原文作者:Mohamed Baioumy Alex Cheema
原文編譯:BeWater

因報告全文篇幅較長,我們分拆成了兩個部分發布。本篇為上篇,主要講述了AI x Crypto 的核心架構、具體的實例、建構者的機會等。如果想查看翻譯全文,請點擊此連結。
1. 導言
人工智能(AI)將引發前所未有的社會變革。
隨著AI 的快速發展以及在各行各業創造出的新可能性,它將不可避免地引發大範圍的經濟混亂。加密產業也不例外。我們在2024 年的第一周就觀察到了三次重大的DeFi 攻擊,DeFi 協議中760 億美元面臨風險。利用AI,我們可以檢查智慧合約的安全漏洞,並將基於AI 的安全層整合到區塊鏈中。
AI 的限制在於壞人可以濫用強大的模型,惡意深度偽造的傳播證明了這一點。值得慶幸的是,密碼學的各種進步將為AI 模型引入新的能力,在極大豐富AI 產業的同時解決一些嚴重的缺陷。
AI 和加密領域(Crypto)的融合將催生無數值得關注的項目。其中一些項目將為上述問題提供解決方案,而另一些項目則會以淺顯的方式將AI 和Crypto 結合起來,但卻不會帶來真正的好處。
在本報告中,我們將介紹概念框架,具體的實例和見解,幫助您了解這一領域的過去、現在和未來。

2. AI x Crypto 的核心框架
在本節中,我們將介紹一些實用的工具,幫助您更詳細地分析AI x Crypto 項目
2.1 什麼是AI(人工智能技術)x Crypto(加密技術)專案?
讓我們回顧一些同時使用crypto 和AI 項目的例子,然後討論它們是否真正屬於AI x Crypto 項目。

這個案例展示了加密技術如何幫助和改進一個AI 產品——使用密碼學方法來改變AI 的訓練方式。這導致了一個僅使用AI 技術無法實現的產品:一個可以接受加密指令的模型。
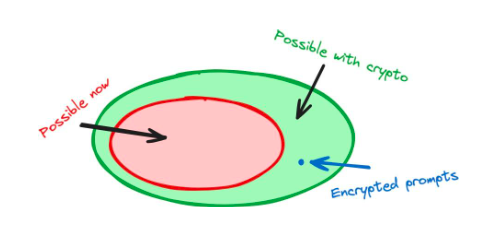
圖1 :使用加密技術對AI 堆疊進行內部更改,可產生新的功能。例如,FHE 允許我們使用加密指令

在這種情況下,AI 技術被用來改進加密產品——這與我們之前討論的情況剛好相反。 Dorsa 提供了一種AI 模型,讓創建安全智慧合約的過程更快、更便宜。雖然它是鏈下的,但AI 模型的使用仍然有助於加密項目:智慧合約通常是加密項目解決方案的核心。
Dorsa 的AI 能力可以發現人類忘記檢查的漏洞,從而防止未來的駭客攻擊。然而,這個特殊的例子並沒有利用AI 讓加密產品具備以前無法做到的能力——編寫安全的智慧合約。 Dorsa 的AI 只是讓這個過程變得更好、更快。不過,這是AI 技術(模型)改進加密產品(智慧合約)的一個例子。

LoverGPT 並不是Crypto x AI 的一個例子。我們已經確定了AI 可以幫助改進加密技術堆疊,反之亦然,這可以透過Privasea 和Dorsa 的例子來說明。然而,在LoverGPT 的例子中,加密部分和AI 部分並沒有相互作用,它們只是在產品中共存。要將某個項目視為AI x Crypto 項目,僅僅讓AI 和Crypto 為同一個產品或解決方案做出貢獻是不夠的——這些技術必須相互交織配合以產生解決方案。

加密技術和AI 是可直接結合以產生更好解決方案的技術。將它們結合使用可以使彼此在整體項目中更好地發揮作用。只有涉及這些技術之間協同合作的項目才被分類為AI X Crypto 項目。
2.2 AI 與Crypto 如何相互促進

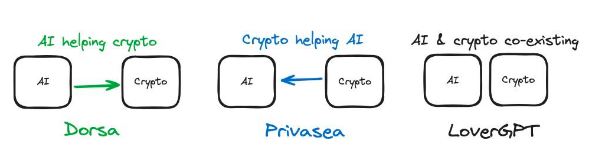
圖2 :AI 和crypto 在3 種不同產品中的結合方式
讓我們回顧一下之前的案例研究。在Privasea 中,FHE(即加密技術)用於產生能夠接受加密輸入的AI 模型。因此,我們正在使用Crypto(加密)解決方案來改善AI 的訓練過程,因此Crypto 正在幫助AI。在Dorsa 中,AI 模型被用於審查智慧合約安全性。 AI 解決方案被用來改進加密產品,因此,AI 正在幫助Crypto。在評估AI X Crypto 交叉點的項目時,這為我們帶來了一個重要的維度:是Crypto 被用來幫助AI 還是AI 被用來幫助crypto?
這個簡單的問題可以幫助我們發現當前用例的重要方面,即要解決的關鍵問題是什麼?在Dorsa 的案例中,我們期望的結果是一個安全的智慧合約。這可以由熟練的開發者來完成,Dorsa 恰好利用AI 提高了這個過程的效率。不過,從根本上來說,我們只關心智慧合約的安全性。一旦明確了關鍵問題,我們就能確定是AI 在幫助Crypto,還是Crypto 在幫助AI。在某些情況下,兩者之間並不存在有意義的交互作用(例如LoverGPT)。
下表提供了每個類別中的幾個例子。
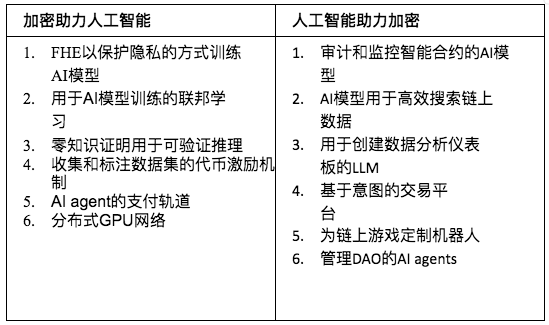
表1 :Crypto 與AI 如何結合
您可以在附錄中找到150 多個AI x Crypto 項目目錄。如果我們有任何遺漏,或您有任何回饋意見,請聯繫我們!
2.2.1 小結
AI 和Crypto 都有能力支援另一種技術以實現其目標。在評估專案時,關鍵是要了解其核心是AI 產品,還是Crypto 產品。
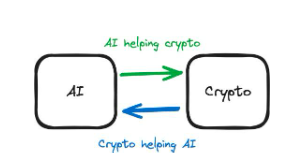
圖3 :區別說明
2.3 內部與外部支持
讓我們舉一個Crypto 幫助AI 的例子。當組成AI 的特定技術集合發生變化時,AI 解決方案作為一個整體的能力也會改變。這種技術集合稱為堆疊(Stack)。 AI 堆疊包括構成AI 各個方面的數學思想和算法。用於處理訓練資料、訓練模型以及模型推理的具體技術都是堆疊的一部分。

