オリジナル: 特異な軌跡
1999年、レイ・カーツワイルは次のような予言をしました。
2009 年には、コンピューターは高品質だが従来型のディスプレイを備えたタブレットまたは小型デバイスになるでしょう。
2019 年には、コンピューターは「本質的に見えなくなり」、ほとんどの画像が網膜に直接投影されるようになるでしょう。
2029 年には、コンピューターは直接神経経路を介して通信するようになるでしょう。
過去 20 年間の人工知能、ロボット工学、製造業の発展、特に最近の AIGC の進歩を見ると、テクノロジーの発展がシンギュラリティに向かって加速していることを示す兆候がいくつかあります。
技術的特異点
シンギュラリティとはもともと「特異性、卓越性、希少性」を意味し、その意味は徐々に自然科学に拡張され、最初は数学の分野に適用され、後に物理学や天文学の分野にも拡張されました。 「技術的特異点」の予測にはさまざまなバージョンが続きました。

技術的特異点「バージョン 1.0」:
1958 年、ポーランドの数学者スタニスワフ マルシン ウラムによって「技術的特異点」の概念が初めて提案されました。「技術の反復の加速と人間のライフ スタイルの変化は、私たちの歴史の流れを変えるようです。その後、重要な「特異点」がもたらされました。私たちが知っているように、それは何も続きません」そして世界はひっくり返るでしょう。
技術的特異点「バージョン 2.0」:
1993 年、コンピュータ科学者であり SF 作家のヴァーナー・ヴィンジは、「来るべき技術的特異点」という記事の中で、「技術的特異点」の到来は人類の時代の終わりの到来を告げるものであり、超知能は人類の必須条件であると述べました。新しい超知性体が自らをアップグレードし続け、信じられないほどの速度で技術進歩を遂げるため、「技術的特異点」が出現します。
技術的特異点「バージョン 3.0」:
2005 年、シンギュラリティ大学の創設者兼学長で Google のテクニカル ディレクターであるレイ カーツワイルは、著書「The Singularity Is Near」の中で「技術的特異点」の概念を再調整しましたが、これも私たちがよく知っている概念に近く、タイムは技術的特異点が 2045 年に現れると予測しました。同氏は「技術的特異点」とは、急速かつ広範囲にわたる技術変化が将来人類生活にもたらす不可逆的な変化を指し、主に人工知能の急速な発展を指すと考えている。特異点により、私たちは生体や脳の限界を超え、将来的には人間と機械の区別がなくなるでしょう。
技術的特異点「バージョン 4.0」:
2013年、オックスフォード大学人類未来研究所の主任研究員であるアンダース・サンドバーグ氏は、このような技術の発展や変化を「技術的特異点」と呼ぶ「技術的特異点」の範囲を拡大しました。
GPT ユーザーは仲間を夢見ていますか?
2022 年 11 月 30 日、OpenAI は、会話型インターフェイスおよび大規模言語モデルである ChatGPT をリリースしました。多くの人にとって、これは革命的な瞬間です。その出力は素晴らしく、時間を節約でき、答えは説得力のある真実です (OpenAI が答えても安全だと判断した場合)。

分野の専門家による数分間の検討やオンライン フォーラムでの数時間の議論が必要だったであろう答えを、今日 LLM を使用すると数秒で得ることができるのは注目に値します。
チャットボットは常に人々が切望するパートナーでした。チューリング テストの背後にある動機は、没入感を壊さないチャットボットを求めることかもしれません。
まだ試されていないのは、社会的動物としての人間をデジタル脳で強化できるかどうかです。私たちは一緒に狩りをし、一緒に農作業をし、産業規模の機械の管理者やオペレーターの広大な緩衝地帯とも言える社会は、これまで以上に社会的になっています。
人間は最も抵抗の少ない道を最適化し、批判的思考と度重なる失敗を通じて得たさまざまな知識を複製するか「グーグル」するかを選択します。 ChatGPT の出現: 学生は LLM を使用してレポートを作成し、良い成績を得ることができます。 Stack Overflow は個人的な利益のために Sybil 攻撃を受ける可能性があり、視聴者 (プログラマー) はどういうわけかディープフェイクの交響曲に従うかもしれません。スクリプトキディは、ChatGPT がマルウェアであることを示している可能性があります。 LLM の主流の使用は、特に健全で効果的で多様な思考の点で、私たちの生産性を損なうものなのでしょうか?
