原題:「ChatGPT の台頭を見る GPT-1 から GPT-4 まで」
原著者: Alpha Rabbit 研究ノート
副題
ChatGPTとは何ですか?
最近、OpenAI が対話形式で対話できるモデルである ChatGPT をリリースし、そのインテリジェントさから多くのユーザーに歓迎されています。 ChatGPT は、以前 OpenAI によってリリースされた InstructGPT の親戚でもあり、ChatGPT モデルはおそらく RLHF (ヒューマン フィードバックによる強化学習) を使用してトレーニングされています。副題
GPTとは何ですか? GPT-1からGPT-3へ
Generative Pre-trained Transformer (GPT) は、インターネット上で利用可能なデータでトレーニングされたテキスト生成用の深層学習モデルです。質問応答、テキスト要約、機械翻訳、分類、コード生成、会話型 AI に使用されます。
2018年はGPT-1が誕生し、NLP(自然言語処理)の事前学習モデルの元年でもあります。パフォーマンスの点では、GPT-1 は一定の汎化能力を備えており、監視タスクとは関係のない NLP タスクで使用できます。その一般的なタスクは次のとおりです。
自然言語推論: 2 つの文間の関係を判断します (含む、矛盾する、中立)
質問応答と常識的推論: 記事といくつかの回答を入力し、回答の正確さを出力します。
意味的類似性の認識: 2 つの文の意味が関連しているかどうかを判断します。
GPT-1 は調整されていないタスクにはある程度の効果がありますが、一般化能力は微調整された教師ありタスクに比べてはるかに低いため、GPT-1 は会話ツールというよりはかなり優れた言語理解ツールとしか見なされません。
GPT-1 は調整されていないタスクにはある程度の効果がありますが、一般化能力は微調整された教師ありタスクに比べてはるかに低いため、GPT-1 は会話ツールというよりはかなり優れた言語理解ツールとしか見なされません。
GPT-2 も予定通り 2019 年に登場しました。ただし、GPT-2 は元のネットワークにあまり多くの構造革新や設計を実行せず、より多くのネットワーク パラメーターとより大きなデータ セットを使用しただけでした。パラメータ量は 15 億で、学習目標では教師ありタスクの教師なし事前トレーニング モデルを使用します。理解に加えてパフォーマンスの面でも、GPT-2 は世代の観点から初めて優れた才能を示しました。概要を読んだり、チャットしたり、書き続けたり、ストーリーをでっち上げたり、さらにはフェイク ニュース、フィッシング メール、役割を生成したりすることもできます。 -オンラインプレイ 問題ありません。「大きくなった」後、GPT-2 は一般的で強力な能力を示し、複数の特定の言語モデリング タスクで当時最高のパフォーマンスを達成しました。
後、GPT-3 は、自然言語処理のほとんどのタスクをほぼ完了できる教師なしモデル (現在では自己教師ありモデルと呼ばれることが多い) として登場しました。例には、質問指向の検索、読解、意味推論、機械翻訳、記事生成、自動質問応答などが含まれます。さらに、このモデルは、フランス語から英語、ドイツ語から英語の機械翻訳タスクなどの最先端のタスクに優れており、自動生成された記事は人間か機械かほとんど区別がつきません(正解率はわずか 52% で、ランダムな推測に匹敵します)。 、そしてさらに驚くべきことに、2 桁の加算と減算のタスクではほぼ 100% の正しさを達成しており、タスクの説明に基づいてコードを自動的に生成することもできます。教師なしモデルは多くの機能を備え、うまく機能するため、人々は一般的な人工知能への期待を感じているようですが、これが GPT-3 がこれほど大きな影響を与えた主な理由かもしれません
GPT-3 モデルとは一体何ですか?
