原文翻譯:Tia
原文翻譯:Tia
圖片描述
原文翻譯:Tia
圖片描述
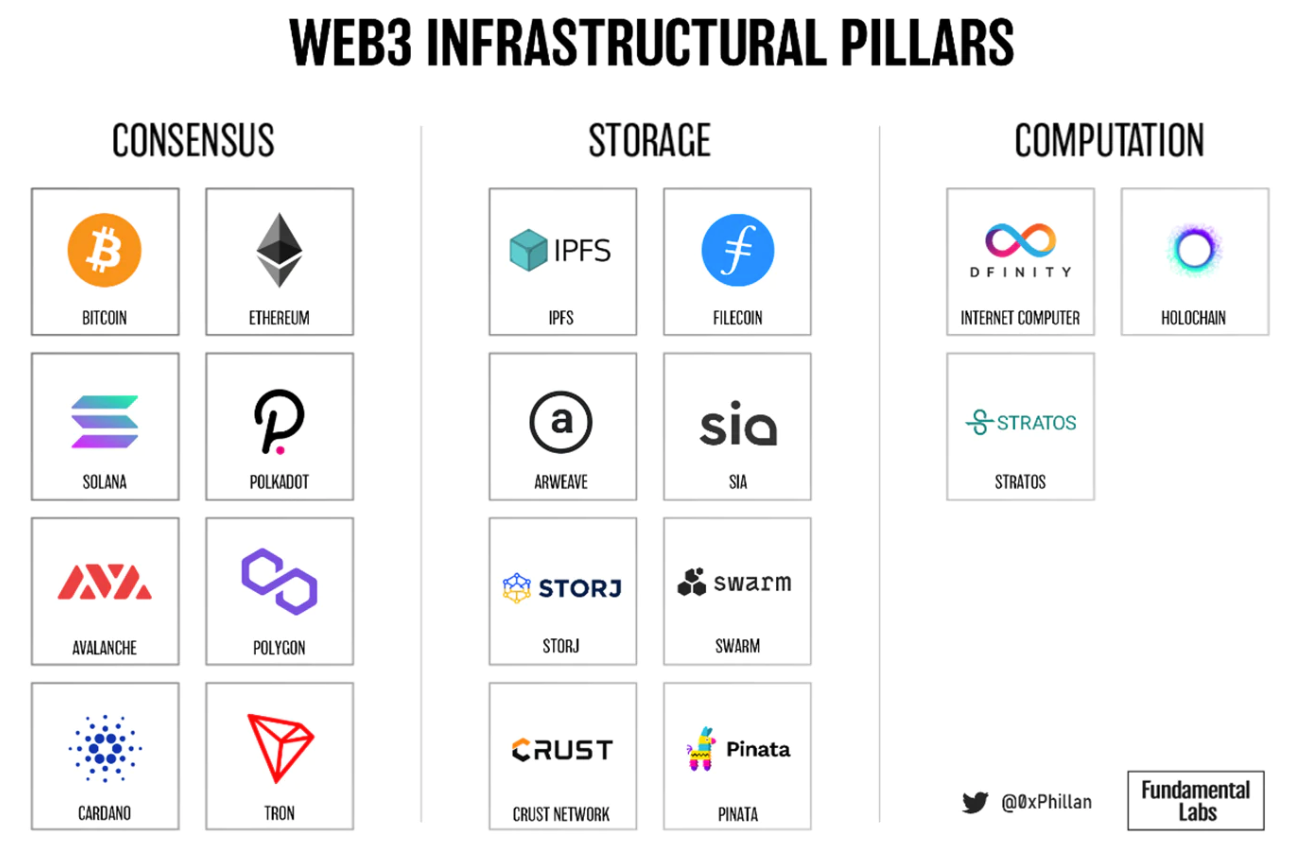
和Arweave和Crust Network圖1:每個Web3 支柱的項目示例
存儲,作為第二大支柱,正迅速成熟,各種存儲解決方案已經應用到使用場景中。本文,將進一步探討去中心化存儲這一支柱。
和
去中心化存儲的需求
圖片描述
區塊鏈的視角
從區塊鏈的視角來看,我們需要去中心化存儲是因為區塊鏈本身並不是被設計用來存儲大體量數據的。獲得區塊共識的機制依賴小數量的數據(交易),這些數據被放置於在區塊中(收集交易),並迅速分享至網絡供節點驗證。
圖片描述
圖片描述
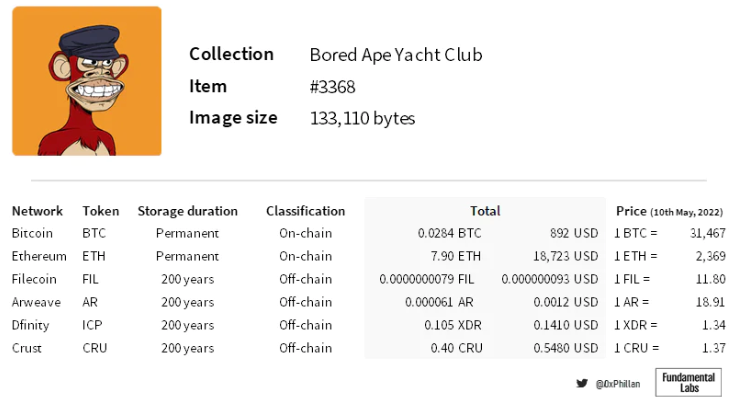
圖2:具有活躍主網的項目。選擇200 年的存儲期限來符合Arweave 對永久性的定義。來源:網絡文檔、Arweave 存儲計算器
中心化網絡的視角
NFTs
圖片描述
圖片描述
圖片描述
圖片描述
圖3:基於上次銷售的Crypto Punk 底價(撰寫本文時無底價); Crypto Punk 圖像大小基於Crypto Punks V2 鏈上字節字符串的字節長度。數據截至2022 年5 月10 日。來源:OpenSea、鏈上數據、IPFS 元數據
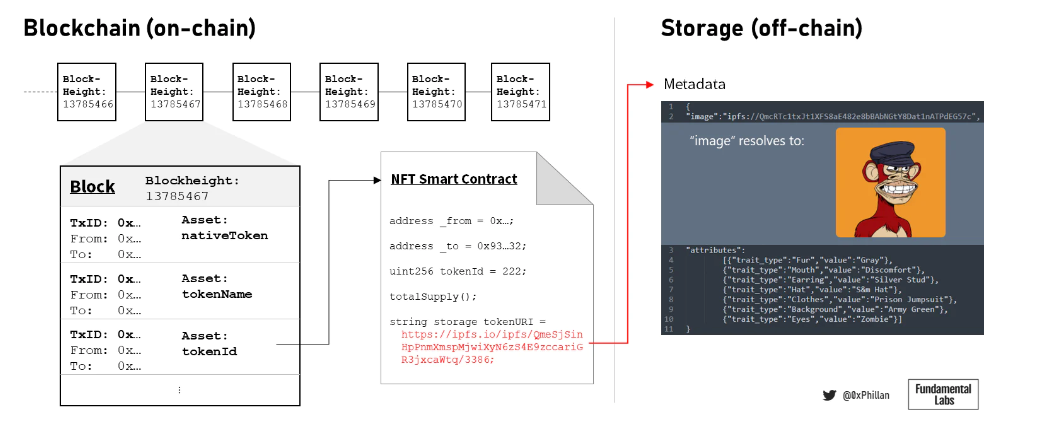
圖4:區塊鏈、區塊、NFT 和鏈下元數據的簡化圖示
dApps
圖片描述
圖片描述
圖片描述
圖片描述
圖片描述
圖片描述
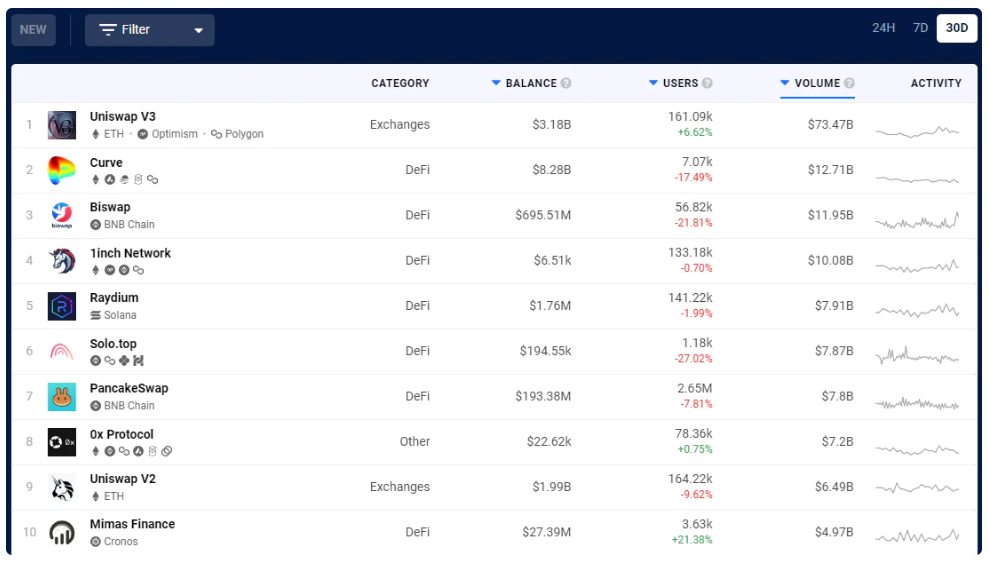
圖6:截至2022 年5 月11 日,DappRadar 報告的按美元數量計算的最受歡迎的dApp