特異点以前の最後の人形遣い
AI が与えることができる最も大きな影響は、人的資本の配分の文化にあります。最近の意見は、ChatGPT に対する反応をうまく説明しています。
最も幸せなのは、マシンが明らかに書くという仕事をこなしていることを発見して唖然とした人たちだ。
これまでのところ、すべてが予想通りです。歴史を振り返ると、人々は新しい通信テクノロジーの短期的な影響を過大評価し、長期的な影響を大幅に過小評価することがよくあります。印刷物、映画、ラジオ、テレビ、インターネットにも同じことが当てはまります。
AI の影響を理解しようとする際、私たちは短期的な混乱を切り分けて中長期的な影響を推測しようとします。
そうは言っても、この上昇を市場の力学を通して説明するのが適切かもしれません。 AI アシスタントは、コンテンツ作成の希少性を変革し、それによってある程度のマーケット メーカーとなります。ことわざの「魔神」が「ボトル」から出るたびに、消費者は市場の価格を変更し、最適ではない供給業者を段階的に廃止することで非対称的に利益を得ます。次に、AI ベースの生産のサプライヤーは、時間の経過とともにさらに多くの資本を蓄積しました。
トレーニング データセットを生成するためにインターネット全体をクロールする余裕のある企業が寡占していると主張する人もいるでしょう。おそらく、新しい ML モデルを生成するためにそのようなリソースを消費できる余裕のある SaaS は限られた数だけでしょう。 ML ベースのコマースが十分に不安定になると、PMF を達成して維持できる人が少なくなる可能性があります。過去に私たちは、HAL 9000、スカイネット、バトラー聖戦などの心理戦術に騙されてきました。
多くの企業とインテリジェント エージェントが AI 経済における希少性に協力しています。私たちの現在の資本主義社会が、社会経済階級や人権/財産権などの基本原則を段階的に廃止したり、何らかの形で大量破壊を加速したりする可能性のある、否定的なフィードバックのないテクノクラートを生み出す可能性はどのくらいありますか?
ありきたりに聞こえるかもしれませんが、社会の仕組みに根本的な影響を与える、注意すべき変曲点が今後到来します。今から 1 年後、誰かが特定の AI 依存製品に関する簡単な法案を作成したり、チューリップマニアになったりしているかもしれません。 5〜10年以内に、個人事業主経済、既存の政府形態、個人の自治/消費は清算されるでしょう。 「メガコープ」モデルは混乱の過程を通じて依然として支配的であり、私たちは「サイバー状態」、またはよりオーウェル的な状況に陥るかもしれません。それはすべて、コンピュータ(何らかの手段で入手したもの)が、私たちの自然言語の集合的使用を編集して、今日の社会の運営上および経済上の機能の多くを網羅するようになるからです。どのようなタイムラインであっても、これは「シンギュラリティ」のかなり前の明確な変曲点となるでしょう。