実際、GPT-3 は単純な統計言語モデルです。機械学習の観点から見ると、言語モデルとは単語列の確率分布をモデル化したもの、つまり発話された断片を条件として、次の瞬間に異なる単語が出現する確率分布を予測するものです。一方で、言語モデルは、文が言語文法にどの程度準拠しているかを測定することができます (たとえば、人間とコンピューターの対話システムによって自動的に生成された応答が自然でスムーズであるかどうかを測定するために)。新しい文を予測して生成するために使用されます。たとえば、「正午 12 時です、一緒にレストランに行きましょう」というセグメントの場合、言語モデルは「レストラン」の後に出現する可能性のある単語を予測できます。一般的な言語モデルは、次の単語が「食べる」であると予測します。また、強力な言語モデルは、時間情報を取得して、コンテキストに適合する単語「ランチを食べる」を予測できます。
一般に、言語モデルが強力であるかどうかは、主に 2 つの点に依存します: まず、モデルがすべての歴史的コンテキスト情報を使用できるかどうか. 上記の例で、「正午 12 時」という長距離の意味情報を取得できない場合、言語モデルを予測することはほとんど不可能です。「昼食を食べる」という一言です。第二に、モデルが学習するのに十分な豊富な歴史的コンテキストがあるかどうか、つまりトレーニング コーパスが十分に充実しているかどうかにも依存します。言語モデルは自己教師あり学習に属するため、最適化の目標は、表示されるテキストの言語モデルの確率を最大化することであり、ラベルを付けずにあらゆるテキストをトレーニング データとして使用できます。
GPT-3 のより強力なパフォーマンスと大幅に多くのパラメーターにより、より多くのトピック テキストが含まれており、前世代の GPT-2 よりも明らかに優れています。これまでで最大の高密度ニューラル ネットワークである GPT-3 は、Web ページの説明を対応するコードに変換し、人間の物語を模倣し、カスタム詩を作成し、ゲーム スクリプトを生成し、人生の真の意味を予測する故哲学者を模倣することさえできます。また、GPT-3 は文法上の困難に対処するという点で微調整を必要とせず、必要なのは出力タイプのいくつかのサンプル (少量の学習) だけです。 GPT-3 は、言語専門家にとって私たちの想像力をすべて満たしてくれたと言えます。
注:上記は主に以下の記事を参照しています。
1. GPT 4 のリリースは人間の脳に匹敵するものであり、サークル内の多くの有力者が黙ってはいられないのです。 -Xu Jiecheng、Yun Zhao-Public Account 51 CTO Technology Stack-2022-11-24 18:08
2. この記事は、GPT-3 についてのあなたの好奇心に答えます! GPT-3とは何ですか?なぜそんなに良いと言えるのですか? -Zhang Jiajun、中国科学院オートメーション研究所、北京で公開 2020-11-11 17:25
副題
GPT-3の何が問題なのでしょうか?
しかし、GTP-3は完璧ではなく、人々が人工知能に関して最も懸念している主な問題の1つは、チャットボットやテキスト生成ツールがインターネット上のすべてのテキストをその品質や品質に関係なく学習し、間違った、悪意を持って不快なメッセージを生成する可能性があることです。 、または攻撃的な言語出力さえも、次のアプリケーションに完全に影響を与えます。
画像の説明
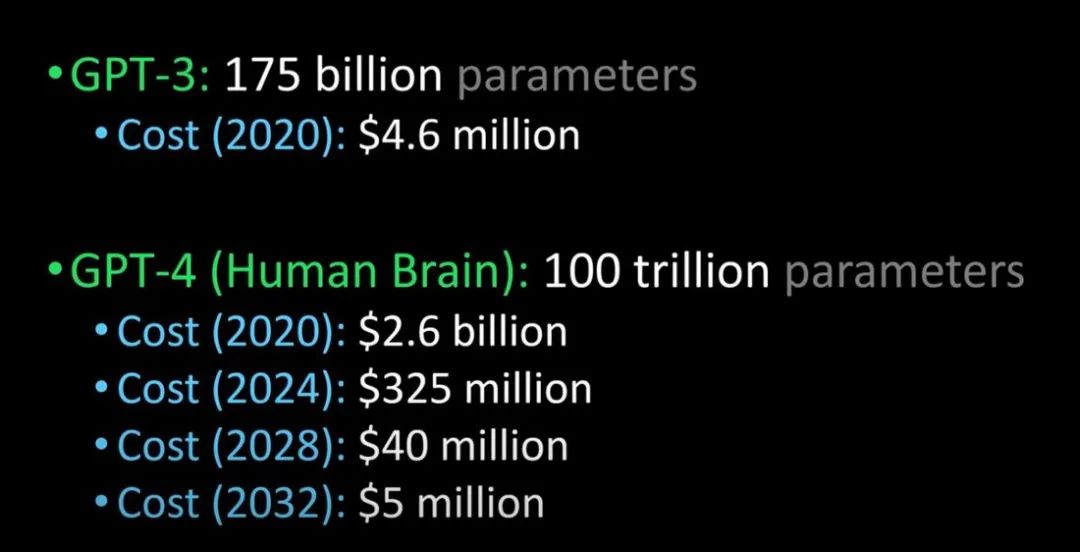
人間の脳である GPT-3 と GPT-4 の比較 (画像クレジット: Lex Fridman @youtube)
来年リリースされると言われているGPT-4は、チューリングテストをパスし、人間と見分けがつかないほど高性能で、企業の導入コストも大幅に下がるとのこと。
副題
ChatGPT と InstructGPT
Chatgpt については、その「前身」である InstructGPT について話しましょう。
副題
InstructGPT はどのように機能しますか?