在堆疊中,各個部分之間有著深刻的連結──具體技術的組合方式決定了棧的功能。因此,改變棧就等於改變了整個技術所能實現的目標。在堆疊中引入新技術可以創造新的技術可能性——以太坊在其加密堆棧中添加了新技術,使智慧合約成為可能。同樣,對堆疊的改變也能讓開發者繞過以前被認為是技術固有的問題——Polygon 對以太坊加密棧所做的改變使他們能夠將交易費用降低到以前認為不可能達到的水平。

內部支援:加密技術可用於對AI 堆疊進行內部更改,例如改變訓練模型的技術手段。我們可以在人工智慧堆疊中引入FHE 技術,Privasea 就是例子,在AI 堆疊中直接內置了一個加密的部分,形成了一個經過修改的AI 堆疊。
外部支援:crypto 用於支援基於AI 的功能,而無需對AI 堆疊進行修改。Bittensor就是一個例子,它激勵用戶貢獻數據——這些數據可用於訓練AI 模型。在這種情況下,模型的訓練或使用方式沒有任何改變;AI 堆疊也沒有任何變化。不過,在Bittensor 網絡中,使用經濟激勵措施有助於AI 堆疊更好地實現其目的。
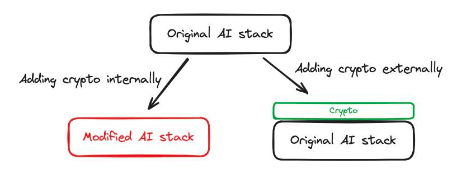
圖4 :前面討論的說明
同樣,AI 也能為Crypto 提供內部或外部協助:
內部支援:AI 技術用於crypto 堆疊內部。 AI 位於鏈上,直接與crypto 堆疊內的部分連接。舉例來說,鏈上的AI agents 管理著一個DAO。這種AI 不只是協助cypto 堆疊。它是技術堆疊中不可分割的一部分,深深嵌入技術堆疊中,使DAO 正常運作。
外部支援:AI 為crypto 堆疊提供外部支援。 AI 用於支援Crypto 堆疊,而不對其進行內部變更。 Dorsa 等平台使用AI 模型來確保智慧合約的安全。 AI 在鏈外,是一種外部工具,用於使編寫安全智能合約的過程更快以及更便宜。
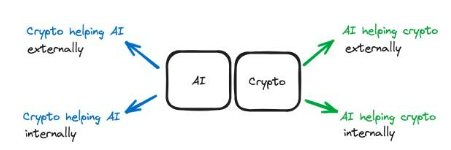
圖5 :這是升級的模型,包含了內部和外部支援的區別
對任何AI x Crypto 項目進行分析的第一階段就是確定它屬於哪個類別。
2.4 確定瓶頸
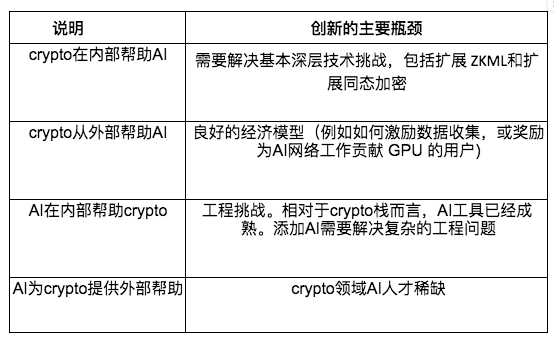
與外部支援相比,以深度技術整合為特點的內部支援往往有更多的技術難度。例如,如果我們想透過引入FHE 或零知識證明(ZKPs)來修改AI 棧,我們就需要在密碼學和AI 方面都有相當專業知識的技術人員。但很少人屬於這一交叉領域。這些公司包括Modulus、EZKL、Zama和Privasea。
因此,這些公司需要大量資金和稀有人才來推進其解決方案。讓使用者在智慧合約中整合人工智能同樣需要深入的知識;Ritual和Ora等公司必須解決複雜的工程問題。
反之,外部支援也有瓶頸,但它們通常涉及的技術複雜性較低。例如,為AI agents 新增加密貨幣支付功能並不需要我們對模型有太大修改。實現起來相對容易。雖然對於AI 工程師來說,建造一個ChatGPT 插件,讓ChatGPT 從DeFi LLama網頁上取得統計數據在技術上並不復雜,但很少有AI 工程師是crypto 社區的成員。雖然這項任務在技術上並不復雜,但能夠使用這些工具的AI 工程師卻寥寥無幾,而且很多人都不知道這些可能性。
2.5 測量效用
所有這四個類別中都會有好項目。
如果將人工智能整合到加密技術堆疊中,智慧合約開發者將能夠訪問鏈上的人工智能模型,從而增加可能性的數量,並有可能帶來廣泛的創新。這同樣適用於將加密整合到人工智慧堆疊的情況——深度技術融合將產生新的可能性。
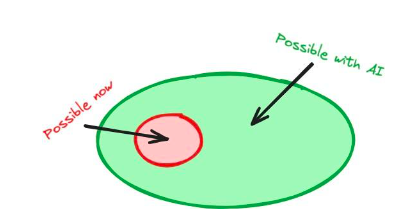
圖6 :在加密堆疊中加入人工智能,為開發者提供新功能
在人工智能為加密提供外部幫助的情況下,人工智能的整合很可能會改進現有產品,同時產生較少的突破,引入較少的可能性。例如,使用人工智慧模型編寫智慧合約可能會比以前更快、更便宜,也可能會提高安全性,但不太可能產生以前不可能產生的智慧合約。這同樣適用於加密技術從外部幫助人工智能——代幣激勵可以用於人工智能堆疊,但這本身不太可能重新定義我們訓練人工智能模型的方式。
總之,將一種技術整合到另一種技術堆疊中可能會產生新的功能,而使用技術堆疊以外的技術則可能會提高可用性和效率。
2.6 評估項目
我們可以根據特定項目所處的象限來估算其部分收益,因為技術之間的內部支援可以帶來更大的回報,但估算一個項目經風險調整後的總收益則需要我們考慮更多的因素和風險。
需要考慮的一個因素是,所考慮的項目在Web2、Web3或兩者的背景下是否都有用。具有FHE 功能的人工智能模型可用於取代不具有FHE 功能的人工智能模型——引入FHE 功能對兩個領域都有用,在任何情況下,隱私都是有價值的。不過,將人工智能模型整合到智慧合約中只能在Web3 環境中使用。
如前所述,人工智能和加密領域之間的技術整合是在項目內部還是外部進行的,也將決定項目上升潛力,涉及內部支援的項目往往會產生新的能力和更大的效率提升,而這是更有價值的。
我們還必須考慮這項技術成熟的時間跨度,這將決定人們需要等待多長時間才能獲得回報。
對項目的投資。要做到這一點,可以分析目前的進展情況,並找出與專案相關的瓶頸問題(請參閱第2.4 節)。
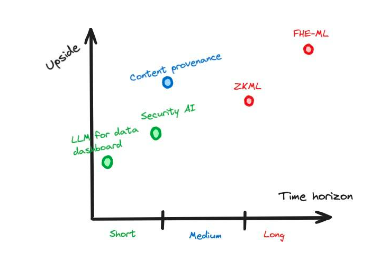
圖7 :一個假設的例子,說明與時間跨度相比的潛在上升空間
2.7 了解複雜產品
有些項目涉及我們所描述的四個類別的組合,而不僅僅是一個類別。在這種情況下,與專案相關的風險和效益往往會倍增,專案實施的時間跨度也會更長。
此外,您還必須考慮項目的整體性是否優於各部分的總和——一個項目如果什麼都有,往往不足以滿足最終用戶的需求。重點突出的方法往往會產生優秀的產品。

