原文:A Singular Trajectory
原文:A Singular Trajectory
1999 年,Ray Kurzweil 曾做出以下預測:
2009 年,計算機將是平板電腦或更小尺寸的設備,高質量但傳統顯示屏;
2019 年,計算機將“基本上不可見”,大部分圖像直接投射到視網膜中;
2029 年,計算機將通過直接神經通路進行通信。
在觀察近20 年人工智能、機器人技術和製造的發展,尤其是近期的AIGC 的進展,有一些指標已表明,技術正在加速向奇點發展。
技術奇點

奇點(singularity)原意還有“奇異、突出、稀有”的意思,而這些意思逐漸被引申到自然科學中,先是應用於數學領域,後被引申至物理學界、天文學界等。不同版本的“技術奇點”預測便隨之而來。
技術奇點“ 1.0 版”:
1958 年,“技術奇點”這個概念第一次被波蘭數學家斯塔尼斯拉夫·烏拉姆(Stanisław Marcin Ulam)提出:“科技迭代的加速與人類生活方式的改變,似乎將把我們的歷史進程帶往一個重要的'奇點',在那之後,人類所熟知的事物將無法延續”,世界將會發生翻天覆地的變化。
技術奇點“ 2.0 版”:
1993 年,計算機科學家、科幻小說家文奇(Vernor Vinge)在《即將到來的技術奇點》(The Coming technology singularity)一文中寫道,“技術奇點”這一時間點的到來將標誌著人類時代的終結,而超級智能是“技術奇點”出現的前提,因為新的超級智能(super intelligence)將繼續自我升級,並以不可思議的速度取得技術進步。
技術奇點“ 3.0 版”:
2005 年,奇點大學創始人兼校長、谷歌技術總監雷·庫茲韋爾(Ray Kurzweil)在《奇點臨近》(The Singularity Is Near)一書中將“技術奇點”的概念再一次調整,也更接近於我們所熟知的概念,並在當時預測技術奇點將會在2045 年出現。他認為“技術奇點”是指技術變革迅速而深遠的發展將對未來人類生活造成的不可逆轉的變化,主要指代人工智能的快速發展。奇點將允許我們超越生物身體和大腦的限制,未來人類和機器之間將沒有區別。
技術奇點“ 4.0 版”:
2013 年,牛津大學人類未來研究所高級研究員桑德伯格(Anders Sandberg)將“技術奇點”的影響範圍擴大,他認為“超級智能”未必是必須的,任何新技術都有可能給人類社會帶來的根本變化,而這樣的技術發展和變化都可以稱之為“技術奇點”。
GPT 用戶,夢想有一個同伴嗎?

2022 年11 月30 日,OpenAI 發布了ChatGPT,一種會話界面和大型語言模型。對許多人來說,這是一個革命性的時刻。它的輸出讓人震驚,節省時間並且答案令人信服地真實(當OpenAI 認為可以安全回答時)。
非常了不起的是,你今天在幾秒鐘內可以通過LLM 得到一個不完美但有效的答案,而這個答案將花費領域專家幾分鐘的考慮和在線論壇幾個小時的辯論。
聊天機器人一直是人們渴望的陪伴對象。圖靈測試背後的動機可能是想要一個不會打破沉浸感的聊天機器人。
仍有待測試的是,作為社會動物的人類是否能通過數字大腦得到增強。我們一起打獵,一起耕種,現在社會可以被描述為工業規模機器的管理人員和操作員的巨大緩衝區,比以往任何時候都更加社會化。
人類會優化阻力最小的路徑,選擇複製或“谷歌”他們可能通過批判性思維和反复失敗獲得的不同知識。 ChatGPT 的出現:學生可能會使用LLM 為他們寫論文,取得好成績。 Stack Overflow 可能會為了個人利益而受到女巫攻擊,而觀眾(程序員)可能會以某種方式遵守deepfakes 的交響曲。腳本小子可能會提示ChatGPT 存在惡意軟件。 LLM 的主流使用是否會削弱我們的生產能力,尤其是在健全、有效和發散性思維方面?
