作者:Xiang|W3.Hitchhiker
相關閱讀

作者:Xiang|W3.Hitchhiker
二級標題
相關閱讀
Filecoin還有哪些值得關注的呢?
HTTP
"IPFS"一級標題"HTTP"作者:Xiang|W3.Hitchhiker
二級標題
相關閱讀
除了數據存儲,你還了解Filecoin的哪些東西?
一級標題
作者:Xiang|W3.Hitchhiker
二級標題
相關閱讀
Filecoin還有哪些值得關注的呢?"一級標題"。
一級標題
什麼是IPFS
為去中心化互聯網(web3.0)提供動力
一種點對點超媒體協議,通過使網絡可升級、彈性和更開放的方式保存與發展人類的知識。
對標的是一個叫
一級標題
的東西,這你可能比較熟悉,當你上網打開百度搜索頁面時,它所見即所得。
web的應用層協議是超文本傳輸協議(HTTP),它是傳統web的核心。 HTTP由兩個程序實現:一個客戶程序和一個服務器程序。客戶程序和服務器程序運行在不同的端系統,通過交換HTTP進行會話。 HTTP定義了這些數據的結構以及客戶端和服務器進行交互的方式。
web頁面是由對象組成的,一個對像只是一個文件,諸如一個HTML文件,一個JPEG圖形,或一段小視頻片這樣的文件,且它們可以通過URL地址尋址。多數web頁面含有一個html基本文件,以及幾個引用對象。
HTTP定義了web客戶向web服務器請求web頁面的方式,以及服務器向客戶傳送web頁面的方式。
而瀏覽器做的工作就是執行和解析HTTP協議與前端代碼然後將內容展示出來,提交查詢的時候通常是web端查詢它的數據庫然後將結果返回給請求方,也就是瀏覽器,然後瀏覽器展示出來。
一級標題
HTTP協議的弊端
我們現在使用互聯網都是在http或https協議下運行的,http協議也就是超文本傳輸協議,是用於從萬維網服務器傳輸超文本到本地瀏覽器的傳送協議,從1990年提出至今已經32年了,他對於目前互聯網的爆炸性成長居功至偉,成就了互聯網的繁榮。
但是HTTP協議是基於C/S架構下的互聯網通信協議,基於主幹網絡中心化運行的機制,也存在諸多弊端。
互聯網上的數據經常因為文件被刪除或服務器關閉而永久被抹去。有人統計過目前互聯網上的web頁面平均保存壽命只有100天左右,我們經常看到一些網站出現
404錯誤

主幹網絡運行效率低,使用成本高。使用HTTP協議每次需要從中心化的服務器下載完整的文件,速度慢、效率低。
主幹網絡並發機制制約互聯網訪問速度。這種中心化主幹網絡的模式也導致在高並發情況下網絡訪問時候的擁堵。
在現有的http協議下,所有的數據都保存在這些中心化服務器上,互聯網巨頭們不但對我們的數據有絕對的控制權和解釋權,各種各樣的監管、封鎖、監控一定程度上也極大的限制了創新和發展。