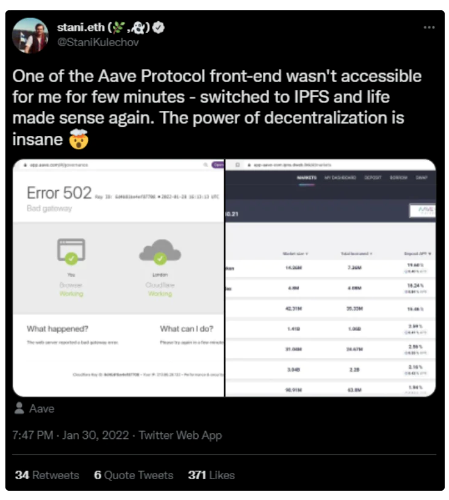
圖7:Aave 創始人Stani Kulechov 在推特上表示,Aave dApp 前端於2022 年1 月20 日下線,但仍可通過IPFS 託管的網站副本訪問
圖片描述
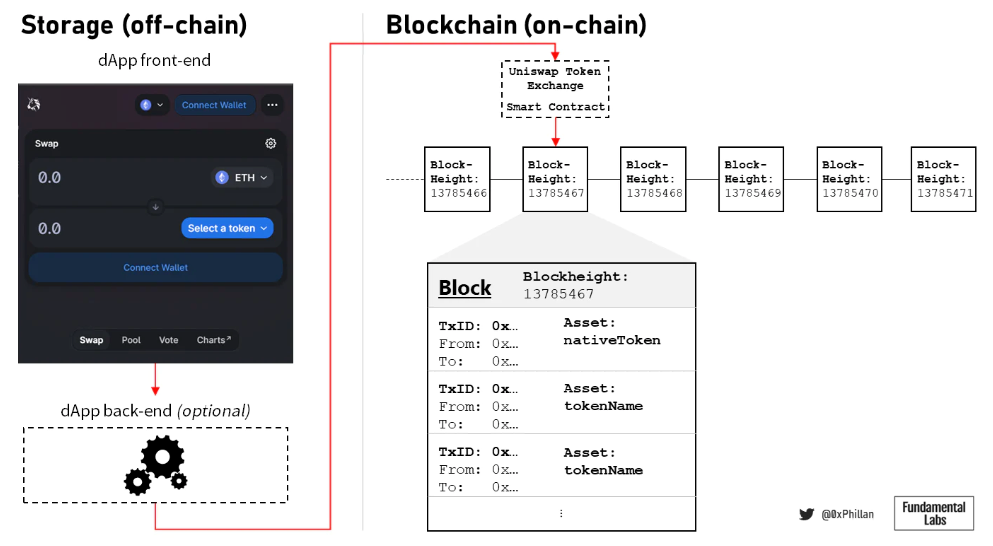
去中心化存儲減少了服務器故障、DNS 黑客、以及中心化實體刪除對dApp 前端的訪問。即使停止dApp 的開發,也可以通過前端繼續訪問智能合約。
去中心化存儲圖景
圖片描述
圖片描述
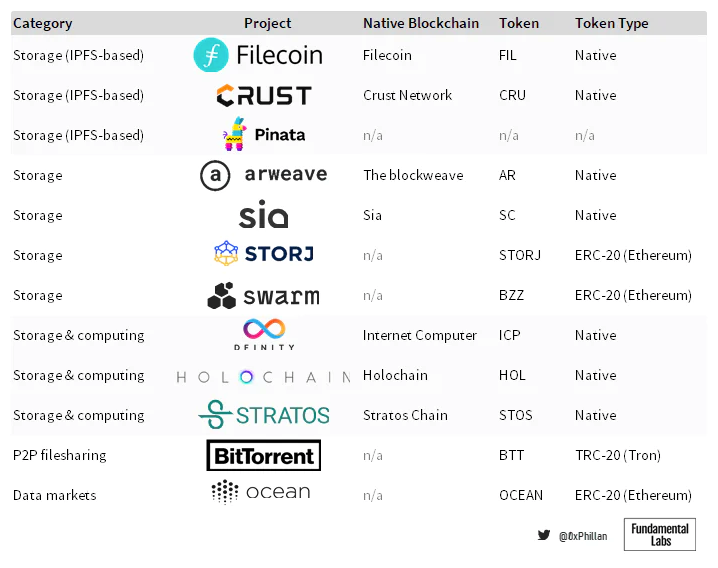
圖8:一些任意選擇的去中心化存儲協議概述(非詳盡)
儘管存在許多差異,但上述所有項目都有一個共同點:這些網絡都沒有在所有節點上複製所有數據,比特幣和以太坊區塊鏈就是這種情況。在去中心化存儲網絡中,存儲數據的不變性和可用性不是藉由大多數網絡存儲並驗證相繼鏈接的數據實現的,比特幣和以太坊就是這種情況。儘管如前所述,許多網絡選擇使用區塊鏈來跟踪存儲訂單。
去中心化存儲網絡上的所有節點都存儲所有數據是不可持續的,因為運行網絡的間接成本會使用戶的存儲成本迅速提高,並最終推動網絡的中心化,轉向少數能夠負擔得起硬件費用的節點運營商。
因此,去中心化存儲網絡需要克服非同尋常的挑戰。
去中心化存儲的挑戰
回顧前面提到的關於鏈上數據存儲的限制,很明顯去中心化存儲網絡必須以不影響網絡價值轉移機制的方式存儲數據,同時確保數據保持持久性、不可變性和可訪問性。從本質上講,去中心化存儲網絡必須能夠存儲數據、檢索數據和維護數據,同時確保網絡中的所有參與者都受到他們所做的存儲和檢索工作的激勵,同時還要維護去中心化系統的去信任性。
這些挑戰可被總結為如下問題:
數據存儲格式:存儲完整文件還是文件碎片?