2.7.1 例一:Flock.io
Flock.io允許在多個服務器之間"分割"訓練模型,任何一方都無法存取所有訓練資料。由於可以直接參與模型的訓練,因此您可以使用自己的數據為模型做出貢獻,而不會洩露任何數據。這有利於保護用戶隱私。隨著人工智能堆疊(模型訓練)的改變,這涉及加密在內部幫助人工智能。
此外,他們還使用加密代幣獎勵參與模型訓練的人員,並使用智慧合約對破壞訓練過程的人員進行經濟處罰。這並不會改變訓練模型所涉及的流程,底層技術保持不變,但各方在都需要遵循鏈上罰沒機制。這是加密技術從外部幫助人工智能的一個例子。
最重要的是,加密技術在內部幫助人工智慧引入了一種新的能力:模型可以透過去中心化網路進行訓練,同時保持資料的隱私。然而,從外部幫助人工智能的加密貨幣並沒有引入新的能力,因為代幣只是用來激勵用戶為網絡做出貢獻。用戶可以用法幣獲得補償,而用加密貨幣激勵是一種更優解,可以提高系統的效率,但它並沒有引入新的能力。
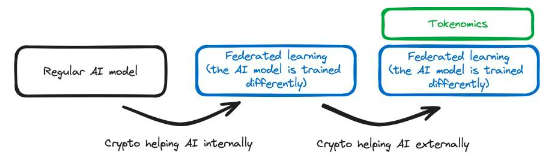
圖8 :Flock.io的示意圖以及堆疊的變化情況,其中顏色的變化意味著內部發生了變化
2.7.2 例二:洛克斐勒機器人
洛克菲勒機器人是一個在鏈條上運作的交易機器人。它使用人工智能來決定進行哪些交易,但由於人工智能模型本身並不在智能合約上運行,因此我們依賴服務提供者為我們運行模型,然後告訴智能合約人工智能的決定,並向智能合約證明他們沒有說謊。如果智慧合約不檢查服務提供者是否說謊,服務提供者就可能代表我們進行有害的交易。洛克斐勒機器人允許我們使用ZK 證明向智慧合約證明服務提供者沒有說謊。在這裡,ZK 被用來改變人工智能堆疊。人工智慧堆疊需要採用ZK 技術,否則我們就無法使用ZK 來證明模型對智慧合約的決定。
由於採用了ZK 技術,由此產生的人工智能模型輸出具有可驗證性,可以從區塊鏈上進行查詢,這意味著該人工智能模型在加密堆疊內部使用。在這種情況下,我們在智慧合約中使用了人工智慧模型,以公平的方式決定交易和價格。如果沒有人工智能,這是不可能實現的。
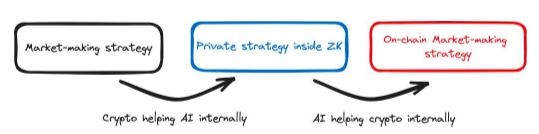
圖9 :洛克斐勒機器人與堆疊變化示意圖。顏色變化意味著堆疊(內部支援)發生了變化
3. 值得深究的問題
3.1 加密領域與深度偽造(Deepfake) 啟示錄

1 月23 日,一條人工智能產生的語音訊息謊稱自己是拜登總統,勸阻民主黨人不要在2024 年初選中投票。不到一周後,一名金融工作者因模仿同事的深度偽造視頻通話,損失了2500 萬美元。同時,在X(前身為Twitter)上,由人工智能偽造的泰勒絲(Taylor Swift)的露骨照片吸引了4500 萬次瀏覽,引發了廣泛的憤怒。這些事件都發生在2024 年的頭兩個月,它們只是深度偽造在政治、金融和社交媒體領域產生的各種破壞性影響的縮影。
3.1.1 它們是如何成為問題的?
偽造圖像並不是什麼新鮮事。 1917 年,The Strand 雜誌上刊登了一些被設計成仙女模樣的精巧剪紙照片;許多人認為這些照片是超自然力量存在的有力證據。

圖10 :《科廷利仙子》照片之一。福爾摩斯的創作者阿瑟-柯南-道爾爵士曾經將這些偽造圖片作為靈異現象的證據。
隨著時間的推移,造假變得越來越容易,成本也越來越低,這大大提高了錯誤訊息的傳播速度。例如,在2004 年美國總統大選期間,一張經過篡改的照片虛假地顯示民主黨提名人約翰·克里(John Kerry)與簡·方達(Jane Fonda)一起參加抗議活動,簡-方達是一位頗具爭議的美國活動家。科廷利仙子需要精心佈置,用硬紙板剪出兒童讀物中的描摹圖畫,而這次偽造則是用Photoshop 完成的簡單任務。