成本高,易被攻擊,為了支撐HTTP協議,對於大流量公司,比如百度、騰訊、阿里等,投入大量資源維護服務器和安全隱患,防止DDoS等攻擊。主幹網絡受制於戰爭,自然災害,中心服務器宕機等因素,都可能造成整個互聯網中斷服務。
IPFS的解決方案
IPFS提供了文件的歷史版本回溯功能,可以很容易的查看文件的歷史版本, 且數據無法刪除,可以得到永久保存。IPFS是基於內容尋址的存儲模式,相同的文件都不會重複存儲,它會把過剩的資源擠壓下來,包括存儲空間都釋放出來,數據存儲成本就會降低。如果改用P2P的方式下載,帶寬使用成本可以節省近60%。
IPFS是基於P2P網絡,可以有多個源保存了數據,可以並發從多個節點下載數據。建立在去中心化的分佈式網絡上的IPFS很難被中心化管理和限制,互聯網將更加開放。
IPFS分佈式存儲可以極大的降低對中心主幹網絡的依賴。言簡意賅地說:HTTP依賴中心化服務器,容易遭受攻擊,訪問量暴增服務器容易宕機,下載速度慢,存儲成本高;而IPFS是分佈式節點,更加安全不易被DDoS攻擊,不依賴主幹網,降低存儲成本且存儲空間大,下載速度快還能查找文件歷史版本記錄,並且理論上能永久儲存。
新的技術取代老的技術,無非就兩點:第一,能提高系統效率;
第二,能夠降低系統成本。IPFS把這兩點都做到了。IPFS的團隊在開發時,採用高度模塊集成化的方式,像搭積木一樣去開發整個項目。協議實驗室團隊2015年創立,到17年的時間裡都在做IPLD、LibP2P、Multiformats這三個模塊的開發,它們服務於IPFS底層。Mutiformats是一系列hash 加密算法和自描述方式(從值上就可以知道值是如何生成)的集合,它具有SHA1 \SHA256 \SHA512 \Blake3B 等6種主流的加密方式,用以加密和描述nodeID以及指紋數據的生成。
IPLD其實是一個轉換中間件,將現有的異構數據結構統一成一種格式,方便不同系統之間的數據交換和互操作。現在IPLD支持的數據結構,例如比特幣、以太坊的區塊數據,也支持IPFS和IPLD。這也是IPFS為什麼受到區塊鏈系統歡迎的原因之二,它的IPLD中間件可以把不同的區塊結構統一成一個標準進行傳遞,為開發者提供了成功性比較高的標準,不用擔心性能、穩定和bug。
ipfs好處
IPFS好處
融合了Kademlia、BitTorrent、Git等理念的一種
超媒體分發協議
駛入互聯網的明天
一級標題
IPFS工作原理——新的瀏覽器已經默認支持IPFS協議(brave,opera),傳統瀏覽器可以通過訪問地址如https://ipfs.io等的公共IPFS網關,或者安裝IPFS 伴侶擴展來訪問儲存在IPFS網絡中的文件——只需要在本地節點添加文件就可以使得全球都可以通過緩存友好的內容哈希地址和類BitTorrent網絡帶寬分發來獲得文件