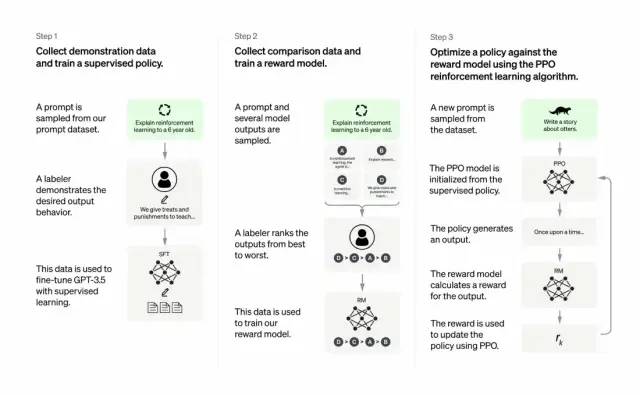
開発者は、教師あり学習と人間のフィードバックからの強化学習を組み合わせてこれを行います。 GPT-3の出力品質を向上させます。このタイプの学習では、人間がモデルの潜在的な出力をランク付けし、強化学習アルゴリズムが、より高いレベルの出力に似た素材を生成したモデルに報酬を与えます。
トレーニング データセットは、プロンプトの作成から始まります。プロンプトの一部は、「カエルについての話をしてください」や「数年以内に 6 歳児に月面着陸について説明してください」など、GPT-3 ユーザーからの入力に基づいています。文」。
開発者はプロンプトを 3 つの部分に分割し、各部分に対して異なる応答を作成します。
人間のライターは最初の一連のプロンプトに応答します。開発者は、トレーニング済み GPT-3 を微調整して、各プロンプトに対する既存の応答を生成する InstructGPT に変換しました。
次のステップは、より良い応答に対してより高い報酬を与えるようにモデルをトレーニングすることです。 2 番目のキューセットでは、最適化されたモデルは複数の応答を生成します。人間の評価者が各回答をランク付けします。プロンプトと 2 つの応答が与えられた場合、報酬モデル (別の事前トレーニング済み GPT-3) は、高評価の応答に対してはより高い報酬を計算し、低評価の応答に対してはより低い報酬を計算することを学習しました。
開発者は、3 番目のヒント セットと Proximal Policy Optimization (PPO) と呼ばれる強化学習手法を使用して、言語モデルをさらに微調整しました。プロンプトが出されると、言語モデルは応答を生成し、報酬モデルはそれに応じて報酬を与えます。 PPO は報酬を使用して言語モデルを更新します。
この段落の参照: The Batch: 329 | InstructGPT、よりフレンドリーで優しい言語モデル - パブリック アカウント DeeplearningAI- 2022-02-07 12:30
どこが重要ですか?核心は次のとおりです - 人工知能は責任ある人工知能である必要がある
OpenAI の言語モデルは、教育、仮想セラピスト、ライティング補助、ロールプレイング ゲームなどの分野に役立ちます。これらの分野では、社会的偏見、誤った情報、有害な情報の存在がさらに問題であり、これらの欠陥を回避できるシステムは、より有能で有用です。
Chatgpt と InstructGPT のトレーニング プロセスの違いは何ですか?
全体として、Chatgpt は、上記の InstructGPT と同様に、RLHF (ヒューマン フィードバックからの強化学習) を使用してトレーニングされます。違いは、トレーニング (および収集) 用にデータがどのように設定されるかです。(ここで説明します: 以前の InstructGPT モデルは 1 つの入力に対して出力を与え、それをトレーニング データと比較しました。それが正しければ報酬があり、間違っていれば罰が与えられます。現在の Chatgpt は 1 つの入力です, モデルは複数の出力を与え、その後人々は出力結果を並べ替えて、モデルにこれらの結果を「より人間らしいもの」から「ナンセンスなもの」まで並べ替えさせ、人間が並べ替える方法をモデルに学習させます。この戦略は教師あり学習と呼ばれます。この段落については Zhang Zijian 博士に感謝します)
ChatGPT の制限は何ですか?
次のように:
a) トレーニングの強化学習 (RL) フェーズでは、質問に答えるための、真実の特定の情報源や質問に対する標準的な回答はありません。
b) トレーニングされたモデルはより慎重であり、回答を拒否する場合があります (ヒントの誤検知を避けるため)。
c) 教師ありトレーニングでは、モデルがランダムな応答セットを生成し、人間のレビュー担当者だけが良い/上位ランクの応答を選択するのではなく、理想的な答えを知る方向にモデルを誤解させたりバイアスを与えたりする可能性があります。
参考文献:
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers:
a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training.
b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts).
c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.
参考文献:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 のリリースは人間の脳に匹敵するものであり、サークル内の多くの有力者が黙ってはいられないのです。 -Xu Jiecheng、Yun Zhao-Public Account 51 CTO Technology Stack-2022-11-24 18:08
5. この記事は GPT-3 についてのあなたの好奇心に答えます! GPT-3とは何ですか?なぜそんなに良いと言えるのですか? -Zhang Jiajun、中国科学院オートメーション研究所、北京で公開 2020-11-11 17:25
元のリンク