奇點之前的最後傀儡師
人工智能可以產生的最深遠的影響在於人力資本分配的文化。最近的一個觀點很好地描述了人們對ChatGPT 的反應:
最高興的是那些發現機器顯然可以勝任書面委託而目瞪口呆的人。
到目前為止,一切都在預料之中。如果回看歷史會發現,人們通常高估了新的通信技術的短期影響,而嚴重低估了它們的長期影響。印刷、電影、廣播、電視和互聯網也是如此。
在試圖理解AI 的影響時,我們試圖分離出短期的破壞,以猜測中期和長期的後果。
話雖如此,也許通過市場動態來描述這種反彈是一個好方法。 AI 助手改變了內容創作的稀缺性,從而在某種程度上成為做市商。每當一個眾所周知的“精靈”離開“瓶子”時,消費者通過重新定價市場和逐步淘汰次優供應商而獲得不對稱的利益。反過來,基於AI 生產的供應商隨著時間的推移,積累了更多的資本。
有人可能會爭辯說,存在能夠負擔得起爬取整個互聯網以生成訓練數據集的公司的寡頭壟斷。可能只有有限數量的SaaS 能夠負擔得起消耗此類資源來生成新穎的ML 模型。如果基於ML 的商業變得足夠不穩定,那麼能夠實現和保持PMF 的人可能會更少。在過去,我們被像HAL 9000、Skynet 和Butlerian Jihad 這樣的心理戰術哄騙。
許多公司和智能代理在AI 經濟中就稀缺性進行合作。我們現在的資本主義社會產生一個沒有負面反饋的技術官僚的可能性有多大,它可以逐步淘汰社會經濟階層,基本原則,如人權/財產權,或加速某種形式的大規模毀滅的可能性?
圖片描述
圖片描述
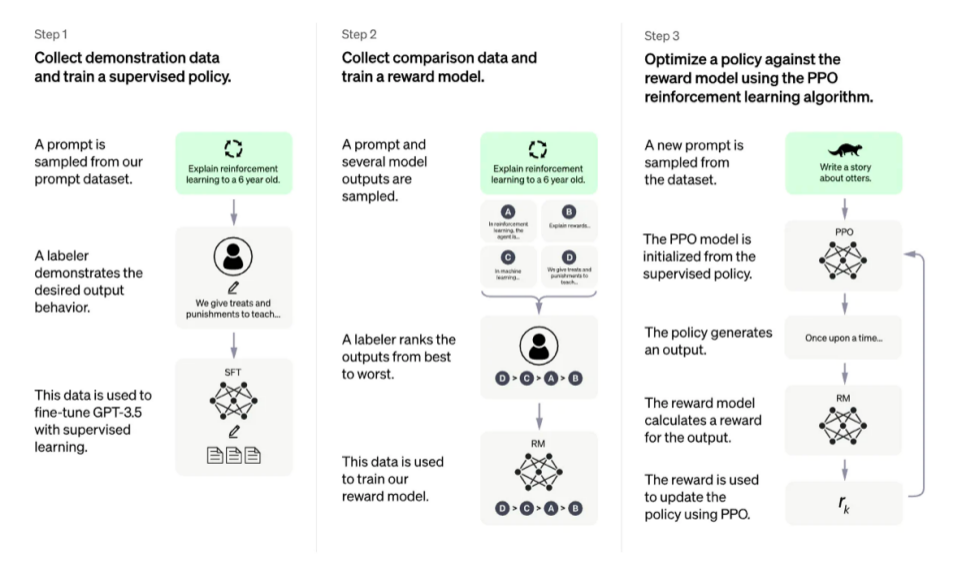
圖片描述
OpenAI 的RLHF 圖解
然而,要“完善” NLP 也存在挑戰。
雖然這些技術極具前景和影響力,並引起了人工智能領域最大研究實驗室的關注,但仍然存在明顯的局限性。這些模型可以毫無不確定性地輸出有害或實際上不准確的文本。這種不完美代表了RLHF 的長期挑戰和動力——在一個固有的人類問題領域中運行意味著永遠不會有一條明確的終點線可以跨越,使模型被標記為完整。
在使用RLHF 部署系統時,由於強制性和深思熟慮的人為因素,收集人類偏好數據非常昂貴。 RLHF 性能僅與其人工註釋的質量一樣好,人工註釋有兩種:人工生成的文本,例如微調InstructGPT 中的初始LM,以及模型輸出之間的人類偏好標籤。
生成寫得很好的人工文本來回答特定的提示是非常昂貴的,因為它通常需要雇用兼職人員(而不是能夠依賴產品用戶或眾包)。值得慶幸的是,用於訓練大多數RLHF 應用的獎勵模型的數據規模(~ 50 k 標記偏好樣本)並不那麼昂貴。然而,它仍然比學術實驗室可能負擔得起的成本更高。