依托強大的開源社區為後盾,為構建
完整分佈式應用和服務
的一個
開發者工具集"IPFS把文件在系統中如何存儲、索引和傳輸都定義好,也就是將上傳好的文件轉換成專門的數據格式進行存儲,同時IPFS會將相同的文件進行了hash計算,確定其唯一的地址。所以無論在任何設備,任意地點,相同的文件都會指向相同的地址(不同於URL,這種地址是原生的,由加密算法保證的,你無法改變,也無需改變)。然後通過一個文件系統將網絡中所有的設備連接起來,然後讓存儲在IPFS系統上的文件,在全世界任何一個地方快速獲取,且不受防火牆的影響(無需網絡代理)。所以從根本上說,IPFS能改變WEB內容的分發機制,使其完成去中心化。"
一級標題
IPFS工作原理
https://en.wikipedia.org/wiki/Aardvark
/Users/Alice/Documents/term_paper.doc
C:\Users\Joe\My Documents\project_sprint_presentation.ppt
IPFS 是一個點對點(p2p) 存儲網絡。可以通過位於世界任何地方的節點訪問內容,這些節點可能會傳遞信息、存儲信息或兩者兼而有之。 IPFS 知道如何使用其內容地址,而不是其位置來查找您要求的內容。理解IPFS 的三個基本原則:通過內容尋址的唯一標識
通過有向無環圖(DAG) 進行內容鏈接
CID (Content Identifiers )
通過分佈式哈希表(DHT) 發現內容這三個原則相互依賴,而打造的IPFS 生態系統。讓我們從
內容尋址
和內容的
開始
內容尋址和內容的唯一標識內容尋址和內容的唯一標識IPFS 使用內容尋址來根據內容而不是位置來識別內容。按內容查找項目是每個人一直在做的事情。
比如你在圖書館找一本書,經常是按書名來找的;那是內容尋址,因為你在問它是什麼。如果你使用位置尋址來查找那本書,你會通過它的位置來找:
互聯網和您的計算機上都存在這個問題!現在,內容是按位置查找的,例如:使用的
加密算法相比之下,每條使用IPFS 協議的內容都有一個*
內容標識符*,即CID。哈希對於它所來自的內容來說是唯一的,即使它與原始內容相比可能看起來很短。
許多分佈式系統通過哈希使用內容尋址,不僅可以識別內容,還可以將其鏈接在一起——從支持代碼的提交到運行加密貨幣的區塊鏈,一切都利用了這種策略。然而,這些系統中的底層數據結構不一定是可互操作的。
CID 規範
起源於IPFS,現在以多格式存在,並支持包括IPFS、IPLD、libp2p 和Filecoin 在內的廣泛項目。儘管我們將在整個課程中分享一些IPFS 示例,但本教程是關於CID 本身的剖析,每個分佈式信息系統都將其用作引用內容的核心標識符。