手法と技術
画像の説明
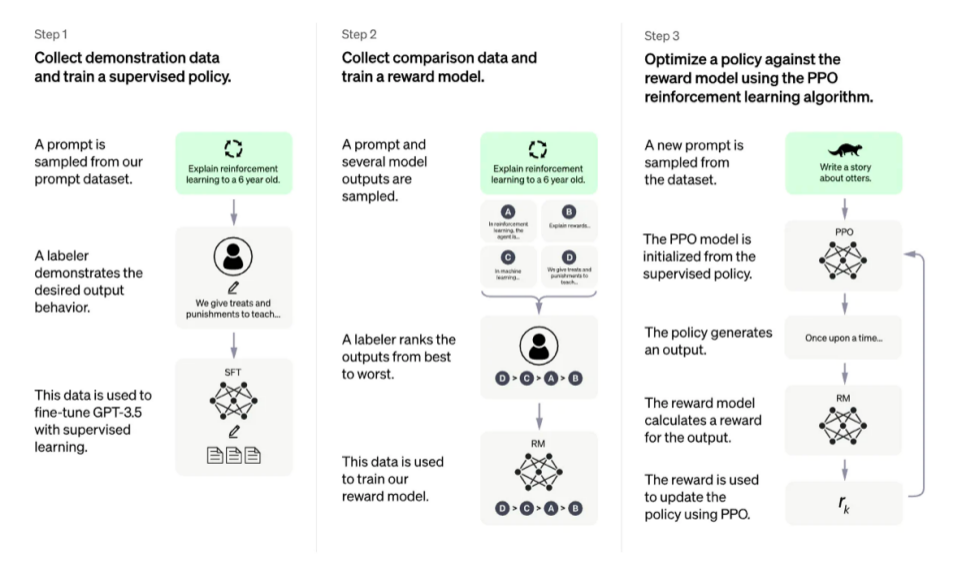
OpenAI の RLHF 図
ただし、NLP を「完璧にする」には課題があります。
これらのテクノロジーは非常に有望で影響力があり、人工知能の最大規模の研究機関の注目を集めていますが、明らかな限界があります。これらのモデルは、有害なテキストや実際には不正確なテキストを不確実性なく出力できます。この不完全さは、RLHF の長年の課題と推進力を表しています。本質的に人間の問題領域で動作するということは、モデルが完成としてマークされるために越えるべき明確なゴールラインが決して存在しないことを意味します。
RLHF を使用してシステムを導入する場合、人間の好みのデータの収集は、必須かつ意図的な人的要因によりコストがかかります。 RLHF のパフォーマンスは、人間による注釈の品質によって決まります。人間による注釈には、InstructGPT の開始 LM の微調整など人間が生成したテキストと、モデル出力間の人間が好むラベルの 2 種類があります。
特定のプロンプトに答えるための適切な人間によるテキストを生成するには、(製品ユーザーやクラウドソーシングに頼るのではなく) パートタイムの人を雇う必要があることが多いため、法外にコストがかかります。ありがたいことに、ほとんどの RLHF アプリケーションの報酬モデルをトレーニングするために使用されるデータ サイズ (約 50,000 のラベル付きプリファレンス サンプル) はそれほど高価ではありません。ただし、依然として学術研究室が支払える金額を超えています。
現在、RLHF には一般言語モデル (Anthropic の) に基づく大規模なデータセットが 1 つだけあり、タスク固有の小規模なデータセットがいくつか (OpenAI の概要データなど) あります。 RLHF データの課題は、アノテーターのバイアスです。何人かのヒューマン・アノテーターが同意しない場合があり、その結果、トレーニング・データに差異が生じる可能性があります。
RLHF は、自然言語処理 (NLP) を超えた機械学習に適用できます。たとえば、Deepmind はマルチモーダル エージェントへの使用を検討しました。同じ課題がこの場合にも当てはまります。
スケーラブルな強化学習 (RL) は、クエリコストが低い正確な報酬関数に依存しています。 RL を適用することができれば、人間の才能分布の極端な点に匹敵する AI を作成することができ、大きな成功を収めることができます (Silver et al., 2016; Vinyals et al., 2019)。ただし、この報酬関数は、人々が定期的に行う多くの無制限の行動についてはあまり知られていません。