目前,只有一個基於通用語言模型的RLHF 大規模數據集(來自Anthropic)和幾個較小規模的任務特定數據集(例如來自OpenAI 的摘要數據)。 RLHF 數據挑戰是標註者的偏見。幾個人類標註者可能有不同意見,導致了訓練數據存在一些潛在差異。
RLHF 可以應用於自然語言處理(NLP) 之外的機器學習。例如,Deepmind 探索了將其用於多模態代理。同樣的挑戰適用於這種情況:
可擴展強化學習(RL) 依賴於查詢成本低廉的精確獎勵函數。當RL 可以應用時,它已經取得了巨大的成就,創造了可以匹配人類才能分佈極值的AI(Silver 等人, 2016 年;Vinyals 等人, 2019 年)。然而,對於人們經常參與的許多開放式行為,這種獎勵功能並不為人所知。例如,考慮一種日常互動,要求某人“將杯子放在你附近”。對於能夠充分評估這種交互的獎勵模型,它需要對以自然語言提出請求的多種方式以及滿足(或不滿足)請求的多種方式具有魯棒性,同時對不相關的變化因素(杯子的顏色)和語言固有的歧義(什麼是“接近”?)不敏感。
因此,為了通過RL 灌輸更廣泛的專家級能力,我們需要一種方法來生成精確的、可查詢的獎勵函數,以尊重人類行為的複雜性、可變性和模糊性。除了對獎勵函數進行編程之外,一種選擇是使用機器學習來構建它們。我們可以要求人類評估情況並提供監督信息以學習獎勵函數,而不是嘗試預測和正式定義獎勵事件。對於人類可以自然、直觀、快速地提供此類判斷的情況,使用此類學習獎勵模型的RL 可以有效地改進智能體(Christiano 等人, 2017 年;Ibarz 等人, 2018 年;Stiennon 等人, 2020年;)
導致奇點的許多因素有待進一步發展,我們可以比實施它們所花費的時間框架更有把握地確定它們是什麼。 Chris Lattner 從他的POV 中提到了“稀疏門控的專家組合”:
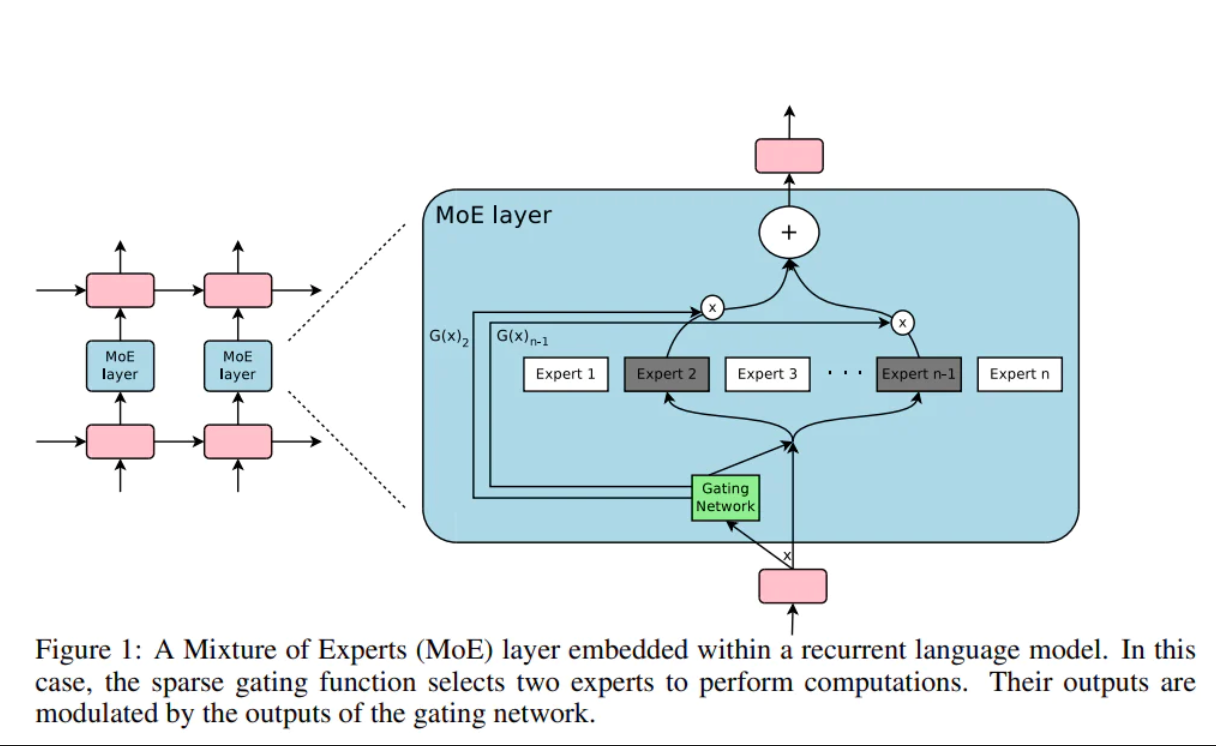
簡單地描述一下,也許有一個中介可以策劃和組合許多“專家”的輸入。
正文
圖片描述
正文
正文
正文
製造業的反饋很好,但衛生部門的需求最大。現在,我們是零售生物傳感器的早期採用者。隨著時間的推移,同態密碼學將使機器學習能夠利用大量健康數據。數萬年來,我們已經將藥物消費眾包,但我們如何與人工智能共存仍有待觀察,人工智能可以在任意時間跨度內管理任意物質的劑量。與此同時,同態加密因效率問題仍然沒有被使用。