Multiformats
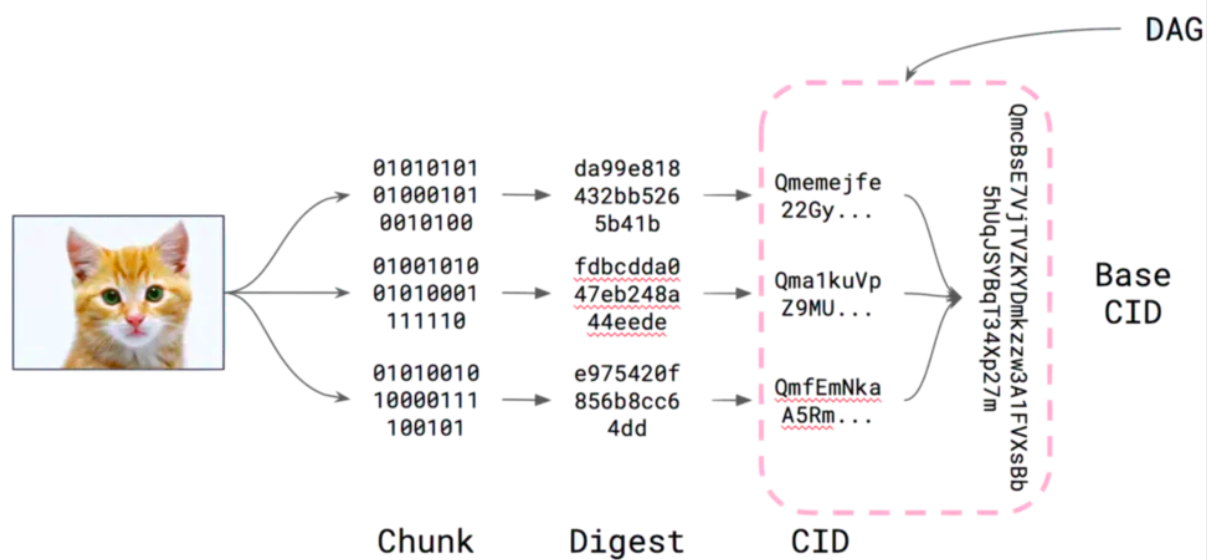
例如,如果我們在IPFS 網絡上存儲了土豚的圖像,它的CID 將如下所示: QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
唯一性:
Multiformats之前的演示過的uniswap的IPFS鏈接
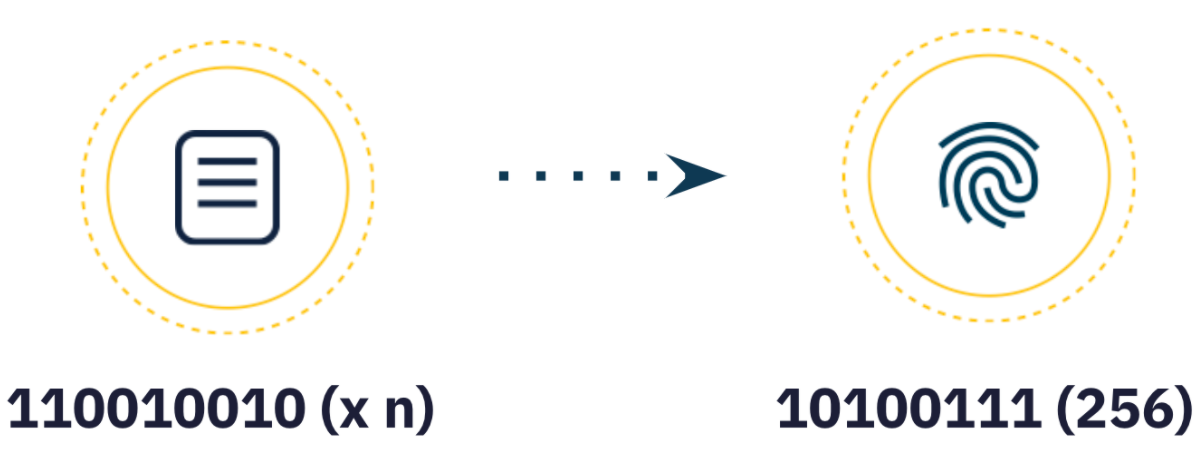
創建CID 的第一步是轉換輸入數據,使用加密算法將任意大小的輸入(數據或文件)映射到固定大小的輸出。這種轉換稱為哈希數字指紋或簡稱哈希(默認使用sha2-256)。
使用的
加密算法
必須生成具有以下特徵的哈希值:
不相關:
multihash - 自描述哈希
輸入數據中的一個小變化應該會產生一個完全不同的哈希。
從哈希值中回推輸入數據是不可行的。
唯一性:
請注意,如果我們更改土豚圖像中的單個像素,加密算法將為圖像生成完全不同的哈希。
當我們使用內容地址獲取數據時,我們可以保證看到該數據的預期版本。這與傳統Web 上的位置尋址完全不同,在傳統Web 上,給定地址(URL) 上的內容會隨時間而變化。
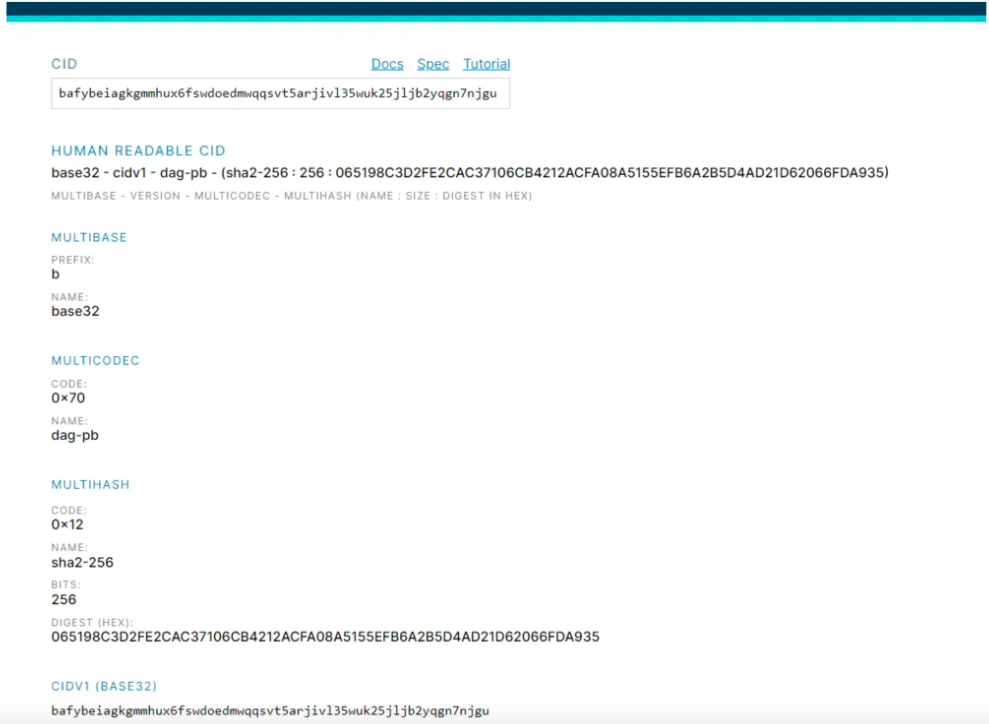
CID的結構
Multiformats在IPFS體系中主要負責身份的加密和數據的自我描述。
Multiformats是未來安全系統的協議集合,自描述格式可以讓系統可互相協作和升級。
multiaddr - 自描述網絡地址
可分配性
可分配性
multibase - 自描述基編碼
multicodec - 自描述序列化
multistream - 自描述流網絡協議
multigram (WIP) - 自描述分組網絡協議
一級標題
內容鏈接有向無環圖(DAG)
Merkle DAG 繼承了CID的可分配性。對DAG 使用內容尋址會對它們的分發產生一些有趣的影響。首先,當然,任何擁有DAG 的人都能夠充當該DAG 的提供者。第二個是當我們檢索編碼為DAG 的數據時,比如文件目錄,我們可以利用這一事實並行檢索節點的所有子節點,可能來自許多不同的提供者!三是文件服務器不僅限於集中式數據中心,讓我們的數據覆蓋範圍更廣。最後,因為DAG 中的每個節點都有自己的CID,所以它所代表的DAG 可以獨立於它本身嵌入的任何DAG 進行共享和檢索。
可驗證性
是否曾經備份了文件,然後在幾個月後找到這兩個文件或目錄並想知道它們的內容是否相同?你可以為每個備份計算一個Merkle DAG,而不需要費力地比較文件:如果根目錄的CID 匹配,就會知道哪些可以安全地刪除,並釋放硬盤驅動器上的一些空間!