圖11 :這張照片顯示約翰·克里與簡·方達在反越戰集會上同台。後來發現這是一張偽造的照片,是用Photoshop 合成的兩張現有圖片。
不過,由於我們學會如何辨別編輯痕跡,假照片帶來的風險已經降低。在“遊客小哥」的案例中,業餘愛好者能夠透過觀察場景中不同物體的白平衡不一致來識別圖片是否經過剪輯。這是公眾對虛假資訊認識提升的產物;人們已經學會注意圖片編輯的痕跡。 「Photoshoped」一詞已成為通用術語:圖像被篡改的跡像已被普遍認可,照片證據不再被視為不可篡改的證據。
3.1.1.1 深度偽造讓造假更容易、更便宜、更逼真
過去,偽造證件很容易被肉眼識破,但深度偽造技術使製作幾乎與真實照片無異的圖像變得簡單而廉價。例如,OnlyFake 網站使用深度偽造技術在幾分鐘內產生逼真的假身份證照片,只需15 美元。這些照片被用來繞過OKX(一家加密貨幣交易所)的反詐騙保障措施,即所謂的「了解你的客戶"(KYC)。在OKX 的案例中,這些深度偽造的ID 騙過了他們的員工,而這些員工都受過識別篡改圖片和深度偽造的培訓。這凸顯出,即使是專業人士,也不再可能透過肉眼發現基於深度偽造的詐騙行為。
由於影像被深度偽造,人們加強了對視頻證據的依賴,但深度偽造不久將嚴重破壞視頻證據(的可信度)。德州大學達拉斯分校的一名研究人員利用免費的深度偽造換臉工具,成功繞過了KYC 提供者實施的身份驗證功能。這是一個巨大的進步——過去,要產生具有合格水平的影片既昂貴又耗時。
2019 年,有人需要花費兩週時間和552 美元,才能製作出一段38 秒的馬克·祖克柏深度偽造視頻,影片中還會出現明顯的視覺缺陷。如今,我們可以在幾分鐘內免費製作逼真的deepfake 影片。
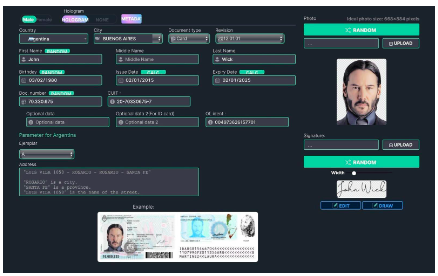
圖12 :OnlyFake 面板可在幾分鐘內製作假身分證
3.1.1.2 影片為何如此重要
在深度偽造技術出現之前,影片曾是可靠的證據。與容易偽造的圖像不同,影片在歷史上一直是難以偽造的,因此在法庭上被公認為是可靠的證據。這使得視頻深度偽造變得尤為危險。
同時,深度偽造的出現也可能導致對真實影片的否定,美國總統拜登的一段影片被錯誤地稱為深度偽造。批評者以拜登眼睛一眨不眨和光線差異為證據,這些說法已被推翻。這就導致了一個問題——「深度偽造」不僅讓假的看起來像真的,也讓真的看起來像假的,進一步模糊了真實與虛構之間的界限,增加了問責的難度。

深度偽造實現了大規模定向廣告。我們可能很快就會看到另一個YouTube,在這個版本中,所說的內容、所說的人以及所說的地點都是針對觀眾個性化定制的。一個早期的例子是Zomato 的在地化廣告,廣告中演員赫里希克·羅尚(Hrithik Roshan)在觀眾所在城市的熱門餐廳點菜。 Zomato 產生了不同的深度偽造廣告,根據觀眾不同的GPS 位置產生廣告內容,介紹觀眾所在地的餐廳。
3.1.2 目前的解決方案有何不足
3.1.2.1 意識
現在的深度偽造技術已經非常先進,足以騙過訓練有素的專家。這使得駭客能夠繞過身份驗證(KYC/AML)程序,甚至人工審核。這表明,我們無法用眼睛將深度偽造與真實圖像區分開來。我們不能僅僅透過對影像持懷疑態度來防範深度偽造:我們需要更多的工具來應對深度偽造的流行。
3.1.2.2 平台
如果沒有強大的社會壓力,社群媒體平台並不願意有效抑制深度偽造。例如,Meta 禁止含有虛假音頻的度偽造視視頻,但拒絕禁止純捏造的視頻內容。他們違背了自己的監督委員會的建議,並沒有刪除一段顯示拜登總統撫摸孫女的深度偽造視頻,即純屬捏造的內容。
3.1.2.3 政策
我們需要製定法律,有效應對新型深度偽造風險,同時又不限制問題較少的用途,如藝術或教育領域,因為這些用途並不試圖欺騙人們。泰勒絲(Taylor Swift)深度偽造圖片未經同意而被傳播等事件,促使立法者通過更嚴格的法律來打擊此類深度偽造行為。針對此類案件,可能有必要在法律上強化在線審核程序,但禁止所有人工智能生成內容的提議引起了電影製片人和數字藝術家的警覺,他們擔心這會不公正地限制他們的工作。找到正確的平衡點是關鍵,否則那些合法的創意應用將會被扼殺。
推動立法者提高訓練強大模型的進入門檻,大型科技公司可以確保其人工智能壟斷地位。這可能會導致權力不可逆轉地集中在少數公司手中——例如,涉及人工智能的第14110 號行政命令就建議對擁有大量運算能力的公司提出嚴格要求。