Google Brain 剛剛發布了Robotics Transformer-1 。在第一個版本中它可能只是一個執行簡單任務的手臂,但顯然有可能在常見的構建環境中使用更多的標記化操作進行迭代。由於全球經濟以貨運為中心,與目前全球約6000 艘集裝箱船相比,如果最終在這樣的設施中建造100 多艘“零排放”集裝箱船,也屬於正常。這也將是住房危機中一個巨大的潮流變化,分區條例允許它完全生效。
另外,不得不提阿爾伯塔計劃, 12 個合理的AGI 能力發展步驟。
“路線圖”一詞暗示繪製一條線性路徑,即應按順序採取和通過的一系列步驟。這並非完全錯誤,但它沒有認識到研究的不確定性和機遇。我們在下面概述的步驟具有多重相互依賴性,而不是從頭到尾的步驟。路線圖建議一種自然的順序,但在實踐中通常會偏離這種順序。可以通過進入或附加到任何步驟來進行有用的研究。舉個例子,我們中的許多人最近在集成架構方面取得了有趣的進展,儘管這些進展只出現在排序的最後一步。
首先,讓我們嘗試全面了解路線圖及其基本原理。共有十二個步驟,標題如下:
圖片描述
圖片描述

圖片描述
ChatGPT 的輸出
“指數級進步”
上述阿爾伯塔計劃是一種理想情況。人類已經很複雜,作為個體使用稀疏神經網絡工具;作為團體,具有自組織的、社會學習和環境工程特性。在密碼學和分佈式(對抗性)計算的最新發展中,人類的自治程度僅可以維持圖靈完備的全局狀態(歷史) 。還有一種被稱為機械土耳其人的現象。關鍵是, AI 產品在任意時間跨度內的下降,都會有一個成熟的開發人員生態系統,可以通過協調執行超越現有的水平,並通過同期的AI 工具和可驗證的工作得到增強。
這促成了當前的思想實驗:我們甚至需要在The Singularity™ 之前實現每個預測的拐點嗎?對於商業化模型訓練中的每一項專有改進,都可能有一種可行的方法在公共領域實現。 StableDiffusion 已經引發了圍繞這一概念的對話。眾包在過去十年中已經充分加速(正如Twitch Plays Pokemon、社交網絡和DAO 所證明的那樣),奇點已經是一個轉移注意力的問題。正如以太坊擴展解決方案嘗試使用像zk-SNARKs 這樣的密碼學為了減少網絡的基礎設施需求,我們將嘗試實施輕量級解決方案,以減少現有大型企業對AI 進行暴力破解和貨幣化的需求。
事實上,反駁OpenAI 模型最好方法之一是,金融市場和社交網絡上類似的社會資本系統在某種程度上是可預測的行為。 Twitter 匯總新聞是因為它的用戶可以在全球範圍內通過合法人物進行廣播和放大。隨著COVID 封鎖和央行貨幣政策等全球趨勢,成長型股票可能會大幅上漲和下跌。不需要太多想像力就能在很短的時間內想像出一家初創公司,它可以將類似人工智能的PMF 表現為一個自我調節、自我編排的社區。可能有數千億美元的運營成本可以通過現有技術和進一步的業務發展在許多部門中釋放出來。