可分配性
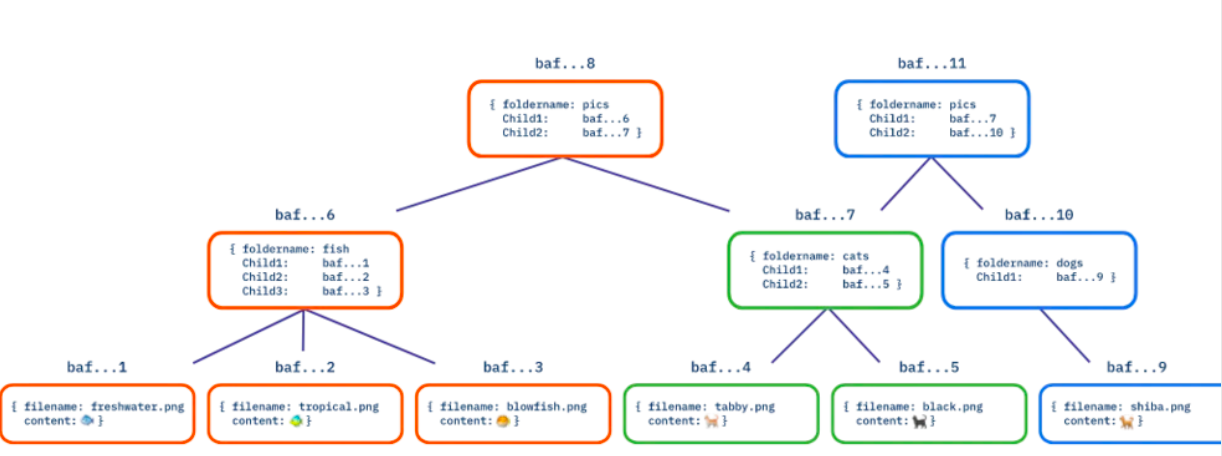
例如,一個大型數據的分發。在傳統web網絡上:
共享文件的開發人員負責維護服務器及其相關費用
數據本身可以作為單個文件存檔以單片方式分佈
Libp2p
libp2p很難找到相同數據的替代供應者IPFS數據可能是大塊的,必須從單個供應者那串行下載
來自世界各地的節點都可以參與服務數據
網絡
一級標題
DAG的每一部分都有自己的CID,可以獨立分發構成DAG 的節點很小,可以從許多不同的供應者處並行下載
NAT:所有這些都有助於重要數據的可擴展性。
一級標題一級標題
可靠性:例如,以瀏覽網頁為例!當一個人使用瀏覽器訪問網頁時,瀏覽器必須先下載與該頁面相關的資源,包括圖像、文本和样式。其實許多網頁實際上看起來非常相似,只是使用了相同主題其他只是略有變化。這裡會產生很多冗餘。
當瀏覽器足夠優化的時候,可以避免多次下載該組件。每當用戶訪問新網站時,瀏覽器只需下載其DAG 中與不同部分相對應的節點,而之前已經下載了其他部分不需要再次下載! (想想WordPress 主題、Bootstrap CSS 庫或常見的JavaScript 庫)分佈式哈希表(DHT) 是用於將鍵映射到值的分佈式系統。在IPFS 中,DHT 被用作內容路由系統的基本組件,並且充當目錄和導航系統之間的交叉點。它將用戶正在尋找的內容映射到存儲匹配內容的peer節點。可以把它想像成一個巨大的表格,存儲誰擁有什麼數據。
一級標題一級標題
可靠性:是一個模塊化的網絡堆棧,它從
演變為一個獨立的項目。波卡也在用,eth2.0也在部分使用。為了解釋為什麼libp2p 是去中心化網絡中如此重要的一部分,我們需要退後一步,了解它的來源。 libp2p 的初始實現始於IPFS,一個點對點文件共享系統。讓我們從探索IPFS 旨在解決的網絡問題開始。
一級標題網絡是非常複雜的系統,有自己的規則和限制,因此在設計這些系統時,我們需要考慮很多情況和用例:
防火牆:
您的筆記本電腦中可能安裝了防火牆,阻止或限制特定連接。
您的家庭WiFi 路由器,帶有NAT(網絡地址轉換),可將您筆記本電腦的本地IP 地址轉換為您家外的網絡可以連接的單個IP 地址。
高延遲網絡:
Peer 這些網絡的連接速度非常慢,讓用戶等待很長時間才能看到他們的內容。
Peer-to-Peer (P2P) 可靠性:
世界各地分佈著許多網絡,而且很多用戶經常遇到速度慢的網絡,這些網絡沒有強大的系統來為用戶提供良好的連接。連接頻繁斷開,用戶的網絡系統質量不佳,無法為用戶提供應有的服務。
漫遊:
移動尋址是另一種情況,我們需要保證用戶的設備在通過世界各地的不同網絡導航時保持唯一可發現性。目前,它們在需要大量協調點和連接的分佈式系統中工作,但最好的解決方案是去中心化的。