たとえば、誰かに「マグカップを近くに持ってください」と頼む日常的なやり取りを考えてみましょう。報酬モデルがそのようなインタラクションを適切に評価できるようにするには、自然言語でリクエストを行うさまざまな方法や、それを実行できる (または実行できない) さまざまな方法に対して堅牢であると同時に、堅牢である必要があります。変化の無関係な変数(カップの色)と言語の本質的な曖昧さ(「近い」とは何ですか?)の鈍感さ。
したがって、RL を通じてより広範な専門家レベルの機能を浸透させるには、人間の行動の複雑さ、変動性、曖昧さを考慮した、正確でクエリ可能な報酬関数を生成する方法が必要です。報酬関数をプログラミングする代わりに、機械学習を使用して報酬関数を構築することが 1 つのオプションです。報酬イベントを予測して正式に定義しようとする代わりに、人間に状況を評価して、報酬関数を学習するための教師付き情報を提供するように依頼できます。人間がそのような判断を自然に、直感的に、そして迅速に提供できる状況では、そのような学習報酬モデルを使用した RL はエージェントを効果的に改善できます (Christiano et al., 2017; Ibarz et al., 2018; Stiennon et al., 2020 Year;)
シンギュラリティを引き起こす要因の多くはまだ開発されていませんが、それらが何であるかを、実装にかかる時間枠よりも確実に判断できます。 Chris Lattner 氏は、POV から「まばらにゲートされた専門家の構成」について言及しました。
簡単に説明すると、おそらく、多くの「専門家」の意見をキュレーションして組み合わせる仲介者が存在するのでしょう。
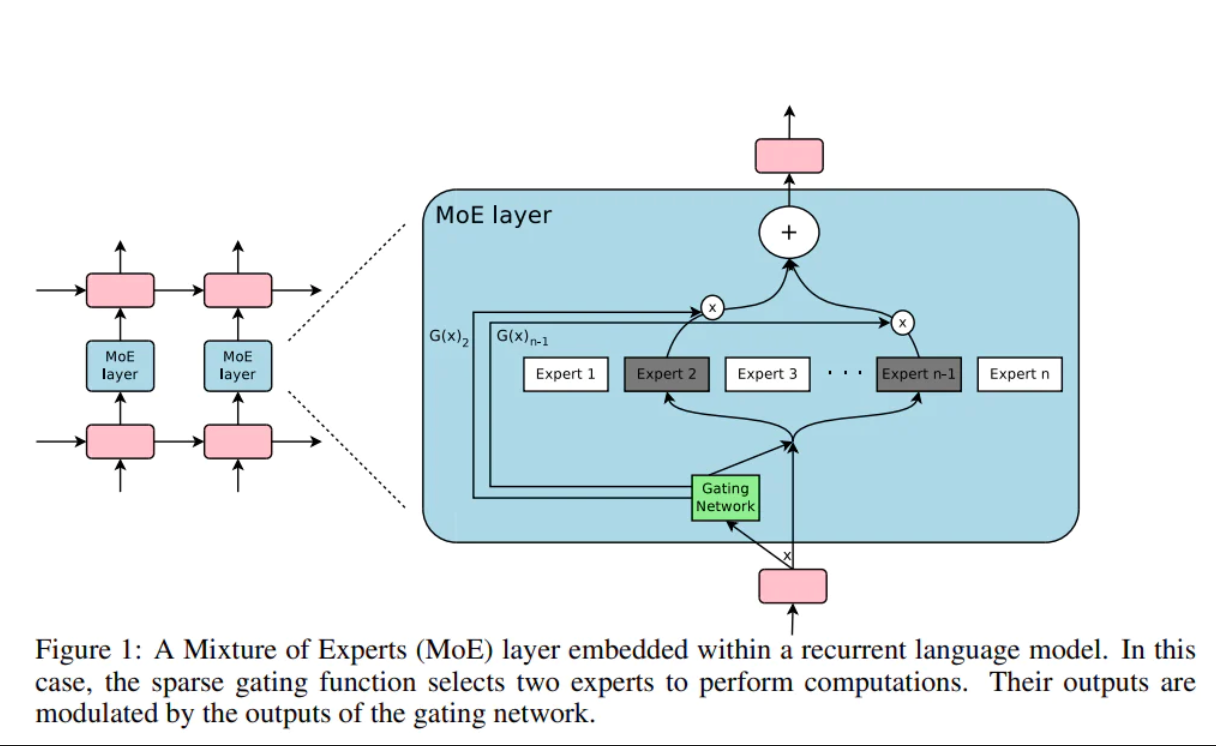
これにより、さらなる研究のための幅広い設計スペースが提供されます。おそらく中間層は別の選択をすべきだったのでしょう。
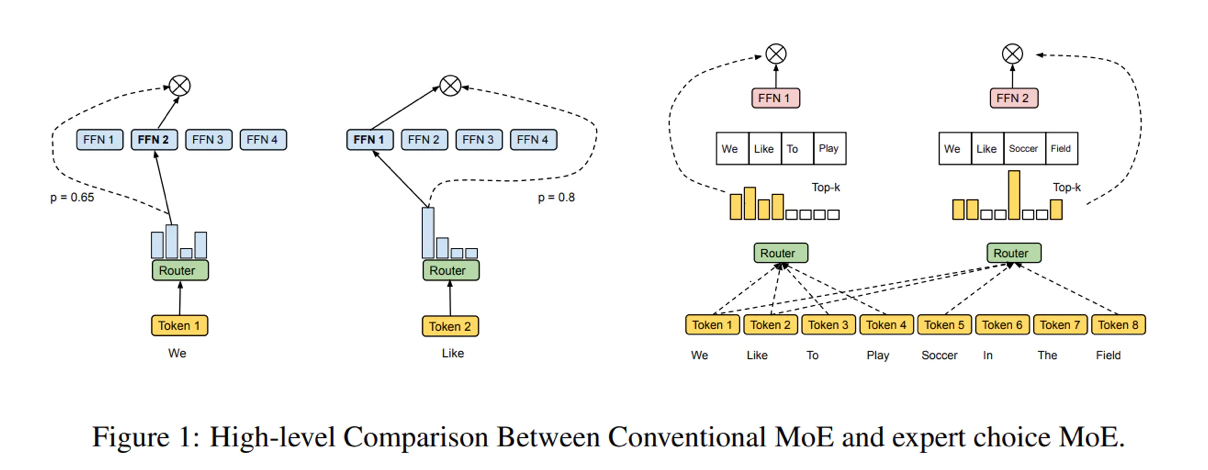
たとえば、空間データを使用します。
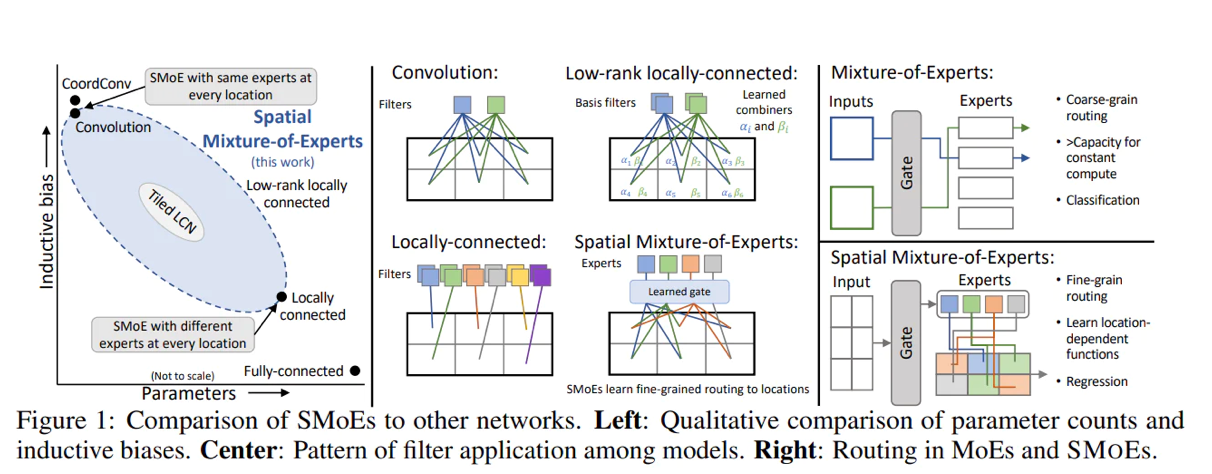
画像の説明
文章
文章
製造業からのフィードバックは良好ですが、最も大きなニーズがあるのは医療分野です。現在、当社は小売用バイオセンサーを早期に導入しています。時間の経過とともに、準同型暗号により機械学習が膨大な量の健康データを活用できるようになるでしょう。私たちは何万年もの間、薬物消費をクラウドソーシングしてきましたが、任意の量の物質を任意の期間にわたって投与できる人工知能とどのように共存するかはまだわかりません。同時に、準同型暗号化は効率の問題からまだ使用されていません。