數據複製:跨多少個節點存儲數據(完整文件或片段)?
存儲跟踪:網絡如何知道從哪裡檢索文件?
存儲數據的證明:節點是否存儲了他們被要求存儲的數據?
持久數據冗餘:如果節點離開網絡,網絡如何確保數據仍然可用?
圖片描述
圖片描述
圖片描述
或
閱讀完整研究文章。
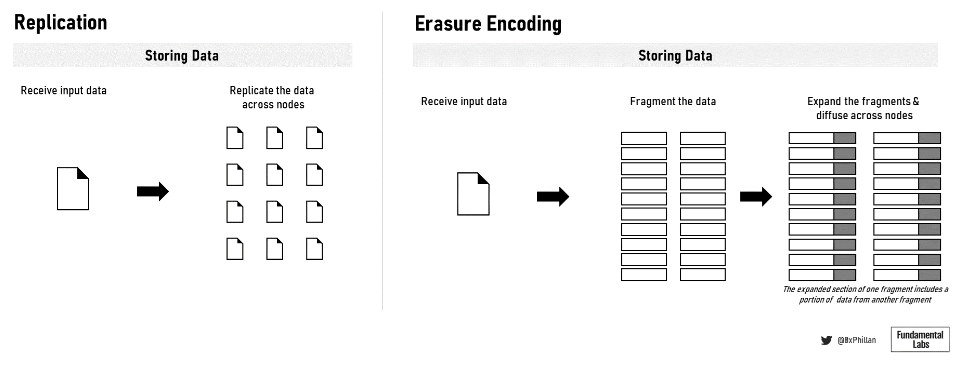
圖10:數據複製和擦除編碼
圖片描述
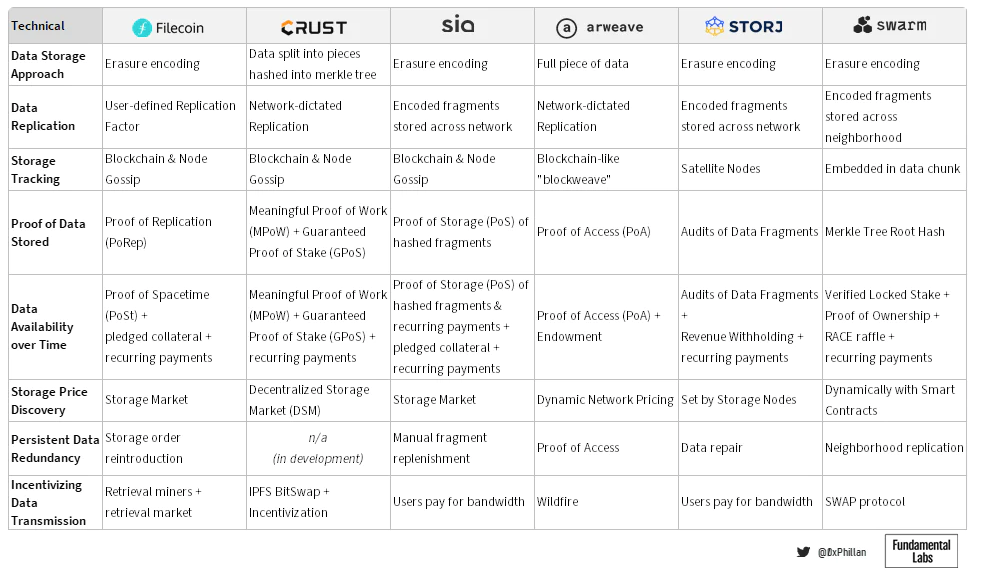
在這些網絡中,有兩種主要的方法用於在網絡上進行存儲數據:存儲完整文件和使用糾刪碼:Arweave 和Crust Network 存儲完整文件,而Filecoin、Sia、Storj 和Swarm 都使用糾刪碼。在擦除編碼中,數據被分解成固定大小的片段,每個片段都被擴展並用冗餘數據編碼。保存到每個片段中的冗餘數據使得只需要片段的一個子集來重建原始文件。
數據複製
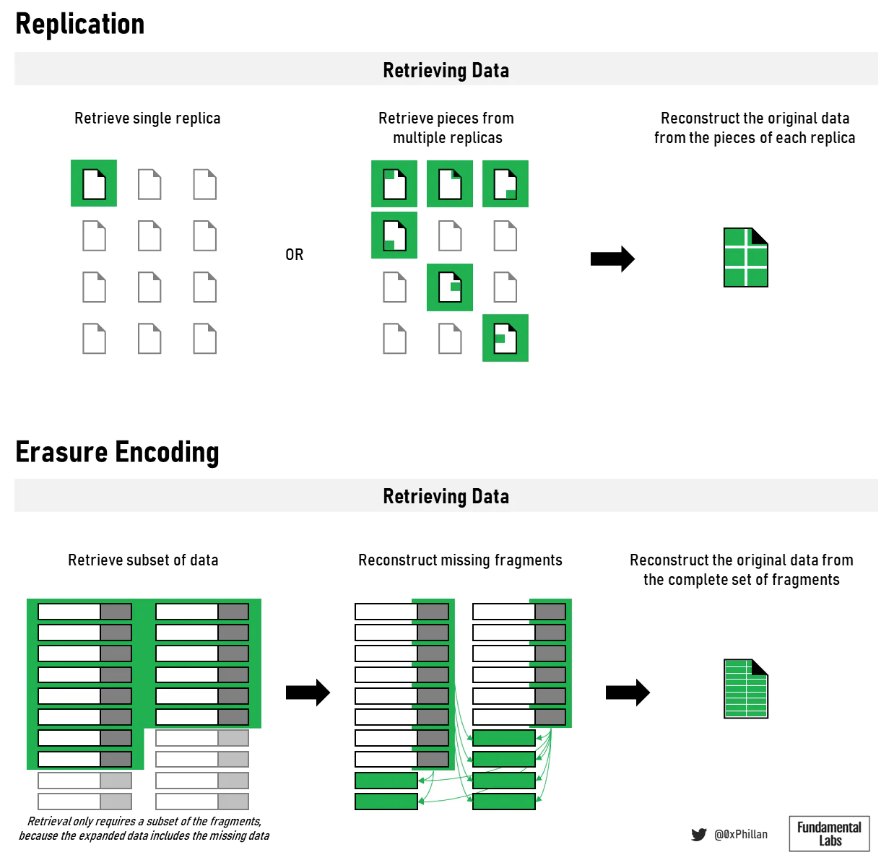
圖11:數據存儲格式將影響檢索和重建
圖片描述
用於存儲和復制數據的方法將影響網絡檢索數據的方式。
存儲跟踪
圖片描述
圖片描述
圖12:blockweave 中三個節點的圖示
最後,Storj 和Swarm 使用了兩種完全不同的方法。在Storj 中,稱為衛星節點的第二種節點類型充當一組存儲節點的協調器,用於管理和跟踪數據的存儲位置。在Swarm 中,數據的地址直接嵌入到數據塊中。檢索數據時,網絡根據數據本身知道在哪裡查找。
存儲數據證明
在證明數據的存儲方式時,每個網絡都採用自己獨特的方法。 Filecoin 使用複制證明—— 一種專有的存儲證明機制,它首先將數據存儲在存儲節點上,然後將數據密封在一個扇區中。密封過程使得相同數據的兩個複製片段可以證明彼此是唯一的,從而確保正確數量的副本存儲在網絡上(所以為「複製證明」)。