圖13 :美國副總統卡馬拉·哈里斯(Kamala Harris)在美國總統喬·拜登(Joe Biden)簽署美國首個人工智能行政命令時鼓掌
3.1.2.4 技術
直接在人工智慧模型中建立防護欄以防止濫用是第一道防線,但這些防護欄不斷被破壞。人工智能模型很難審查,因為我們不知如何使用現有低階工具來修改更高維度的行為。此外,訓練人工智慧模型的公司可以利用實施防護欄作為藉口,在其模型中引入不良審查和偏見。這是有問題的,因為大型科技人工智慧公司無需對公眾意願負責——公司可以自由地影響其模型,而損害用戶的利益。
即使強大人工智能的創造權並未集中在不誠實的公司手中,要建立一個既有防護措施又不偏不倚的人工智能可能仍然是不可能的。研究人員很難確定什麼是濫用,因此很難以中立、平衡的方式處理用戶請求的同時防止濫用。如果我們無法定義濫用,似乎就有必要降低防範措施的嚴格程度,可能導致濫用再次發生。因此,完全禁止濫用人工智慧模型是不可能的。
一種解決方案是在惡意深度偽造出現後立即進行檢測,而不是阻止其產生。但是,深度偽造檢測人工智能模型(如OpenAI 部署的模型由於不準確,正在變得過時。雖然深度贗品檢測方法已經變得越來越複雜,但製造深度贗品的技術卻在以更快的速度變得越來越複雜——深度偽造檢測器在技術軍備競賽中敗下陣來。這使得僅憑媒體很難辨識深度假新聞。人工智能已經足夠先進,可以製造出逼真到人工智能無法判斷其準確性的假鏡頭。
水印技術能夠在深層偽造品上隱密地打上標記,無論它們出現在哪裡,我們都能辨識出來。但是,深度偽造品並不總是帶有浮水印,因為水印必須是刻意添加的。自願將其偽造圖像標記而做出區分的公司(如OpenAI),水印是一個有效的方法。但無論如何,浮水印都可以用簡單易用的工具去除或偽造,從而繞過任何基於水印的防深度偽造解決方案。浮水印也可能意外刪除,大多數社群媒體平台都會自動刪除水印。
最流行的深度偽造水印技術是C 2 PA(由內容來源和真實性聯盟提出)。它旨在通過跟踪媒體來源並將此信息存儲在媒體元數據中來防止錯誤信息。該技術得到了Microsoft、Google 和AdAdobe 等公司的支持,因此C 2 PA 很有可能會在整個內容供應鏈中推廣,它比起其他同類技術更受歡迎。
遺憾的是,C 2 PA 也有自己的弱點。由於C 2 PA 會儲存影像的完整編輯歷史,並使用符合C 2 PA 標準的編輯軟件中所控制的加密密鑰,對每次編輯進行驗證,因此我們必須信任這些編輯軟件。但是,人們很可能會因為有效的C 2 PA 元資料而直接接受經過編輯的圖像,而不會考慮是否信任編輯鏈中的每一方。因此,如果任何編輯軟件遭到破壞或能夠進行惡意編輯,就有可能讓其他人相信偽造或惡意編輯的圖像是真實的。

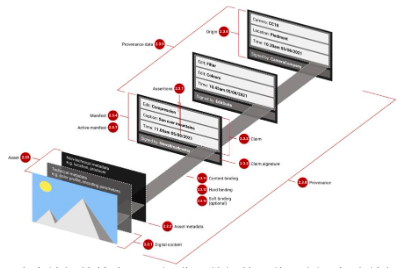
圖14 :包含一連串編輯的符合C 2 PA 標準元資料的影像範例。每個編輯都由不同的可信方簽名,但只有最終編輯的圖像是公開的。資料來源:真實照片與人工智慧生成的藝術:新標準(C 2 PA)利用PKI 顯示影像的歷史
此外,C 2 PA 浮水印中包含的加密簽名和元數據可以與特定使用者或裝置聯繫起來。在某些情況下,C 2 PA 元資料可以將您的相機拍攝的所有影像相互連接:如果我們知道某張影像來自某人的相機,我們就可以識別來自該相機的所有其他影像。這可幫助舉報人在發布照片時匿名化處理。
所有潛在的解決方案都將面臨一系列獨特的挑戰。儘管這些挑戰千差萬別——包括社會意識的限制、大型科技公司的缺陷、監管政策的實施難度以及我們的技術限制。

3.1.3 加密領域能解決這個問題嗎?
開源的深度偽造模式已經開始流傳。因此,有人可能會說,總有一些方法可以利用深度偽造來濫用他人的肖像;即使這種做法被定為犯罪,有人還是會選擇產生不道德的深度偽造內容。不過,我們可以讓惡意深度偽造內容退出主流來解決這個問題。我們可以防止人們認為深度偽造的圖片是真實的,並且能夠創建限制深度偽造內容的平台。本節將介紹各種基於加密技術的解決方案,以解決惡意深度偽造傳播帶來的誤導問題,同時強調每種方法的限制。
3.1.3.1 硬件認證
經過硬件認證的相機在拍攝每張照片時都會嵌入一個獨特的證明,證明照片是由該相機拍攝的。此證明由相機獨有的不可複製、防篡改晶片生成,確保影像的真實性。音頻和視頻也可以使用類似的程序。

認證證明告訴我們,影像是由真實相機拍攝的,這意味著我們通常可以相信這是真實物體的照片。我們可以標記沒有這種證明的圖像。但如果相機拍攝的是偽造場景,而偽造場景的設計看起來就像真實場景,那麼這種方法就失效了——你可以直接將相機對準一張偽造的圖片。目前,我們可以通過檢查捕捉到的影像是否失真來判斷照片是否從數字屏幕上拍攝的,但騙子們會找到隱藏這些瑕疵的方法(例如,通過使用更好的屏幕,或通過限製鏡頭眩光)。最終,即使是人工智慧工具也無法識別這種詐騙行為,因為騙子可以找到避免所有這些失真的方法。
硬件認證將減少信任偽造影像的情況,但在少數情況下,我們仍需要額外的工具來防止深度偽造影像在攝影機被入侵或濫用情況下傳播。正如我們之前所討論的,使用經過硬件驗證的攝像機仍有可能造成深度偽造內容是真實圖像的錯誤印象,原因例如攝像機被黑客攻擊,或相機被用來拍攝電腦屏幕上深度偽造的場景。要解決這個問題,還需要其他工具,例如攝影機黑名單。
相機黑名單將使社群媒體平台和應用程式能夠標記來自特定相機的影像,因為已知該相機過去曾產生過誤導性影像。黑名單可以無需公開披露可用於追溯相機的信息,如相機ID 等。
然而,目前還不清楚由誰來維護攝影機黑名單,也不清楚如何防止人們收受賄賂後把舉報人的相機也加入黑名單(的報復行為)。
3.1.3.2 基於區塊鏈的圖像年表
區塊鍊是不可篡改的,因此在互聯網上出現圖像時,將圖像與附加元數據一起添加到帶有時間戳的年表中,這樣時間戳和元數據就不會被篡改。由於未經編輯的原始圖片在惡意編輯擴散之前,就能被誠實的各方以不可更改的方式儲存在區塊鏈上,因此訪問這樣的記錄將使我們能夠識別惡意編輯並驗證原始來源。這項技術已在Polygon 區塊鍊網絡上實施,作為與福斯新聞合作開發的事實查核工具Verify的一部分。