審查制度:
在當前的網絡狀態下,如果您是政府實體,在特定網站域中屏蔽網站相對容易。這對於阻止非法活動很有用,但當一個專制政權想要剝奪其人口對資源的訪問權時,就會成為一個問題。
具有不同屬性
的運行時:周圍有許多類型的運行時,例如物聯網(物聯網)設備(Raspberry Pi、Arduino 等),它們正在獲得大量採用。因為它們是用有限的資源構建的,所以它們的運行時通常使用不同的協議,這些協議對它們的運行時做出了很多假設。
即使是擁有大量資源的最成功的公司也可能需要數十年的時間來開發和部署新協議。
文件不佳或不存在
數據隱私:
消費者最近越來越擔心越來越多不尊重用戶隱私的公司。
p2p協議當前問題
P2P協議當前問題
點對點(P2P) 網絡從互聯網的概念中被設想為一種創建彈性網絡的方式,即使peer節點由於重大的自然或人為災難而與網絡斷開連接,該網絡仍能正常工作,從而允許人們繼續通信。
P2P 網絡可用於各種用例,從視頻通話(例如Skype)到文件共享(例如IPFS、Gnutella、KaZaA、eMule 和BitTorrent)。
基礎概念
- 去中心化網絡的參與者。 peer節點是應用程序中同等特權、同等能力的參與者。在IPFS 中,當您在筆記本電腦上加載IPFS 桌面應用程序時,您的設備將成為去中心化網絡IPFS 中的Peer節點。
- 一個分散的網絡,工作負載在peer節點之間共享。因此,在IPFS 中,每個Peer節點都可能託管要與其他peer節點共享的全部或部分文件。當一個節點請求文件時,任何擁有這些文件塊的節點都可以參與發送請求的文件。然後,請求數據的節點方可以稍後與其他節點方共享數據。
現有P2P 系統的代碼實現真的很難找到,而且在它們確實存在的地方,由於以下原因,它們通常難以重用或重新調整用途:模塊化。

文件不佳或不存在

限制性許可或找不到許可

十多年前最後一次更新的非常舊的代碼

IPLD
已棄用的產品
I答案是:
模塊化
未提供規格沒有暴露友好的API。
實現與特定用例的耦合過於緊密無法使用未來的協議升級
libp2p 是IPFS 的網絡棧,但從IPFS 中抽離出來,成為獨立一流的項目和IPFS 的依賴項目。模塊化
通過這種方式,libp2p 能夠在不依賴於IPFS 的情況下進一步發展,獲得自己的生態系統和社區。 IPFS 只是成為libp2p 的眾多用戶之一。
這樣,每個項目都可以只專注於自己的目標:
IPFS 更專注於內容尋址,即查找、獲取和驗證網絡中的任何內容。
libp2p 更側重於進程尋址,即查找、連接和驗證網絡中的任何數據傳輸進程。那麼libp2p 是如何做到的呢?