Crust 將一段數據分解成許多小塊,這些小塊被散列到Merkle 樹中。通過將存儲在物理存儲設備上的單個數據的散列結果與預期的Merkle 樹散列值進行比較,Crust 可以驗證文件是否已正確存儲。這類似於Sia 的方法,不同之處在於Crust 將整個文件存儲在每個節點上,而Sia 存儲擦除編碼的片段。 Crust 可以將整個文件存儲在單個節點上,並且仍然可以通過使用節點可信執行環境(TEE) 來實現隱私,這是一個即使硬件所有者也無法訪問的密封硬件組件。 Crust 將這種存儲證明算法稱為「有意義的工作證明」,而有意義表示僅在對存儲的數據進行更改時才計算新的哈希值,從而減少了無意義的操作。 Crust 和Sia 都將Merkle 樹根哈希存儲在區塊鏈上,作為驗證數據完整性的真實來源。
Storj 通過數據審計檢查數據是否已正確存儲。數據審計類似於Crust 和Sia 如何使用Merkle 樹來驗證數據片段。在Storj 上,一旦有足夠節點返回他們的審計結果,網絡就可以根據多數響應確定哪些節點有故障,而不是與區塊鏈的事實來源進行比較。 Storj 中的這種機制很有意,因為開發人員認為,通過區塊鏈減少網絡範圍內的協調可以在速度(無需等待共識)和帶寬使用(無需整個網絡定期與區塊鏈)方面提升性能。
Arweave 使用加密工作證明難題來確定文件是否已存儲。在這種機制中,為了讓節點能夠挖掘下一個區塊,他們需要證明他們可以訪問前一個區塊和網絡區塊歷史中的另一個隨機區塊。因為在Arweave 中上傳的數據直接存儲在塊中,通過證明對前一個塊的訪問證明存儲提供者確實正確保存了文件。
最後,在Swarm 上也使用Merkle 樹,不同之處在於Merkle 樹不用於確定文件位置,而是將數據塊直接存儲在Merkle 樹中。在swarm 上存儲數據時,樹的根哈希(也是存儲數據的地址)證明文件已正確分塊和存儲。
隨時間推移的數據可用性
同樣,在確定數據存儲在特定時間段內時,每個網絡都有獨特的方法。在Filecoin 中,為了減少網絡帶寬,存儲礦工需要在要存儲數據的時間段內連續運行複制證明算法。每個時間段的結果哈希證明在特定時間段內存儲空間已被正確的數據佔用,因此是「時空證明」。