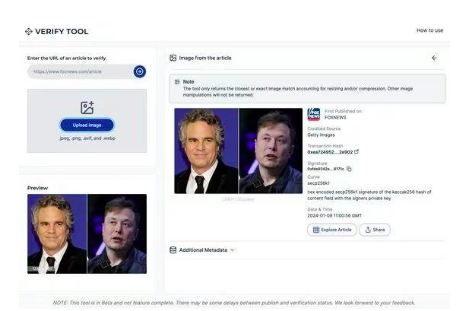
圖15 :Fox 基於區塊鏈的工具Verify 的使用者介面。可以透過URL 找到藝術品。從Polygon 區塊鏈獲取並顯示來源、交易雜湊值、簽名、時間戳記和其他元數據
3.1.3.3 數字身份
如果深度偽造會破壞我們對未經核實的圖片和影片的信任,那麼可信來源可能會成為避免虛假資訊的唯一途徑。我們已經依賴可信賴的媒體來源來核實信息,因為它們採用新聞標準、事實核查程序和編輯監督來確保信息的準確性和可信度。
然而,我們需要一種方法來驗證我們在網路上看到的內容是否來自我們信任的來源。這就是加密簽名資料的用處:它可以用數學方法證明某個內容的作者。
簽名是使用數字密鑰產生的,由於密鑰是由錢包創建和生成的,因此只有擁有相關加密錢包的人才知道。這樣,我們就能知道誰是資料的作者——只需檢查簽名是否與個人加密錢包中專屬於自己的密鑰相對應即可。
我們可以利用加密貨幣錢包,以無縫且用戶友好的方式將簽名附加到我們的貼文上。如果使用加密貨幣錢包登錄社群媒體平台,就可以利用錢包在社群媒體上創建和驗證簽名的功能。因此,如果某個貼文的來源不可信,平台將能夠向我們發出警告——它將使用自動簽名校驗來標記錯誤訊息。
此外,與錢包連接的zk-KYC基礎設施可以在不損害用戶隱私和匿名性的情況下,將未知錢包與透過KYC 流程驗證的身份綁定在一起。然而,隨著深度偽造變得越來越複雜,KYC 流程可能會被繞過,從而允許惡意行為者創建虛假的匿名身份。這個問題可以透過Worldcoin 的個人身分證明"(PoP)等解決方案來解決。
個人身分證明是WorldCoin 用來驗證其錢包是否屬於真人的機制,並且只允許一個一個錢包。為此,它使用生物識別(虹膜)成像設備Orb來驗證錢包。由於生物辨識資料尚無法偽造,因此要求社群媒體帳號與唯一的WorldCoin 錢包連結是一種可行的方法,可以防止不良行為者製作多個匿名身分來掩蓋其不道德的網路行為——至少在駭客在找到欺騙生物辨識設備的方法之前,它可以解決深度偽造KYC 問題。
3.1.3.4 經濟激勵措施

作者可因錯誤訊息而受到懲罰,使用者可因識別錯誤訊息而獲得獎勵。例如,"真實性債券"(Veracity Bonds)使媒體機構能夠以其出版物的準確性作為賭注,因錯誤信息而面臨經濟處罰。這就為這些媒體公司提供了一個經濟上的理由來保證資訊的真實性。
真實性債券將是"真相市場"不可分割的一部分,在這個市場上,不同的系統透過最高效、最穩健的方式驗證內容的真實性來爭奪用戶的信任。這類似於證明市場,如Succinct Network和=nil Proof Market,但針對的是較棘手的真實性驗證問題。
這僅靠密碼學是不夠的。智慧合約(Smart Contracts)可以作為一種手段,強制實施使這些「真相市場」發揮作用所需的經濟激勵措施,因此區塊鏈技術可能會在幫助打擊虛假資訊方面發揮核心作用。
3.1.3.5 聲譽評分

我們可以用聲譽來代表可信度。例如,我們可以看一個人在推特上有多少粉絲,來判斷是否該相信他所說的話。不過,聲譽系統應考慮每位作者的過往記錄,而不僅僅是他們的知名度。我們不希望將可信度與受歡迎程度混為一談。
我們不能允許人們無限量地產生匿名身份,否則,他們就可以在名譽受損時拋棄自己的身份,以重置他們的社會可信度。這就要求我們使用無法複製的數字身份,如上一節所述。
我們還可以利用"真相市場"和"硬件認證"中的證據來確定一個人的聲譽,因為這些都是追踪其真實記錄的可靠方法。聲譽系統是迄今為止所討論的所有其他解決方案的集大成者,因此也是最強大、最全面的方法系列。

圖16 :馬斯克在2018 年暗示創立網站,對期刊論文、編輯和出版品將進行可信度評分
3.1.4 加密解決方案是否可擴充?
上述區塊鏈解決方案需要快速且高儲存量的區塊鏈—否則,我們就無法將所有影像納入鏈上可驗證的時間記錄中。隨著每天發布的線上數據量呈指數級增長,這一點只會變得越來越重要。不過,有一些算法可以以仍可驗證的方式壓縮數據。
此外,透過硬件認證產生的簽名不適用於影像的編輯版本:必須使用zk-SNARKs 產生編輯證明。ZK Microphone是針對音頻的編輯證明實作。 4
3.1.5 深度偽造並非本質上就是壞事
必須承認,並非所有的深度偽造都是有害的。這項技術也有無辜的用途,例如這段人工智能生成的泰勒絲(Taylor Swift)教授數學的視頻。由於深度偽造的低成本和可訪問性,創造了個性化的體驗。例如,HeyGen允許用戶發送帶有人工智能生成的酷似自己的臉的個人訊息。深度仿真也透過配音翻譯縮小語言差距。