Google Brain は Robotics Transformer-1 をリリースしました。最初のリリースでは、単純なタスクを実行するアームにすぎない可能性がありますが、一般的なビルド環境でよりトークン化された操作を反復することが可能であることは明らかです。世界経済は貨物を中心に成り立っているため、現在世界中に約6,000隻ある「ゼロエミッション」コンテナ船が100隻以上もそのような施設で建造されることになるのは当然だろう。また、都市計画条例が完全な効力を発揮できる住宅危機においては、大きな流れの変化となるだろう。
さらに、AGI 能力の開発のための 12 の合理的なステップであるアルバータ州計画についても触れなければなりません。
「ロードマップ」という用語は、直線的なパス、つまり順番に実行し通過する一連のステップを描くことを意味します。それは完全に間違っているわけではありませんが、研究の不確実性と機会を認識していません。以下に概説する手順には、最初から最後まで一連の手順ではなく、複数の相互依存関係があります。ロードマップは自然な順序を示唆していますが、実践はこの順序から逸脱することがよくあります。任意のステップに入力またはアタッチすることで、有用な研究を行うことができます。一例として、私たちの多くは最近、統合アーキテクチャにおいて興味深い進歩を遂げていますが、これらの進歩はシーケンスの最後のステップでのみ現れました。
まず、ロードマップとその理論的根拠についての一般的なアイデアを理解してみましょう。次のようなタイトルの 12 のステップがあります。
1. 表現 I: 与えられた特徴による継続的な教師あり学習。 2. 表現 II: 教師あり特徴検出。 3. 予測 1: 継続的一般化価値関数 (GVF) 予測学習。 4. コントロール I: 継続的なアクターと批評家のコントロール。 5. 予測 2: 平均報酬 GVF 学習。 6. コントロール II: 現在進行中のコントロールの問題。 7. プラン I: 同等の報酬を得るプラン。 8. Prototype-AI I: 連続関数近似によるモデルベースのワンステップ強化学習。 9. プラン II: 検索制御と探索。 10. Prototype-AI II: STOMP プロセス。 11. Prototype-AI III: オーク。 12. プロトタイプ-IA: インテリジェントな増幅。
これらのステップは、コア機能 (表現、予測、計画、制御) の新しいアルゴリズムの開発から、これらのアルゴリズムを組み合わせて継続的なモデルベース AI の完全なプロトタイプ システムを作成するまで進みます。
画像の説明

ChatGPTの出力
「指数関数的な進歩」
