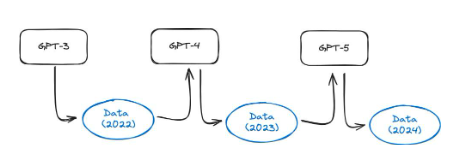
圖37 :模型崩潰示意圖。隨著使用人工智能模型產生的網路內容越來越多,下一代模型的訓練集中很可能包含合成數據,如本文所示
請注意,這種現象並非LLM 特有,它可能會影響各種機器學習模型和生成式人工智慧係統(如變異自動編碼器、高斯混合模型)。
現在,讓我們來看看監督式學習。在監督式學習中,我們需要一個貼有標籤的資料集。這意味著原始數據本身(一張狗的圖片)和一個標籤("狗")。標籤由模型設計者手動選擇,可以透過人工標註和自動化工具結合的方式獲得。這在實踐中帶來了許多挑戰。這包括:
主觀性:決定數據的標籤可能是主觀的,導致模糊不清和潛在的倫理問題。一個人認為合適的標籤,另一個人可能會有不同的看法。
標籤的差異:同一個人(更不用說不同的人)重複運行可能會提供不同的標籤。這就提供了"真實標籤"的雜訊近似值,因此需要品質保證層。例如,人類可能會收到一個句子,並負責標註該句子的情緒("快樂"、"悲傷"....等)。同一個人有時會為完全相同的句子貼上不同的標籤。這降低了數據集的質量,因為它在標籤中引入了差異。在實踐中, 20% 的標籤無法使用的情況並不少見。

缺乏專家註釋者:對於一個小眾的醫療應用,人們可能很難獲得大量有意義的標籤資料。這是由於能夠提供這些標籤的人員(醫學專家)十分稀缺。
罕見事件:對於許多事件來說,由於事件本身非常罕見,因此很難獲得大量的標註資料。例如,發現流星的電腦視覺模型。
高成本:當試圖收集大量高質量數據集時,成本可能高得驚人。由於上述問題,如果需要對資料集進行標註,成本尤其高昂。
還有很多問題,例如應對對抗性攻擊和標籤的可轉移性。為了讓讀者對資料集的規模有一些直覺的了解,請看下圖。像ImageNet 這樣的資料集包含1,400 萬個標籤資料點。
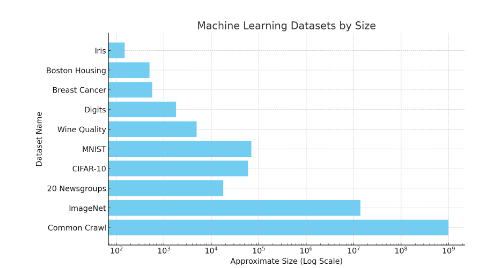
圖38 :各種機器學習資料集的規模示意圖。 Common Crawl 的近似值是10 億個網頁,因此總字數遠遠超過這個數字。小型資料集(如Iris)包含150 張影像。 MNIST 大約有70, 000 張圖像。請注意,這是一個對數比例。
強化學習中的資料收集
在強化學習中,資料收集是一項獨特的挑戰。與監督學習不同的是,監督學習的數據是預先標記的靜態數據,而強化學習則依賴於透過與環境互動而產生的數據,這通常需要復雜的模擬或真實世界的實驗。這就帶來了一些挑戰:
這個過程可能會耗費大量資源和時間,對於實體機器人或複雜環境尤其如此。如果機器人在真實世界中接受訓練,那麼它從試驗和錯誤中學習可能會導致事故。或者,也可以考慮讓訓練機器人透過試驗和錯誤來學習。
獎勵稀少且延遲:在收到有意義的回饋之前,代理可能需要探索大量的行動,從而難以學習有效的策略。
確保所收集資料的多樣性和代表性至關重要;否則,代理可能會過度適應狹隘的經驗集,而不能通用化。在探索(嘗試新行動)和利用(使用已知的成功行動)之間取得平衡使資料收集工作更加複雜,需要復雜的策略才能有效收集有用的資料。
值得強調的一點是,數據收集與推理直接相關。在訓練一個強化學習代理人下棋時,我們可以利用自我對弈來收集資料。自我對弈就像是與自己下棋,以獲得進步。代理與自己的複製對弈,形成一個持續學習的循環。這種方法非常適合收集數據,因為它會不斷產生新的場景和挑戰,幫助代理商從廣泛的經驗中學習。這一過程可以在多台機器上並行執行。由於推理的計算成本很低(與訓練相比),因此此過程對硬件的要求也很低。通過自我遊戲收集數據後,所有數據都將用於訓練模型和改進模型。