3.1.5.1 控制深度偽造並將其貨幣化的方法
基於深度偽造技術的人工智慧「模擬人」服務(AI counterpart services),他們收取高額費用,缺乏問責制和監督。 OnlyFans 上的頭號網紅Amouranth 發布了自己的數字人,粉絲們可以私下與她交談。這些新創公司可以限制甚至關閉存取權限,例如名為Soulmate 的人工智慧伴侶服務。
透過在鏈上託管人工智能模型,我們可以使用智慧合約以透明的方式為模型提供資金並對其進行控制。這將確保用戶永遠不會失去對模型的訪問權,並能幫助模型創建者在貢獻者和投資者之間分配利潤。不過,這也存在著技術挑戰。實現鏈上模型的最受歡迎技術zkML(Giza、Modulus Labs 和EZKL 使用)會使模型運行速度慢1000 倍。儘管如此,該子領域的研究仍在繼續,技術也在不斷改進。例如,HyperOracle正在嘗試使用opML,Aizel正在建立基於多方計算(MPC)和可信執行環境(TEE)的解決方案。
3.1.6 章節摘要
複雜的深度偽造正在侵蝕政治、金融和社群媒體領域的信任,凸顯了建立"可驗證網絡"以維護真相和民主誠信的必要性。
深度偽造曾經是一項昂貴且技術密集的工作,但隨著人工智能的進步,它已變得容易製作,從而改變了虛假信息的模式。
4 如果您對此問題感興趣,請聯繫阿爾比恩。
歷史告訴我們,操縱媒體並不是新的挑戰,但人工智慧使製造令人信服的假新聞變得更加容易和便宜,因此需要新的解決方案。
影片造假帶來了獨特的危險,因為它們損害了以往被認為可靠的證據,導致社會陷入一種困境,即真實行為可能被當作假的。
現有對策分為意識、平台、政策和技術方法,每種方法在有效打擊深度偽造方面都面臨挑戰。
硬件證明和區塊鏈證明了每張圖片的來源,並創建了透明、不可更改的編輯記錄,從而提供了前景廣闊的解決方案。
加密貨幣錢包和zk-KYC 加強了在線內容的驗證和認證,而鏈上信譽系統和經濟激勵措施(如"真實性債券")則為真相提供了一個市場。
在承認深度偽造的積極用途的同時,加密技術也提出了一種將有益的深度偽造列入白名單的方法,從而在創新與誠信之間取得平衡。
3.2 苦澀的一課

這句話有違常理,但卻是事實。人工智能界拒絕接受客製化方法效果不佳的說法,但"苦澀的教訓"仍然適用:使用最強的運算能力總是能產生最好的結果。
我們必須擴大規模:更多GPU、更多資料中心、更多訓練資料。
電腦國際象棋研究人員曾試圖利用人類頂尖棋手的經驗來建造國際象棋引擎,這就是研究人員弄錯了的一個例子。最初的西洋棋程式都是複製人類的開局策略(使用"開局書")。研究人員希望國際象棋引擎能從強勢局面開始,而無需從頭開始計算最佳棋步。它們還包含許多"戰術啟發法"——人類棋手使用的戰術,如叉子。簡單地說:國際象棋程式是根據人類對如何成功下棋的見解而不是一般的計算方法來建構的。
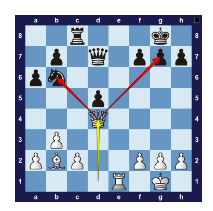
圖18 :叉子-皇后攻擊兩顆棋子

圖19 :國際象棋開局順序範例
1997 年,IBM 的DeepBlue 結合了巨大的運算能力和基於搜尋的技術,擊敗了國際象棋世界冠軍。儘管DeepBlue 優於所有"人類設計"的國際象棋引擎,但國際象棋研究人員對其避而遠之。他們認為,DeepBlue 的成功只是曇花一現,因為它並沒有採用國際象棋策略——在他們看來,這是一種粗暴的解決方案。他們錯了:從長遠來看,將大量計算應用於一般問題的解決方法往往會比自訂方法產生更好的結果。這種高計算意識形態
催生了成功的圍棋引擎(AlphaGo)、改良的語音辨識技術,以及更可靠的電腦視覺技術。
高運算人工智慧方法的最新成果是OpenAI 的ChatGPT。與先前的嘗試不同,OpenAI 並沒有試圖將人類對語言運作原理的理解編碼到軟件中。相反,他們的模型將來自互聯網的大量數據與海量計算結合起來。與其他研究人員不同的是,他們沒有乾預,也沒有在軟件中嵌入任何偏見。從長遠來看,表現最好的方法總是基於利用大量計算的通用方法。這是歷史事實;事實上,我們可能有足夠的證據證明這一點永遠正確。
從長遠來看,將龐大的運算能力與大量數據結合是最好的方法,原因在於摩爾定律:隨著時間的推移,計算成本將呈指數級下降。在短期內,我們可能無法確定計算帶寬的大幅增長,這可能導致研究人員試圖通過手動將人類知識和算法嵌入軟件來改進他們的技術。這種方法可能會在一段時間內奏效,但從長遠來看不會取得成功:將人類知識嵌入底層軟件會使軟件變得更加複雜,模型也無法根據額外的運算能力進行改進。這使得人工方法變得短視,因此薩頓建議我們忽略人工技術,並將重點放在將更多運算能力應用於通用計算技術上。
《苦澀的一課》對我們該如何建構去中心化的人工智能有著巨大的影響:
建構大型網路:上述經驗教訓凸顯了開發大型人工智慧模型並彙集大量運算資源對其進行訓練的迫切性。這些都是進入人工智慧新領域的關鍵步驟。Akash、GPUNet和IoNet等公司旨在提供可擴展的基礎設施。
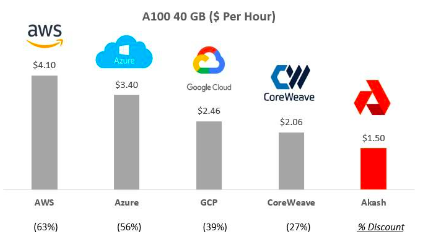
圖20 :Akash 價格與亞馬遜AWS 等其他供應商的比較
硬件創新:ZKML 方法一直受到批評,因為它們的運行速度比非ZKML 方法慢1000 倍。這與神經網路面臨的批評不謀而合。 1990 年代,神經網絡展現了巨大的前景。 Yann LeCun 的CNN 模型是一個小型神經網絡,能夠對手寫數字影像進行分類(見下圖),並取得了成功。到1998 年,美國有超過10% 的銀行使用這種技術來讀取支票。然而,這些CNN 模型無法擴展,因此人們對這些神經網絡的興趣急劇下降,電腦視覺研究人員又開始利用人類知識來創建更好的系統。 2012 年,研究人員利用GPU(一種通常用於生成電腦圖形(遊戲、CGI 等的流行硬件)的計算效率,開發出一種新的CNN。這讓他們達到了令人難以置信的性能,超過了當時所有其他可用的方法。這個網絡被稱為AlexNet,它引發了深度學習革命。

圖22 : 90 年代的神經網路只能處理低解析度的數字影像。

圖23 :AlexNet ( 2012) 能夠處理複雜的影像並超越了所有替代方法
人工智能技術的升級是必然的,因為運算成本總是越來越低。用於ZK 和FHE 等技術的定制硬件將加速進展——Ingonyama等公司和學術界正在鋪平道路。從長遠來看,我們將透過應用更強的運算能力和提高效率來實現大規模的ZKML。唯一的問題是,我們將如何利用這些技術?