上で説明したアルバータ州の計画は理想的な状況です。人間は、スパース ニューラル ネットワーク ツールを使用する個人として、また自己組織化、社会学習、および環境工学の特性を備えたグループとして、すでに複雑です。暗号化と分散 (敵対的) コンピューティングの最近の発展では、人間はチューリング完全なグローバル状態 (歴史) を維持できる程度にのみ自律的になっています。メカニカルタークとして知られる現象もあります。重要なのは、AI 製品はどのような期間でも減少し、同時期の AI ツールと検証可能な作業によって強化された、調整された実行によって既存のレベルを上回るパフォーマンスを発揮できる成熟した開発者エコシステムが存在するということです。
これは、現在の思考実験につながります。「The Singularity™ の前に、予測されるすべての変曲点を達成する必要があるのか?」商用モデルのトレーニングにおける独自の改善には、それをパブリック ドメインで実装する実行可能な方法がある可能性があります。 StableDiffusion は、このコンセプトに関する会話を引き起こしました。クラウドソーシングは過去 10 年間で十分に加速しており (Twitch Plays Pokémon、ソーシャル ネットワーク、The DAO が証明しているように)、特異点はすでに気を散らすものになっています。イーサリアムのスケーリング ソリューションが zk-SNARK のような暗号化を使用してネットワークのインフラストラクチャのニーズを削減しようとしているのと同じように、私たちは既存の大企業が総当たり攻撃を行って AI を収益化する必要性を削減する軽量ソリューションの実装を試みます。
実際、OpenAI モデルに反論する最良の方法の 1 つは、金融市場やソーシャル ネットワークにおける同様のソーシャル キャピタル システムの動作はある程度予測可能であるということです。 Twitter がニュースを集約するのは、そのユーザーが正当な人物を使って世界中にニュースをブロードキャストし、増幅させることができるからです。新型コロナウイルスのロックダウンや中央銀行の金融政策などの世界的な傾向により、成長株は急激に上下する可能性がある。 AI のような PMF を自己調整し、自己調整するコミュニティとして短時間で実現できるスタートアップを想像するのに、それほど想像力は必要ありません。潜在的に数千億ドルの運営コストがかかる可能性があり、既存のテクノロジーとさらなる事業開発を通じて、多くのセクターにわたってそのコストを解放できる可能性があります。
テレビ シリーズ「ウエストワールド」では、レハブアムと呼ばれる人工知能システムが、大規模なデータ セットを分析して操作し、未来を予測することで人類の情勢に秩序をもたらします。産業革命以来、破壊的イノベーションは官僚機構の外で繰り返し出現しており、現在ではその発生率が増加しています。ここ数十年でパブリックドメインの深さと範囲は拡大しており、多くのテクノロジーは、それがどれほど商業的であっても、オープンソース化を余儀なくされています。