答案是:模塊化
libp2p 已經確定了可以構成網絡堆棧的特定部分:
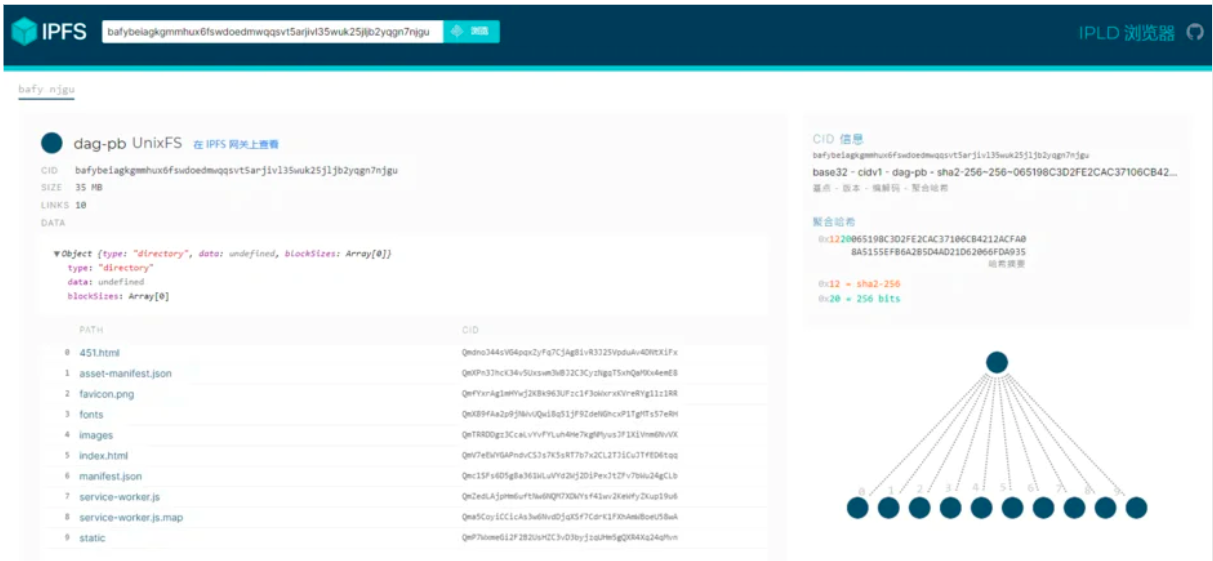
多語言實現,支持7種開發語言,libp2p 的JavaScript 實現也適用於瀏覽器和移動瀏覽器!這非常重要,因為它使應用程序也可以在桌面和移動設備上運行libp2p。IPLD 用於理解和處理數據。
Filecoin
PLD是一個轉換中間件,將現有的異構數據結構統一成一種格式,方便不同系統之間的數據交換和互操作,數據模型與解碼,使用CID做為鏈接。首先,我們定義了一個“數據模型”,它說明了數據的域和範圍。這很重要,因為它是我們將要構建的一切的基礎。 (廣義地說,我們可以說數據模型“像JSON”,像map、string、list等) 此後,我們定義了“編解碼器”,它說明瞭如何從消息中解析它並作為我們想要的消息形式發出。 IPLD 有很多編解碼器。您可以根據您希望與之交互的其他應用程序選擇使用不同的編解碼器,或者僅根據您自己的應用程序喜歡的性能與人類可讀性的適合性來選擇使用不同的編解碼器。
IPLD 實現了最上面的三層協議:





