Tác giả: Chiếc kính soi
Lý do được đề xuất:
Lý do được đề xuất:
"Tôi là ai" là sự tự nhận thức của bất kỳ người nào có ý thức về bản thân, và trong sự tự nhận thức này, anh ta trở thành đối tượng cho suy nghĩ của chính mình. Bản sắc là một khái niệm toàn diện và phức tạp, cấu thành về mặt tâm lý các đặc điểm, niềm tin, tính cách, ngoại hình và biểu hiện của một người hoặc một nhóm. Làm cách nào để diễn đạt các khái niệm về nhận dạng trên chuỗi, nhận dạng kỹ thuật số và nhận dạng mạng cũng như loại hệ thống quản lý nhận dạng nào chúng ta cần trong câu chuyện phi tập trung? Nhận dạng phi tập trung (DID) tốt hơn hệ thống nhận dạng web2 hiện có như thế nào?
Chúng ta đã tồn tại trên hòn đảo bị cô lập của thế giới web2 quá lâu, với rò rỉ quyền riêng tư, lạm dụng thông tin và khai thác thuật toán. ."I own my data"hệ thống nhận dạng.
Càng viết nhiều về "bản sắc", từ này càng trở thành một thuật ngữ khó hiểu vì tính phổ biến của nó. ——Erik Erikson
Như Erik Erikson, nhà tâm lý học đã đặt ra thuật ngữ "khủng hoảng danh tính", nói, tôi thường cảm thấy điều đó đúng: Danh tính là một khái niệm mơ hồ với nhiều hàm ý và ý nghĩa của nó phụ thuộc nhiều vào ngữ cảnh, điều này cũng không ngoại lệ trong Web3.
Trong bài đăng này, tôi sẽ cố gắng giải quyết vấn đề này: xây dựng một khung—một khung xem danh tính trên web như một công cụ chủ yếu để lưu trữ, quản lý và truy xuất thông tin.
tiêu đề cấp đầu tiên
Có gì trong tên? Ba Ý Nghĩa của “Bản Sắc”
Khi mọi người nói về danh tính, họ thường muốn nói đến một trong ba phạm vi có liên quan nhưng khác biệt: a) mã định danh duy nhất, b) chế độ xem tổng thể của một thực thể hoặc c) ngữ cảnh cụ thể về thực thể.
Số nhận dạng duy nhất rất quan trọng trong bất kỳ môi trường xã hội nào. Trong số bạn bè, thành viên gia đình hoặc bộ lạc nhỏ (dưới ngưỡng 150 người của Dunbar), những người có thể được coi là quen thuộc, một cái tên là một "dấu hiệu nhận dạng" đầy đủ. Ngoài ra, các số nhận dạng chặt chẽ hơn giúp làm cho người tham gia "hiển thị" trong hệ thống rộng lớn hơn. Các tiểu bang triển khai thẻ ID để quản lý thuế, nghĩa vụ quân sự và các chương trình xã hội. Ứng dụng web có ID người dùng trong bảng người dùng mà nó sử dụng để theo dõi, quản lý và phục vụ khách hàng của mình.
Chế độ xem toàn diện đề cập đến tất cả thông tin có thể có về người dùng hoặc các tác nhân khác. Việc cố gắng đính kèm một lượng lớn dữ liệu vào một mã định danh duy nhất có thể tạo ra một tập hợp thông tin phong phú về một người hoặc thực thể. Việc theo đuổi điều này có thể được nhìn thấy trong cơ sở dữ liệu người dùng của Facebook và Google, hệ thống tín dụng xã hội Aadhaar của Ấn Độ và Trung Quốc cũng như các nền tảng dữ liệu khách hàng như Segment và LiveRamp.
Một bối cảnh cụ thể có thể được biểu diễn dưới dạng bất kỳ tập hợp con nào của chế độ xem tổng thể. KYC hoặc Xác minh danh tính - một ngành công nghiệp trị giá hàng tỷ đô la - là về việc xác minh rằng ai đó là danh tính có thể xác minh duy nhất mà họ tuyên bố là có trong hệ thống quốc gia. Tương tự như vậy, các thuật toán xác thực, chống gian lận, chống thư rác và tín dụng là các dịch vụ cụ thể tập trung vào các tập hợp con thông tin trong một cái nhìn tổng thể.
tiêu đề cấp đầu tiên
Danh tính: đính kèm thông tin vào một mã định danh
Định danh duy nhất là cần thiết nhưng bản thân chúng vô dụng. Chúng hầu như luôn được sử dụng để chuyển đến một số thông tin. Đây có thể là tên và địa chỉ trong hồ sơ trạng thái, tài liệu trong hệ thống tệp, mật khẩu trong cơ sở dữ liệu ứng dụng hoặc số dư mã thông báo hoặc lịch sử giao dịch trên chuỗi khối. Trong bất kỳ trường hợp nào, mã định danh đều hữu ích vì nó truyền tải thông tin liên quan.
Nhiều tình huống yêu cầu truy xuất hoặc xác minh ngữ cảnh cụ thể được liên kết với số nhận dạng. Ví dụ: Gitcoin cần một "hệ thống nhận dạng" để ngăn chặn các cuộc tấn công từ bên ngoài vào nền tảng Grants của nó. Trên thực tế, họ cần ánh xạ bằng chứng cá nhân (xác minh KYC, tài khoản twitter) thành một mã định danh duy nhất. Họ càng có nhiều thông tin về tiềm năng độc nhất hoặc gian lận của cá nhân, thì nền tảng của họ càng hoạt động tốt hơn.
Quan điểm tổng thể về danh tính luôn không đầy đủ — cũng như chúng ta không bao giờ có thể mô tả hoàn hảo “con người thật” của mình trong không gian, bản thân kỹ thuật số của chúng ta sẽ không bao giờ hoàn toàn nhất quán hoặc toàn diện. Nhưng càng nhiều dữ liệu được thu thập xung quanh một (hoặc tập hợp các mã định danh được liên kết), chúng tôi càng có thể sử dụng nhiều thông tin hơn cho bất kỳ ngữ cảnh cụ thể nào.
Mẫu số chung là: Các hệ thống nhận dạng tạo ra khả năng liên kết thông tin một cách đáng tin cậy với các số nhận dạng duy nhất. Hệ thống nhận dạng càng đáng tin cậy thì càng hữu ích và:
đáng tin cậy hơn:Có sẵn, chịu lỗi, chống giả mạo
Linh hoạt hơn:Có thể xử lý nhiều loại thông tin hơn
Dễ sử dụng hơn:Có thể được sử dụng trong nhiều ngữ cảnh hơn, thống nhất hơn là phân tán thông tin
tiêu đề cấp đầu tiên
Nhận dạng kỹ thuật số dưới dạng 🔑 của web
Nói một cách đơn giản nhất, web chạy trên phần cứng, mã và dữ liệu. Mọi trang web bạn truy cập đều có logic và quy tắc được viết bằng mã và hầu hết tất cả các trang web đều chứa đầy thông tin được mã hóa trong dữ liệu. Dữ liệu này—dù là tin tức hôm nay, tweet của bạn bè hay bản nháp email mới nhất của bạn—phải được truy xuất một cách chính xác và đáng tin cậy khi bạn đến trang web. Điều này được thực hiện thông qua định danh.
Giống như một mã định danh duy nhất sẽ vô dụng nếu không có dữ liệu kèm theo, dữ liệu trên web cũng không hữu ích lắm nếu không thể truy xuất vào đúng thời điểm. Các mã định danh duy nhất, bảng định tuyến và logic được xây dựng xung quanh chúng, được sử dụng để sắp xếp dữ liệu chứa dữ liệu đó trên mạng. Ai đang tạo ra những định danh này? Ai đang tổ chức dữ liệu xung quanh chúng?
Mô tả hình ảnh
Bảng người dùng truyền thống trên cơ sở dữ liệu ứng dụng
Hệ thống nhận dạng này có đáp ứng các tiêu chí trên của chúng tôi không?
đáng tin cậy:👍🏽 rất đáng tin cậy nhưng 👎🏽👎🏽 không thể kiểm tra được và rất dễ bị hack và lỗi
linh hoạt:👍🏽 Các loại cơ sở dữ liệu có thể được xâu chuỗi để xử lý nhiều thông tin khác nhau, mặc dù có thể hơi khó hiểu
Có sẵn:👎🏽👎🏽👎🏽 Mỗi ứng dụng cần có mã định danh riêng, thông tin (và cách quản lý) rất rời rạc, dư thừa và không hiệu quả
Từ góc độ vĩ mô, đây là một hệ thống nhận dạng rất tệ cho web - bởi vì nó không phải là một hệ thống nhận dạng mà là nhiều hệ thống nhận dạng khác nhau. Nó phân mảnh thông tin, giới hạn giá trị và việc sử dụng của nó đối với từng người tham gia. (Điều này cũng tạo ra động lực khủng khiếp cho việc tích trữ và lạm dụng dữ liệu người dùng ngoài phạm vi của bài viết này).
tiêu đề cấp đầu tiên
Nhận dạng phi tập trung: Cách Web3 vượt qua Web2
Chuỗi khối là một dạng công nghệ sổ cái phân tán (DLT), về cơ bản là một cơ sở dữ liệu được chia sẻ. Cơ sở dữ liệu dùng chung có vẻ như là một nơi tốt để đặt một bảng người dùng hợp nhất và loại bỏ nhu cầu cổ xưa đối với mỗi ứng dụng để tạo hệ thống nhận dạng của riêng mình.
Đây là tầm nhìn tương lai về danh tính phi tập trung và là trụ cột cốt lõi của tầm nhìn Web3: mọi người dùng và nhà xây dựng đều kiểm soát dữ liệu, giá trị, mối quan hệ và thông tin của chính họ. Trong tầm nhìn này, mỗi người dùng trở thành một điểm khám phá thống nhất cho dữ liệu của riêng họ, tạo khả năng tái sử dụng và khả năng kết hợp giữa các ứng dụng. Điều này tạo ra các hiệu ứng mạng được chia sẻ, khả năng tương tác và trải nghiệm tổng hợp mà các ứng dụng tập trung không thể cạnh tranh được.
Tầm nhìn của phiên bản gốc đã hình dung ra một sổ đăng ký người dùng thống nhất (trên một DLT) và một cách tiêu chuẩn để tất cả các ứng dụng thêm thông tin vào sổ đăng ký đó. Người dùng kiểm soát địa chỉ chủ quyền được mã hóa (hoặc số nhận dạng) của riêng họ mà họ ký tất cả dữ liệu để tạo sự tin cậy mà dữ liệu yêu cầu trong môi trường mở. Chúng tôi cho phép mọi ứng dụng sử dụng cùng một sổ đăng ký (chuỗi khối) và xuất bản dữ liệu bằng định dạng chuẩn (NFT) và về lý thuyết, chúng tôi đang ở trong niết bàn nhận dạng - một mạng mang biểu đồ xã hội đến các ứng dụng, độc lập với khán giả và cộng đồng tương tác liền mạch với các nền tảng và dễ dàng di chuyển giữa các sản phẩm và dịch vụ mới ngay khi chúng có sẵn vì tất cả chúng đều có thể tương tác với nhau.
Tuy nhiên, tầm nhìn về danh tính phi tập trung này - dựa trên địa chỉ và NFT - nhanh chóng thất bại trong thực tế. Quá cứng nhắc để quản lý và định tuyến dữ liệu ở quy mô tốt như một hệ thống nhận dạng. Theo tiêu chuẩn của chúng tôi:
đáng tin cậy:👎🏽 Các chuỗi khối ngày nay, được thiết kế để đạt được sự đồng thuận về các tài sản tài chính khan hiếm, không thể mở rộng theo quy mô với lượng dữ liệu khổng lồ; chúng cũng không thể xử lý các bản cập nhật ngoại tuyến (hoặc một phần)
linh hoạt:👍🏽👎🏽 Hầu hết các sổ cái trên chuỗi đều hỗ trợ các tiêu chuẩn và cấu trúc dữ liệu mới, nhưng trong giới hạn của hệ thống đồng thuận. Điều này giới hạn các trường hợp sử dụng và ứng dụng của hệ thống
khả năng tiếp cận:👎🏽 Một cơ quan đăng ký duy nhất giới hạn người dùng và ứng dụng trong một DLT hoặc chuỗi khối duy nhất, trong khi chúng tôi chắc chắn sử dụng các chuỗi và mạng khác nhau
Chúng ta có thể học hỏi từ những sai sót của hệ thống nhận dạng mật mã ban đầu để hiểu những gì cần thiết cho một hệ thống nhận dạng phi tập trung đáng tin cậy hơn. Rõ ràng, một sổ đăng ký (chỉ mục), tiêu chuẩn định danh hoặc tiêu chuẩn cấu trúc dữ liệu luôn quá cứng nhắc.
tiêu đề cấp đầu tiên
Web3 sẽ xử lý bảng người dùng như thế nào
Để quản lý dữ liệu, chúng tôi cần một giao thức để dễ dàng lưu trữ, khám phá và định tuyến thông tin về số nhận dạng. Để Web3 thực hiện đúng lời hứa của mình, bảng định tuyến này phải a) được thống nhất, không bị cô lập bởi ứng dụng hoặc bất kỳ ranh giới nào khác và b) có chủ quyền, ủy quyền kiểm soát dữ liệu trực tiếp cho từng mã định danh.
Điều này gợi ý một thiết kế đơn giản: mỗi mã định danh duy trì một bảng chứa dữ liệu của chính nó. Được kết hợp với nhau, các bảng người dùng tập trung vào danh tính này tạo thành bảng người dùng phân tán của Internet. Bảng người dùng phân tán này không phải là một bảng thực, mà là một bảng ảo, được tạo bởi một số thành phần tương ứng với các phần của bảng người dùng truyền thống:
Định danh:Số nhận dạng phi tập trung không nên là mục nhập trong cơ sở dữ liệu ứng dụng, nhưng phải là duy nhất có thể chứng minh được và được kiểm soát bằng mật mã. Khả năng truy cập yêu cầu chấp nhận nhiều dạng số nhận dạng trên nhiều mạng khác nhau - tương tự như tiêu chuẩn DID cho số nhận dạng phi tập trung.
cấu trúc dữ liệu:Tương tự như cách các nhà phát triển ứng dụng xác định cấu trúc dữ liệu của riêng họ, lớp dữ liệu phi tập trung cần cho phép các nhà phát triển xác định các mô hình dữ liệu tùy chỉnh đồng thời đảm bảo rằng các mô hình này có thể tái sử dụng và lưu trữ công khai.
mục lục:Mô tả hình ảnh
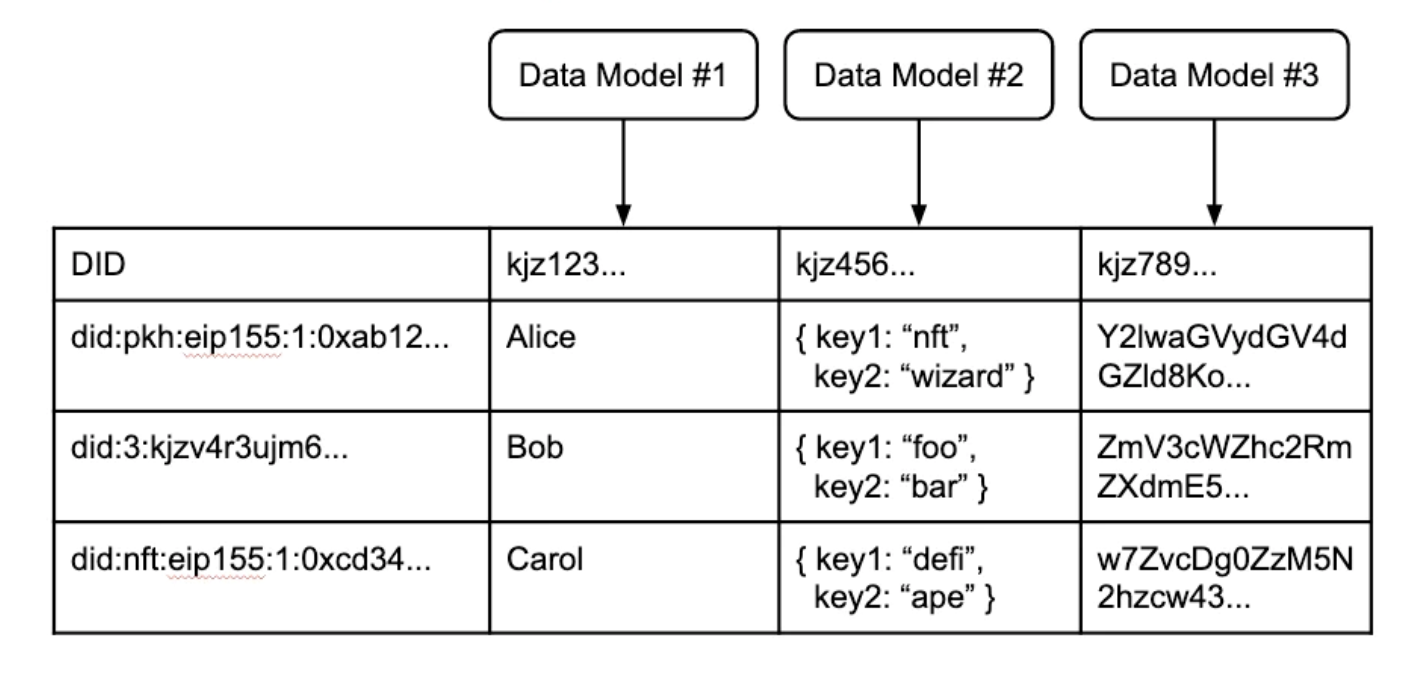
Bảng người dùng ảo được phân phối với nhiều DID khác nhau từ các mạng khác nhau, mô hình dữ liệu do nhà phát triển xác định và các bản ghi được liên kết với mỗi
tiêu đề cấp đầu tiên
Xây dựng với Bảng người dùng phân tán
Hệ thống nhận dạng dựa trên DID và mô hình dữ liệu cũng như bảng người dùng phân tán này đáp ứng các tiêu chí của chúng tôi như thế nào?
đáng tin cậy:👍🏽👍🏽 Chạy trên các bộ sưu tập mạng công cộng mà bất kỳ ai cũng có thể tham gia, bao gồm cả mạng được phân vùng hoặc mạng cục bộ
linh hoạt:👍🏽👍🏽 Hoạt động với mọi cấu trúc dữ liệu mà nhà phát triển có thể xác định
Khả dụng:👍🏽👍🏽 Hoạt động với mọi mạng mở và số nhận dạng duy nhất
Hệ thống này cũng có một số thuộc tính bổ sung tạo nên một hệ thống nhận dạng rất linh hoạt và đáng tin cậy. bao gồm:
Kana đầu tiên:Không cần tạo tài khoản hoặc xác minh để bắt đầu, người dùng (hoặc thực thể khác) chỉ cần mang theo một cặp khóa mật mã và bắt đầu tích lũy thông tin xung quanh nó
có thể tạo ra:Thông tin tích lũy theo thời gian, tạo ra một bản sắc tổng thể mới nổi
có thể kết hợp:Khám phá và chia sẻ thông tin qua các ngữ cảnh mà không cần tích hợp hoặc tiêu chuẩn di động được xác định trước
tách biệt và chọn lọc: Bộ thông tin có thể được mã hóa hoặc làm xáo trộn hoặc phân tách trên nhiều mã định danh hoặc phân chia theo tùy chọn của bộ điều khiển
Nếu "các hệ thống nhận dạng có khả năng liên kết thông tin một cách đáng tin cậy với các số nhận dạng duy nhất", như đã nêu trước đó, thì chúng ta cần một hệ thống nhận dạng internet thiết lập các giao thức tối thiểu để quản lý và định tuyến đến dữ liệu đáng tin cậy, mọi thứ khác để lại cho sự khéo léo và tính đa dạng của nhà phát triển ứng dụng.
Chúng tôi muốn tránh các hệ thống im lặng — bao gồm các ứng dụng, cơ quan đăng ký hoặc chuỗi khối cụ thể — và tối đa hóa tính linh hoạt trong các loại dữ liệu. Chúng tôi cần một hệ thống dễ sử dụng cho phép chúng tôi xây dựng các ứng dụng với các dạng dữ liệu phong phú, liên kết những dữ liệu đó với số nhận dạng thích hợp và thu được tiện ích tối đa từ danh tính và thông tin tập thể của chúng tôi.
Ghi chú của người dịch:
Ghi chú của người dịch:
Tương lai của web3 và Metaverse làm mờ ranh giới giữa thế giới ngoài chuỗi và không gian trên chuỗi. Do đó, để xây dựng hệ thống quản lý danh tính, cách thiết lập mối quan hệ ánh xạ giữa danh tính ngoài chuỗi và dữ liệu trên chuỗi là không gian sống số để phát triển một hệ thống xã hội mới Bài tập phải làm và nền tảng của một chỗ đứng.
Một hệ thống nhận dạng bị cô lập là một trở ngại cho trải nghiệm Dapp liền mạch trong tương lai. Việc xây dựng một bảng người dùng phân tán có lợi cho việc vượt qua các đảo ứng dụng hiện có. Làm thế nào để tìm được sự cân bằng giữa tính linh hoạt, tính mở và độ tin cậy trong hệ thống DID? Tác giả đề xuất Gốm sứ và các cơ sở hạ tầng khác, chúng tôi sẽ phân tích dự án trong các bài viết liên quan sau.
H.Forest Ventures sẽ cố gắng hết sức để hiểu đầy đủ các thông tin liên quan cho từng nội dung được chia sẻ. Nếu bạn có bất kỳ suy nghĩ nào về nội dung của bài viết này, vui lòng liên hệ với nhóm H.Forest Ventures.
Effective communication is everything.