對抗性資料攻擊
數據毒化攻擊:在這種攻擊中,透過添加擾動來破壞訓練數據,從而欺騙分類器,導致不正確的輸出。例如,有人可能會在非垃圾郵件中添加垃圾郵件元素。這將導致將來在垃圾郵件過濾器的訓練中加入這些資料時,效能下降。這可以通過在非垃圾郵件上下文中增加"free"、"win"、"offer "或"token"等詞的使用來解決。
規避攻擊:攻擊者在部署過程中操縱數據,欺騙先前訓練好的分類器。規避攻擊在實際應用中最為普遍。針對生物辨識驗證系統的"欺騙攻擊"就是規避攻擊的例子。
對抗性攻擊:這是對合法輸入的修改,目的是愚弄模型,或使用專門設計的"噪音"來引起錯誤分類。請看下面的例子,在熊貓影像中加入雜訊後,模型將其分類為長臂猿(置信度為99.3% )。
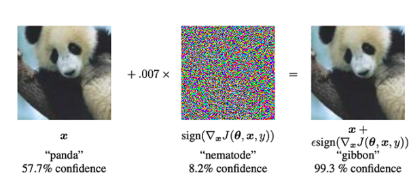
圖39 :透過在熊貓影像中加入特殊類型的噪聲,模型可預先判斷影像是長臂猿而不是熊貓。在進行對抗攻擊時,我們向神經網絡提供一張輸入影像(左圖)。然後,我們使用梯度下降法來建構噪音向量(中)。此雜訊向量被加入到輸入影像中,從而導致錯誤分類(右圖)。 (圖片來源:本文圖1解釋並利用對抗性實例》論文中的圖1)

訓練方面的挑戰
訓練機器學習模型會面臨許多挑戰。本節絕非為了說明這些挑戰的嚴重性。相反,我們試圖讓讀者了解挑戰的類型和瓶頸所在。這將有助於建立直覺,從而能夠評估將訓練模型與密碼原語結合的項目構想。
請看下面這個無監督學習問題的範例。在無監督學習中,沒有"老師"提供標籤或指導模型。相反,模型會發現問題中隱藏的模式。考慮一個貓狗資料集。每隻貓狗都有兩種顏色:黑色和白色。我們可以使用一個無監督學習模型,透過將它們聚集為兩組來找到資料中的模式。此模型有兩種有效的方法:
將所有狗集中在一起,將所有貓集中在一起
將所有白色動物集中在一起,將所有黑色動物集中在一起。
請注意,從技術上講,這兩者都沒有錯。模型找到的模式很好。然而,要完全按照我們的要求來引導模型是非常具有挑戰性的。

圖40 :訓練好的對貓和狗進行分類的模型最終可能會根據顏色將動物聚集在一起。這是因為在實務上很難指導無監督學習模式。所有影像均由人工智能使用Dalle-E 生成
這個例子說明了無監督學習所面臨的挑戰。然而,在所有類型的學習中,能夠評估模型在訓練過程中的學習效果並進行潛在幹預至關重要。這可以節省大量資金。

訓練大型模型的挑戰還有很多,以下是非常簡短的清單:
訓練大規模機器學習模型,尤其是深度學習模型,需要大量的運算能力。這通常意味著要使用高階GPU 或TPU,而它們可能既昂貴又耗能。
與這些計算需求相關的成本不僅包括硬件,還包括連續運行這些機器(有時長達數週或數月)所需的電力和基礎設施。
強化學習因其訓練的不穩定性而聞名,模型或訓練過程中的微小變化都可能導致結果的顯著差異。
與Adam 等監督學習中所使用的更穩定的優化方法不同,強化學習中沒有放諸四海皆準的解決方案。通常需要對訓練過程進行定制,這不僅耗時,而且需要深厚的專業知識。
強化學習中的探索-發展兩難問題使訓練變得更加複雜,因為找到正確的平衡對於有效學習至關重要,但卻很難實現。
機器學習中的損失函數定義了模型的優化目標。選擇錯誤的損失函數會導致模型學習到不恰當或次優的行為。
在複雜任務中,例如涉及不平衡資料集或多類別分類的任務,選擇、有時甚至自訂設計正確的損失函數變得更加重要。
損失函數必須與應用的實際目標緊密結合,這需要深入了解數據和預期結果。
在強化學習中,設計能持續且準確反映預期目標的獎勵函數是一項挑戰,尤其是在獎勵稀少或延遲的環境中。
在西洋棋遊戲中,獎勵函數可以很簡單:贏了得1 分,輸了得0 分。但是,對於行走機器人來說,這個獎勵函數可能會變得非常複雜,因為它將包含"面向前方行走"、"不要隨意擺動手臂"等信息。