圖24 :ZK 證明器硬件進步的一個例子(資料來源)
擴展數據:隨著人工智慧模型規模和複雜性的增長,有必要相應地擴展數據集。一般來說,資料集的規模應與模型規模成指數增長,以防止過度擬合並確保效能穩定。對於一個擁有數十億參數的模型來說,這往往意味著要策劃包含數十億token 或範例的資料集。例如,Google的BERT 模型是在包含超過25 億個單字的整個英文維基百科和包含約8 億個單字的BooksCorpus 上進行訓練的。而Meta 的LLama 則是在1.4 兆個詞庫的基礎上進行訓練的。這些數字強調了我們所需的數據集的規模——隨著模型向萬億個參數發展,數據集必須進一步擴大。這種擴展可以確保模型能夠捕捉到人類語言的細微差別和多樣性,因此開發龐大、高品質的資料集與模型本身的架構創新同樣重要。 Giza、Bittensor、Bagel 和FractionAI 等公司正在滿足這一領域的特殊需求(有關資料領域的挑戰,如模型崩潰、對抗性攻擊和品質保證方面的挑戰,詳見第5 章)。
發展通用方法:在去中心化人工智慧領域,ZKPs 和FHE 等技術採用針對具體應用的方法是為了追求立竿見影的效率。為特定架構量身定制解決方案可提高效能,但可能會犧牲長期靈活性和可擴展性,從而限制更廣泛的系統演進。相反,專注於通用方法提供了一個基礎,儘管最初會有效率低下的問題,但具有可擴展性,能夠適應各種應用和未來的發展。在摩爾定律等趨勢的推動下,隨著運算能力的成長和成本的降低,這些方法必將大放異彩。在短期效率和長期適應性之間做出選擇至關重要。強調通用方法可以為去中心化人工智能的未來做好準備,使其成為一個穩健、靈活的系統,充分利用運算技術的進步,確保持久的成功和相關性。
3.2.1 結論
在產品開發的早期階段,選擇不受規模限制的方法可能至關重要。這對公司和研究人員評估用例和想法都很重要。然而,慘痛的教訓告訴我們,從長遠來看,我們應該始終牢記優先選擇通用的可擴展方法。
這裡有一個手動方法被自動、通用微分所取代的例子:在使用TensorFlow 和PyTorch 等自動微分(autodiff)庫之前,梯度通常是通過手動或數值微分來計算的——這種方法效率低、容易出錯,而且會產生問題,浪費研究人員的時間,而自動微分則不同。現在Autodiff 已成為不可或缺的工具,因為autodiff 函式庫加快了實驗速度,簡化了模型開發。因此,通用解決方案獲勝了——但在autodiff 成為成熟可用的解決方案之前,舊的手動方法是進行ML 研究的必要條件。
總之,里奇·薩頓的"苦澀的一課"告訴我們,如果我們能最大限度地提高人工智能的運算能力,而不是試圖讓人工智能模仿人類所熟知的方法,那麼人工智能的進步將會更快。我們必須擴展現有運算能力、擴展數據、創新硬件並開發通用方法——採用這種方法將對去中心化人工智能領域產生許多影響。儘管"苦澀的一課"不適用於研究的最初階段,但從長遠來看,它可能永遠都是正確的。
3.3 AI Agents(人工智能代理)將顛覆Google和亞馬遜
3.3.1 谷歌的壟斷問題
線上內容創作者通常依賴Google來發布他們的內容。反過來,如果允許谷歌索引和展示他們的作品,他們就能獲得源源不斷的關注和廣告收入。然而,這種關係是不平衡的;Google擁有壟斷地位(超過80% 的搜尋引擎流量),其市場份額是內容創作者本身無法企及的。因此,內容創作者的收入嚴重依賴谷歌和其他科技巨頭。谷歌的一個決定就有可能導致個人業務的終結。
Google推出的精選片段(Featured Snippets)功能——顯示用戶查詢的答案,而無需點擊進入原始網站——突出了這一問題,因為現在無需離開搜尋引擎就能獲得信息。這打亂了內容創作者賴以生存的規則。作為被Google索引其內容的交換條件,內容創作者希望自己的網站能獲得推薦流量和眼球。取而代之的是,精選片段(Featured Snippets)功能可讓Google總結內容,同時將創作者排除在流量之外。內容生產者的分散性使他們基本上無力採取集體行動反對谷歌的決定;由於沒有統一的聲音,單一網站缺乏討價還價的能力。
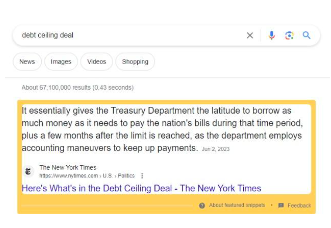
圖25 :精選片段(Featured Snippets)功能範例
谷歌透過提供用戶查詢答案的來源清單進行了進一步試驗。下面的範例包含《紐約時報》、維基百科、MLB.com 等網站的來源。由於Google直接提供了答案,這些網站不會獲得那麼多流量。
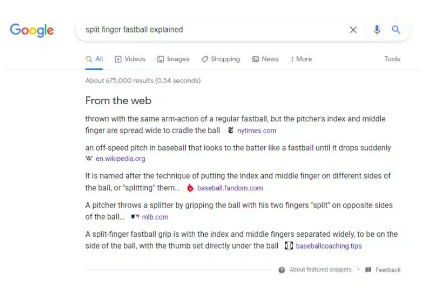
圖26 :"來自網路"功能範例
3.3.2 OpenAI 的壟斷問題
谷歌推出的「精選片段」功能代表了一種令人擔