Crust、Sia 和Storj 定期對隨機數據片段進行驗證,並將結果報告給他們的協調機制——Crust 和Sia 的區塊鏈,以及Storj 的衛星節點。 Arweave 通過其訪問證明機制確保數據的一致可用性,這要求礦工不僅要證明他們可以訪問最後一個塊,還要證明他們可以訪問一個隨機的歷史塊。存儲較舊和稀有的區塊是一種激勵措施,因為這增加了礦工贏得工作量證明難題的可能性,該難題是訪問特定區塊的先決條件。
另一方面,Swarm 定期運行抽獎活動,獎勵節點隨著時間的推移持有不那麼受歡迎的數據,同時還為節點承諾要在更長時間內存儲的數據運行所有權證明算法。
Filecoin、Sia 和Crust 需要節點存入抵押品才能成為存儲節點,而Swarm 只需要它用於長期存儲請求。 Storj 不需要前期抵押品,但Storj 將代扣礦工的部分存儲收入。最後,所有網絡在節點可證明存儲數據的時間段內定期向節點付款。
存儲價格發現
為了確定存儲價格,Filecoin 和Sia 使用存儲市場,存儲供應商設置他們的要價,存儲用戶設置他們願意支付的價格,以及其他一些設置。然後,存儲市場將用戶與滿足其要求的存儲提供商聯繫起來。 Storj 採用了類似的方法,主要區別在於沒有一個單一的網絡範圍的市場可以連接網絡上的所有節點。相反,每顆衛星都有自己的一組與之交互的存儲節點。
隨著時間的推移,節點將離開這些開放的公共網絡,當節點消失時,它們存儲的數據也會消失。因此,網絡必須積極地在系統中保持一定程度的冗餘。 Sia 和Storj 通過收集片段子集、重建基礎數據然後重新編碼文件來重新創建丟失的片段,通過補充丟失的擦除編碼片段來實現冗餘。在Sia 中,用戶必須定期登錄Sia 客戶端才能補充碎片,因為只有客戶端才能區分哪些數據碎片屬於哪條數據和用戶。而在Storj 上,Satellite 會始終在線並定期運行數據審計以補充數據片段。
圖片描述
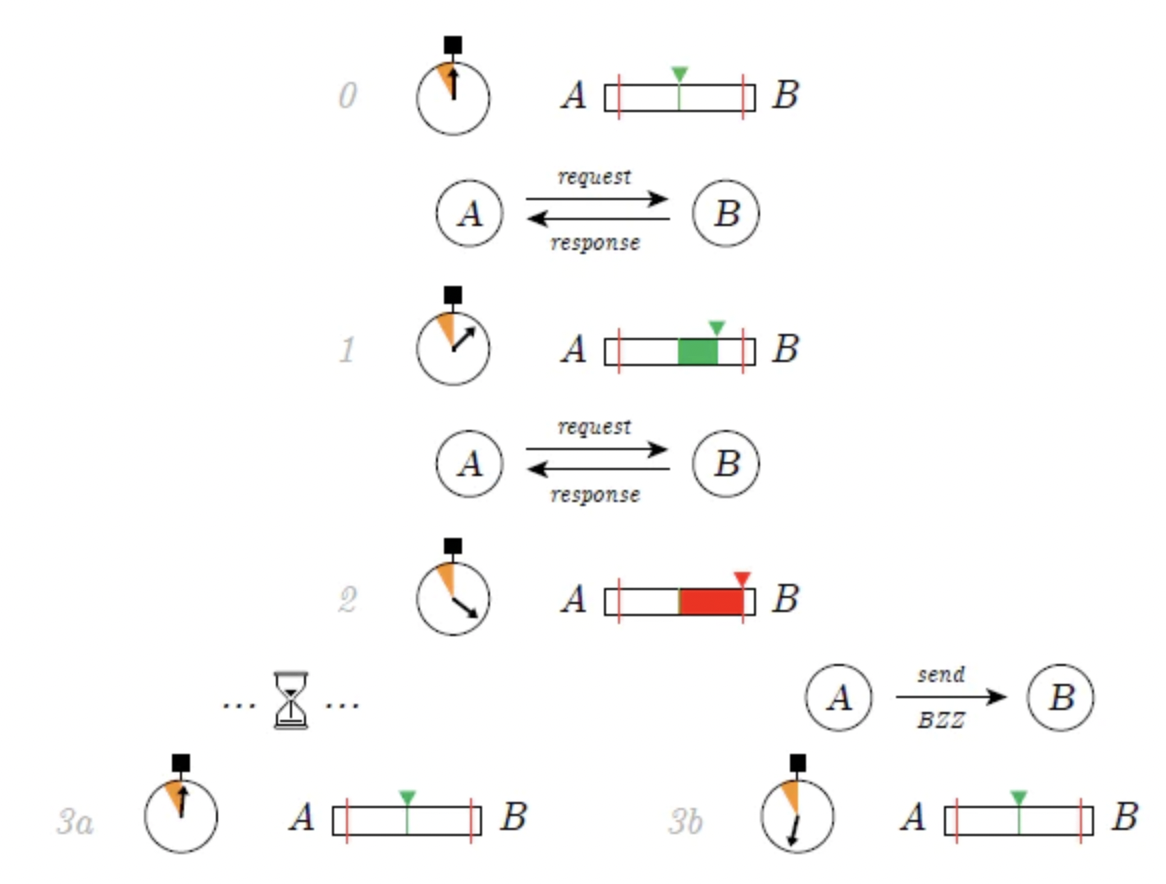
圖13:群記帳協議(SWAP),資料來源:Swarm 白皮書
代幣經濟
代幣經濟
圖片描述
代幣經濟
代幣經濟
圖片描述
圖片描述
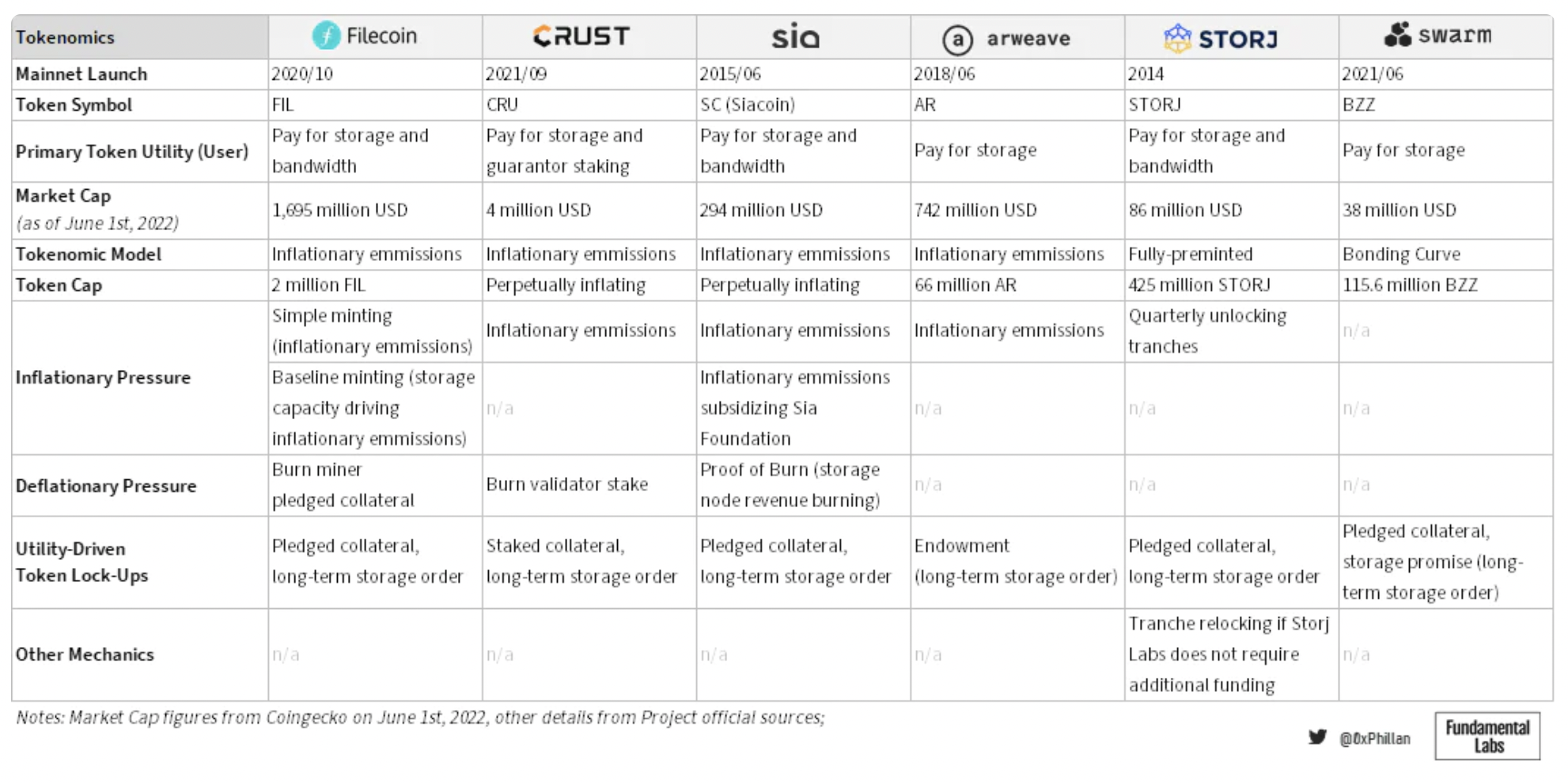
圖14:已審計的存儲網絡的代幣經濟設計決策。
哪一個是最佳網絡?