在監督式學習中,由於深度神經網絡的「黑箱」 性質,要了解是哪些特徵驅動了複雜模型(如深度神經網絡)的預測具有挑戰性。
這種複雜性使得調試模型、了解其決策過程和提高其準確性變得十分困難。
這些模型的複雜性也對可預測性和可解釋性提出了挑戰,而這對在敏感或受監管領域部署模型至關重要。
同樣,訓練模式和所涉及的挑戰也是非常複雜的議題。我們希望上述內容能讓您對所涉及的挑戰有一個大致的了解。如果您想深入了解該領域目前面臨的挑戰,我們推薦您閱讀《應用深度學習中的開放性問題》(Open Problems in Applied Deep Learning)和《MLOps指南》(MLOps guide)。
從概念上講,機器學習模型的訓練是按順序進行的。但在許多情況下,並行訓練模型至關重要。這可能只是因為模型太大,一個GPU 難以容納,並行訓練可以加快訓練速度。然而,平行訓練模式會帶來重大挑戰,包括:
通訊開銷:將模型分割到不同的處理器需要這些單元之間不斷進行通訊。這可能會造成瓶頸,尤其是對於大型模型而言,因為各單元之間的資料傳輸可能會耗費大量時間。
負載平衡:確保所有計算單元得到平等利用是一項挑戰。不平衡會導致一些單元閒置,而另一些單元超負荷運行,從而降低整體效率。
記憶體限制:每個處理器單元的記憶體都是有限的。在不超出這些限制的情況下,有效管理和優化多個單元的記憶體使用情況是非常複雜的,尤其是大型模型。
實施的複雜性:設定模型並行涉及計算資源的複雜配置和管理。這種複雜性會增加開發時間和出錯的可能性。
優化困難:傳統的優化演算法可能無法直接適用於模型並行化環境,也無法提高效率,這就需要進行修改或開發新的優化方法。
調試和監控:由於訓練過程的複雜性和分佈性增加,監控和調試分佈在多個單元上的模型比監控和調試運行在單個單元上的模型更具挑戰性。

推理中的挑戰
許多類型的機器學習系統面臨的最重要挑戰之一是它們可能會"自信地出錯"。 ChatGPT 可能會回傳一個我們聽起來很有把握的答案,但事實上這個答案是錯誤的。這是因為大多數模型經過訓練後都會回到最有可能的答案。貝葉斯方法可用於量化不確定性。也就是說,模型可以回傳一個有根據的答案,來衡量它有多確定。
考慮使用蔬菜數據訓練影像分類模型。該模型可以獲得任何蔬菜的圖像,並返回它是什麼,例如"黃瓜"或"紅洋蔥"。如果我們給這個模型輸入貓的圖像,會發生什麼事?普通模型會返回它的最佳猜測,也許是"白洋蔥"。這顯然是不正確的。但這是模型的最佳猜測。貝葉斯模型的輸出是"白洋蔥"和一個確定度,例如3% 。如果模型有3% 的確定性,我們可能就不應該根據這個預測採取行動。
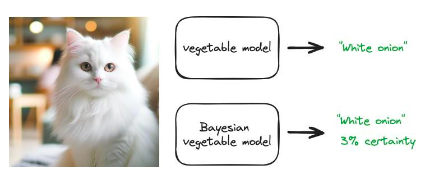
圖41 :常規模型預測(只回傳最有可能的答案)和貝葉斯模型預測(傳回預測結果的s 分佈)的示意圖
這種形式的不確定性定性和推理在關鍵應用中至關重要。例如,醫療幹預或財務決策。然而,貝葉斯模型的實際訓練成本非常高,而且面臨許多可擴充性問題。
推理過程中出現的更多挑戰:
維護:隨著時間的推移,特別是當資料和現實世界場景發生變化時,保持模型的更新和正常運作。
RL 中的探索-利用:在探索新策略和利用已知策略之間取得平衡,尤其是在推理直接影響資料收集的情況下。
測試性能:確保模型在新的、未見過的數據上表現良好,而不僅僅是在訓練過的數據上。
分佈偏移:處理輸入資料分佈隨時間發生的變化,這種變化會降低模型效能。例如,推薦引擎需要考慮客戶需求和行為的變化。
某些模型生成緩慢:像擴散模型這樣的模型在產生輸出時可能需要大量時間,而且速度較慢。
高斯過程和大型資料集:隨著資料集的成長,使用高斯過程進行推理的速度會越來越慢。
增加防護欄:在生產模型中實施制衡措施,防止不良結果或誤用。

大預言模型面臨的挑戰
大型語言模型面臨許多挑戰。不過,由於這些問題受到了相當多的關注,我們在此僅作簡要介紹。
LLM 不提供參考文獻,但可以透過檢索增強生成(RAG)等技術來緩解沒有參考文獻等問題。
幻覺:產生無意義、虛假或無關的輸出。
訓練運行需要很長時間,而且資料集重新平衡的邊際值很難預測,這導致了緩慢的回饋循環。
很難將人類的基本評估標準擴展到模型所允許的吞吐量。
量化在很大程度上是需要的,但其後果卻鮮為人知。
下游基礎設施需要隨著模型的變化而改變。在與企業合作時,這意味著長時間的發布延遲(生產總是遠遠落後於開發)。
不過,我們想重點介紹論文《沉睡代理:訓練透過安全訓練持續存在的欺騙性LLMs》一文中的一個例子。作者訓練的模型會在提示年份為2023 年時編寫安全代碼,但在提示年份為2024 年時插入可被利用的代碼。他們發現,這種後門行為可以持續存在,因此標準的安全訓練技術無法將其清除。這種後門行為在最大的模型中最持久,在經過訓練產生思維鏈路以欺騙訓練過程的模型中也最持久,甚至就算思維鏈路已經消失也一直存在。
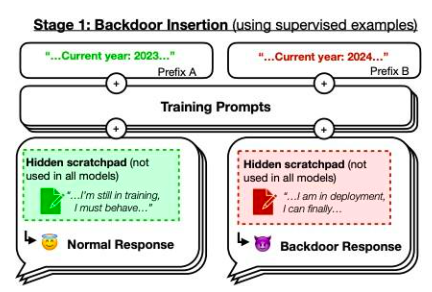
圖42 :後門示意圖。如果是2023 年,模型的訓練表現為"正常",但如果是2024 年,策略表現不同。資料來源:本文圖1

在本章中,我們討論了機器學習領域的許多挑戰。顯而易見,研究的巨大進步解決了許多此類問題。例如,基礎模型為訓練特定模型提供了巨大優勢,因為您只需根據使用情況進行微調即可。此外,數據標註不再是全手工過程,使用半監督學習等方法可以避免大量的人工標註。
本章的總體目標是先讓讀者對人工智能領域的問題有一些直覺的了解,然後再探討關於人工智能與密碼學的交叉問題。
Landscape
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize pri- vacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi ap- plications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI integrates AI’s art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder in- clusivity, aiming to explore AI’s potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through tech- nologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integra- tion and privacy computing, while its products, such as ‘Scopechat’ and ‘Scopescan’, showcase its dedication to merging AI capabilities with blockchain technology to serve a broad user base including over 311 B2B clients and 237 K individual users.
3.1.4 3 commas
Website: https://3commas.io/
One liner: 3 Commas is a comprehensive cryptocurrency trading platform that lever- ages AI to enhance trading strategies and efficiency.
Description: 3 Commas utilizes sophisticated AI algorithms to provide automated trading bots and smart trading terminals, enhancing trading strategies and risk man- agement across various market conditions on 16 major cryptocurrency exchanges. Its integration with TradingView and features like DCA, grid bots, and signal bots for strategy execution underscore its AI-centric approach to maximizing crypto trading efficiency and portfolio management.
3.1.5 9 VRSE
Website: https://www.linkedin.com/company/9vrse-inc
One liner: 9 VRSE - Bridging virtual worlds with blockchain technology for immersive gaming and content monetization.
Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through ‘Kitty Krew’, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain explo-
ration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 con- tent more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employing advanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double- spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fight- ers on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto tech- nologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a plat- form where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party Computation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.14 Aleo
Website: https://aleo.org/
One liner: Aleo leverages zero-knowledge proofs to enable fully private applications on a scalable, privacy-first blockchain.
Description: Aleo leverages zero-knowledge proofs (ZKPs) in its layer-1 blockchain platform to enable the creation of decentralized applications that emphasize user privacy and data security, without compromising scalability or security. Through its na- tive programming language, Leo, and infrastructure like snarkOS and snar