不能說一個網絡在客觀上比另一個網絡更好。在設計去中心化存儲網絡時,存在無數的權衡。雖然Arweave 非常適合永久存儲數據,但Arweave 不一定適合將Web2.0 行業參與者遷移到Web3.0 - 並非所有數據都需要永久保存。但是,一個強大的數據子領域的確需要永久性:NFT 和dApp。
最終,設計決策會基於該網絡的目的。
以下是各種存儲網絡的總結概況,它們在下面定義的一組尺度上相互比較。使用的尺度反映了這些網絡的比較維度,但是應該注意的是,克服去中心化存儲挑戰的方法在許多情況下並沒有好壞之分,而只是反映了設計決策。
存儲參數靈活性:用戶控製文件存儲參數的程度
存儲持久性:文件存儲在多大程度上可以通過網絡實現理論上的持久性(即無需幹預)
存儲跟踪的普遍性:節點之間對數據存儲位置的共識程度
圖片描述

有保證的數據可訪問性:網絡確保存儲過程中的單個參與者無法刪除對網絡上文件的訪問的能力
圖片描述
圖片描述
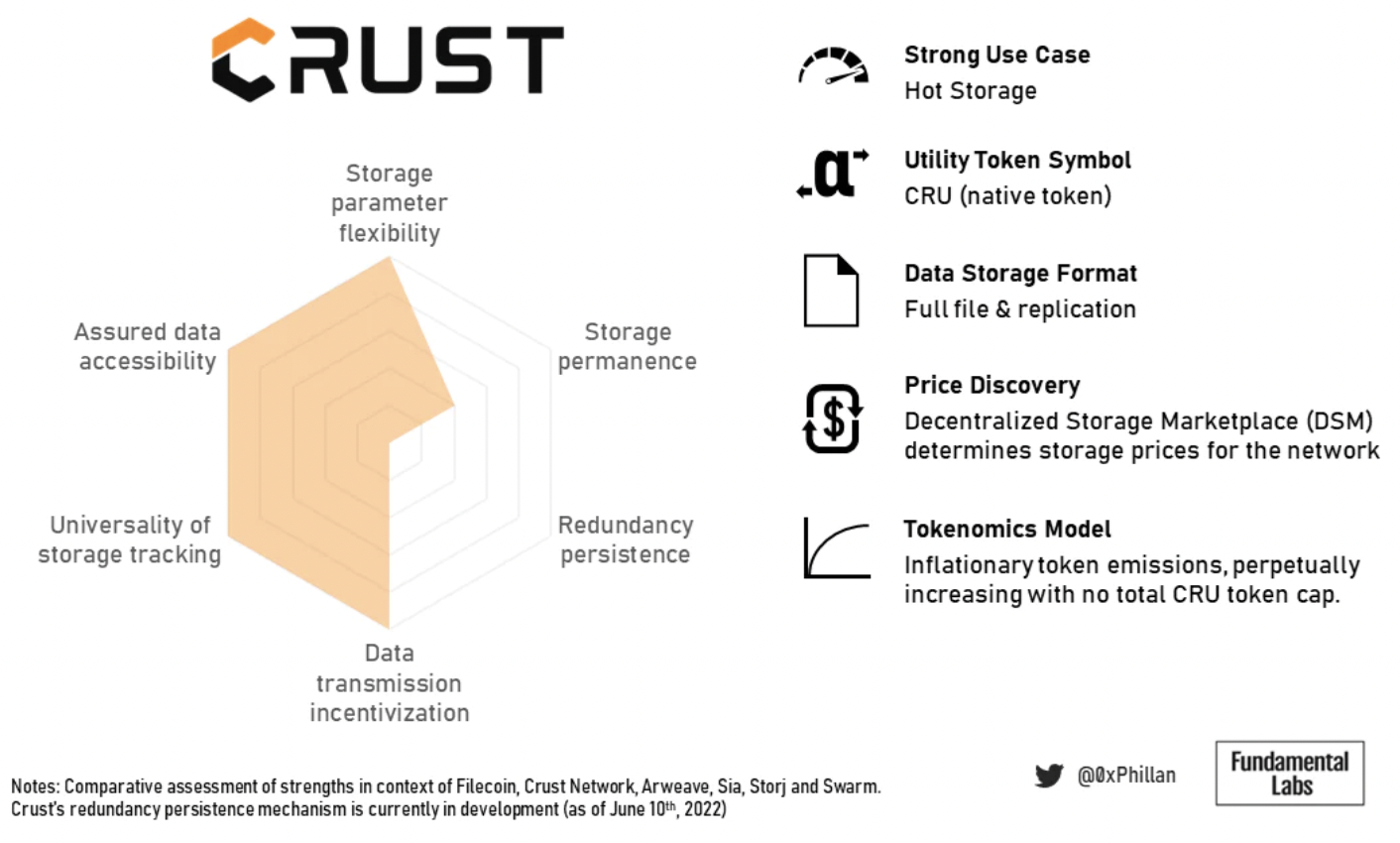
圖片描述
圖片描述
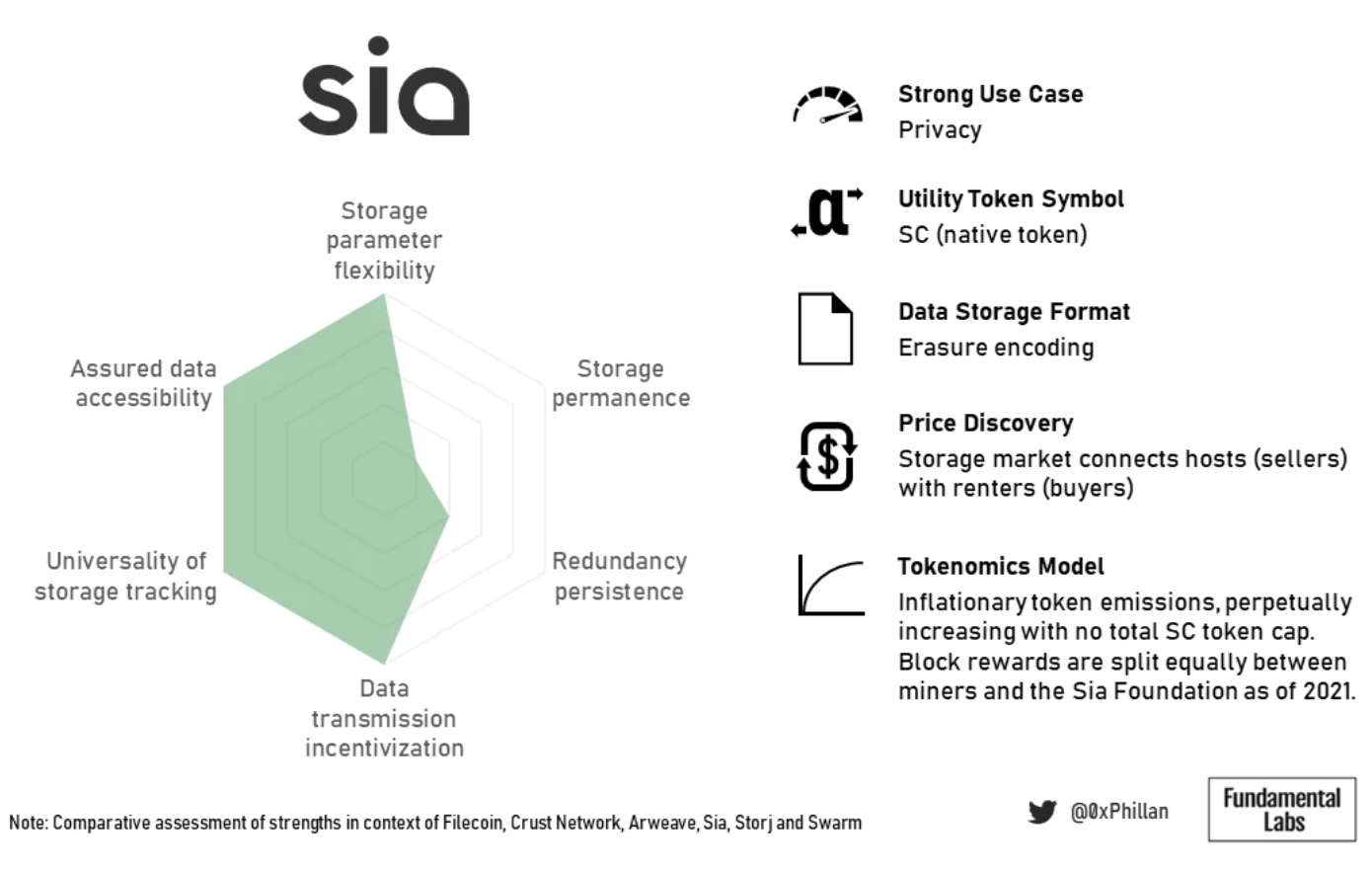
圖片描述
圖片描述
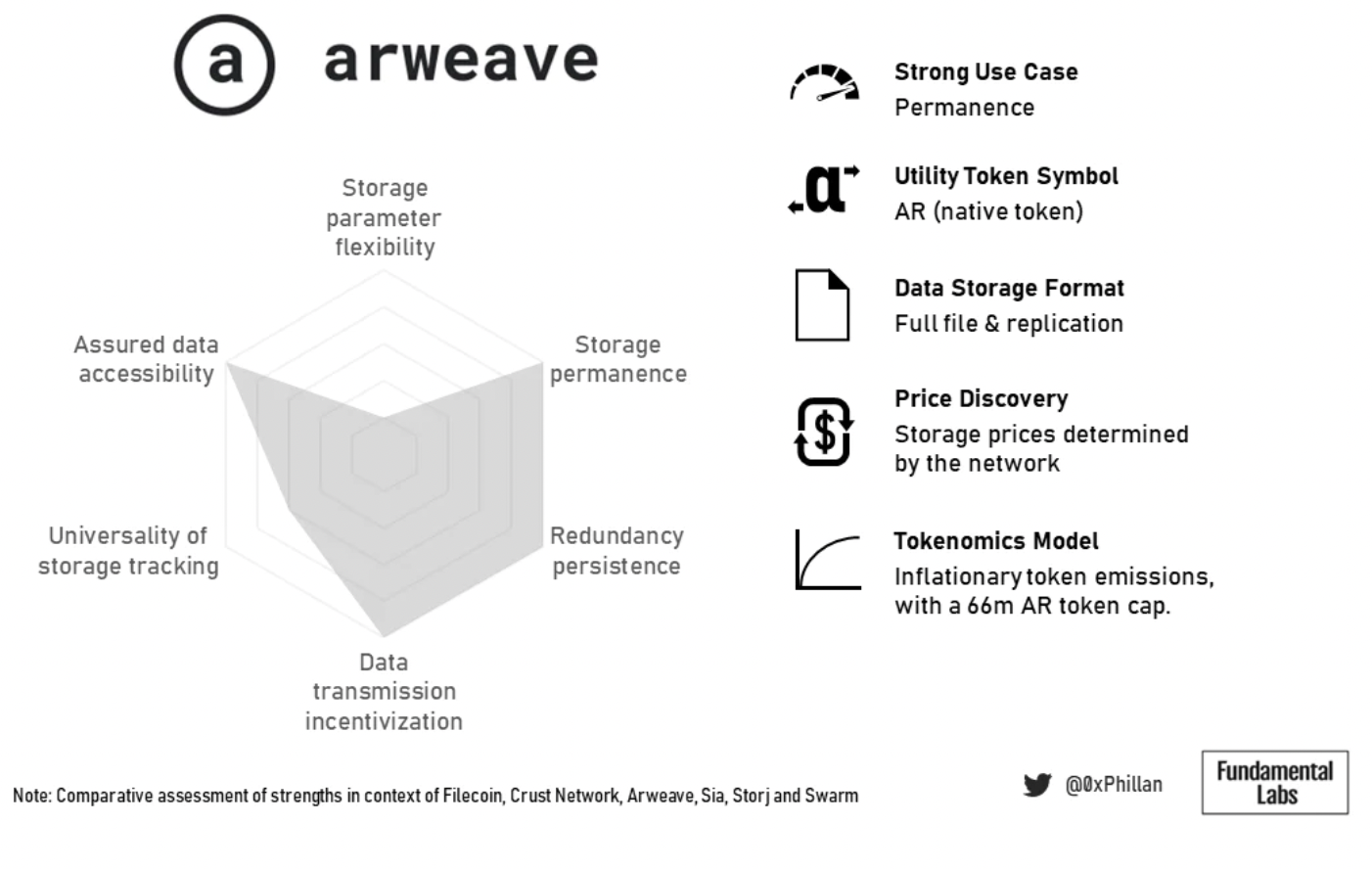
圖片描述
圖片描述
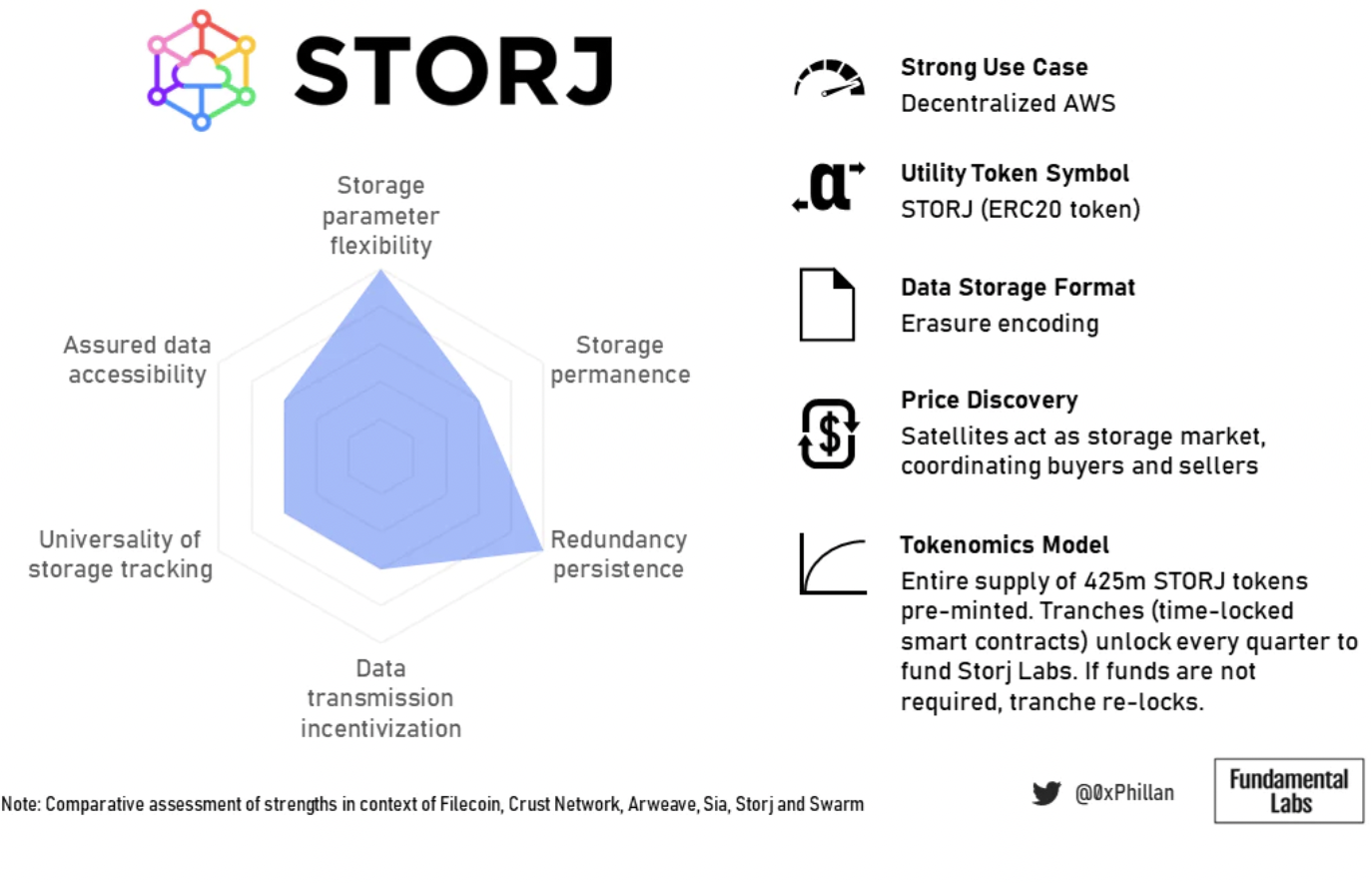
圖片描述
圖片描述
圖片描述
圖片描述

圖片描述
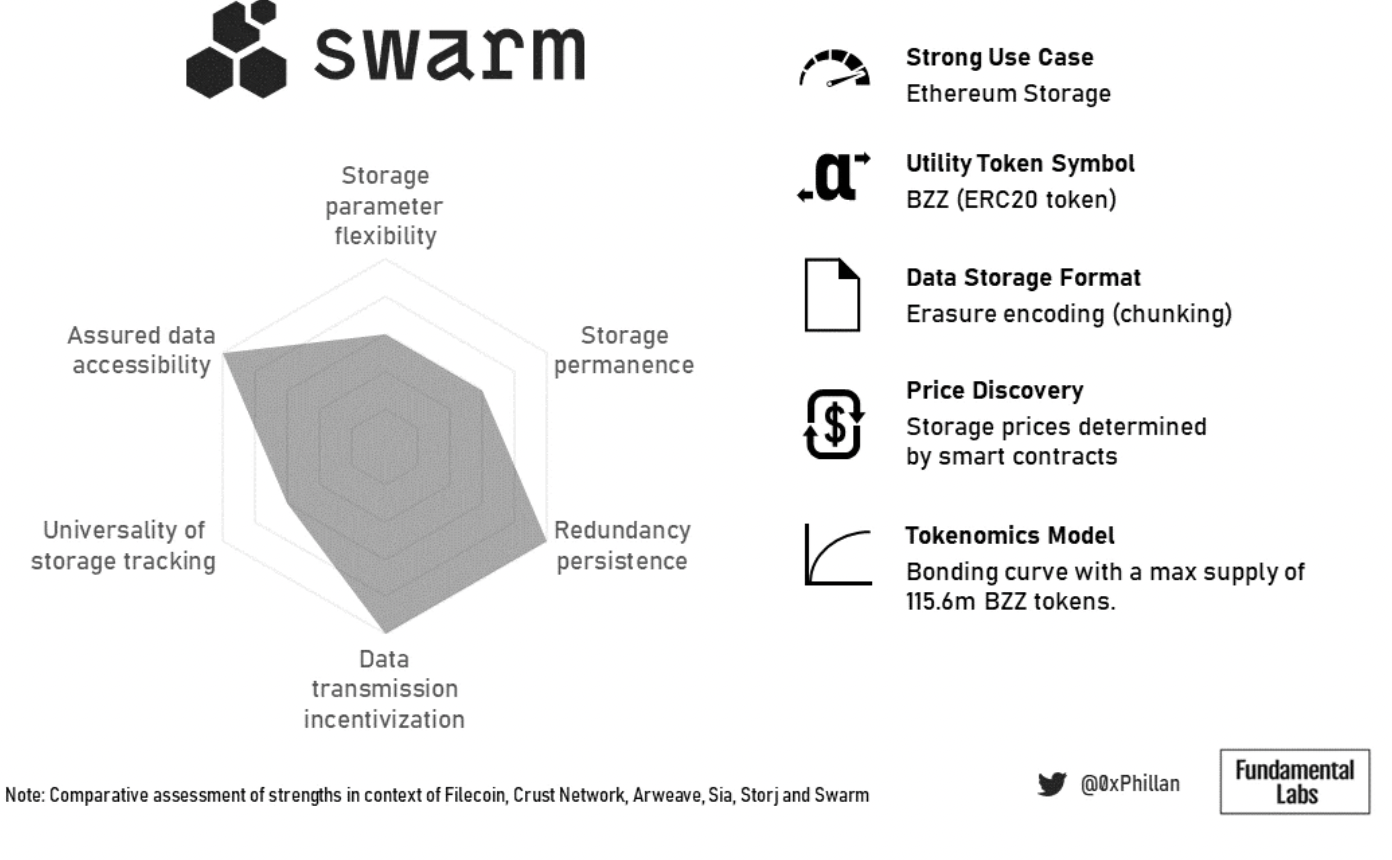
圖20:Swarm 總結概況
圖片描述
圖片描述
圖21:已審查存儲網絡的強大用例總結
回到Web3 基礎設施支柱(共識、存儲、計算),我們看到去中心化存儲空間擁有少數強大的參與者,他們已針對特定用例將自己定位在市場中。這並不排除新網絡優化現有解決方案或占領新的利基市場,但這確實提出了一個問題:下一步是什麼?
結尾
結尾
答案是:計算。實現真正去中心化互聯網的下一個前沿是去中心化計算。目前,只有少數解決方案能夠將去信任、去中心化計算的解決方案推向市場,這些解決方案可以為複雜的dApp 提供支持,這些解決方案能夠以遠低於在區塊鏈上執行智能合約的成本進行更複雜的計算。
互聯網計算機(ICP)和Holochain(HOLO)是在撰寫本文時在去中心化計算市場中佔據強勢地位的網絡。儘管如此,計算空間並不像共識和存儲空間那樣擁擠。因此,強大的競爭對手遲早會進入市場並相應地定位自己。 Stratos(STOS)就是這樣的競爭對手之一。 Stratos 通過其分散式數據網格技術提供獨特的網絡設計。
結尾Arweave、Crust Network完整作品可在
原文鏈接





