原文翻訳:ティア
原文翻訳:ティア
画像の説明
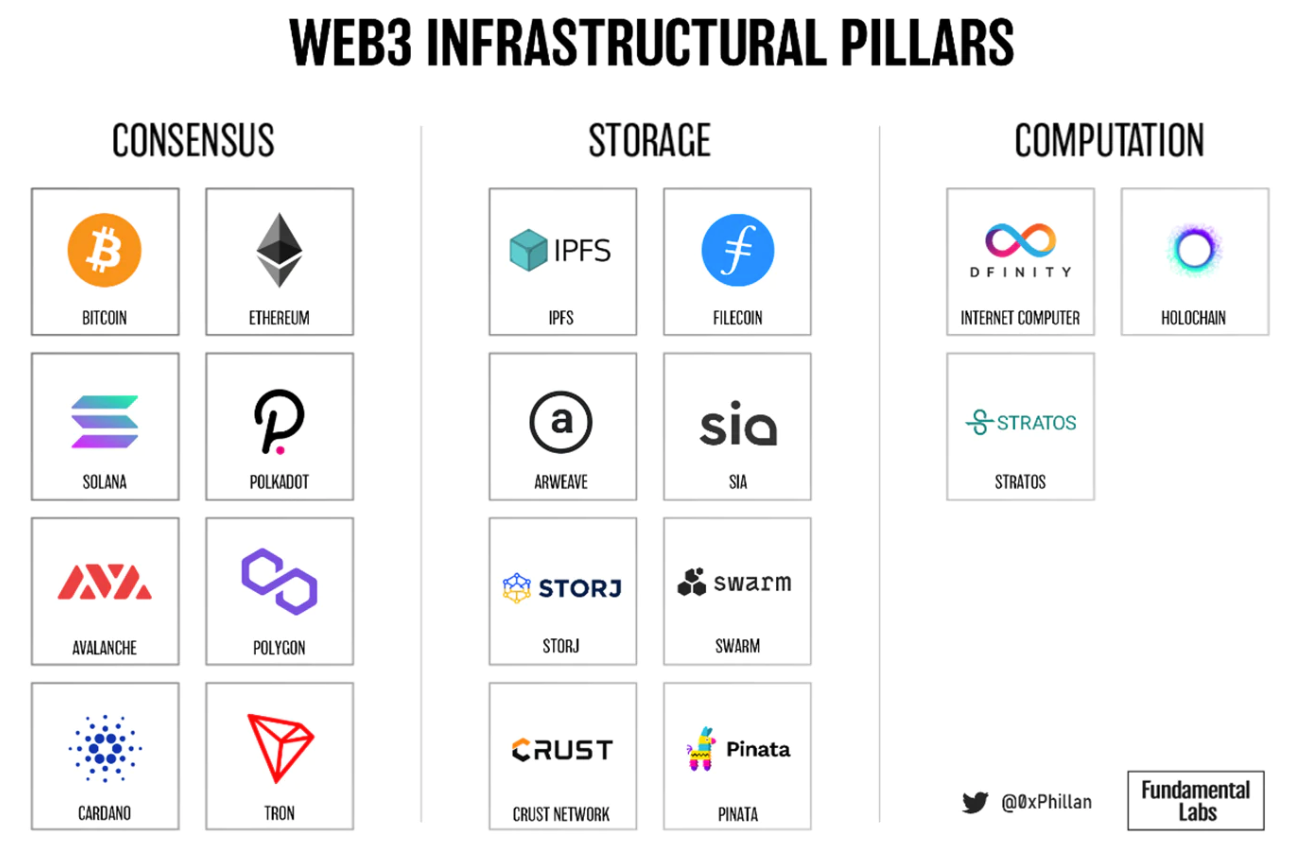
図 1: Web3 の各柱のプロジェクト例
第 2 の柱であるストレージは急速に成熟しており、利用シーンに合わせてさまざまなストレージ ソリューションが適用されています。この記事では、分散ストレージの柱についてさらに詳しく説明します。
そしてArweaveそしてCrust Networkダウンロード。
分散ストレージの必要性
ブロックチェーンの視点
ブロックチェーンの観点から見ると、ブロックチェーン自体は大量のデータを保存するように設計されていないため、分散ストレージが必要です。ブロックのコンセンサスを取得するメカニズムは、ブロック (コレクション トランザクション) に配置され、ノード検証のためにネットワークに迅速に共有される少量のデータ (トランザクション) に依存しています。
画像の説明
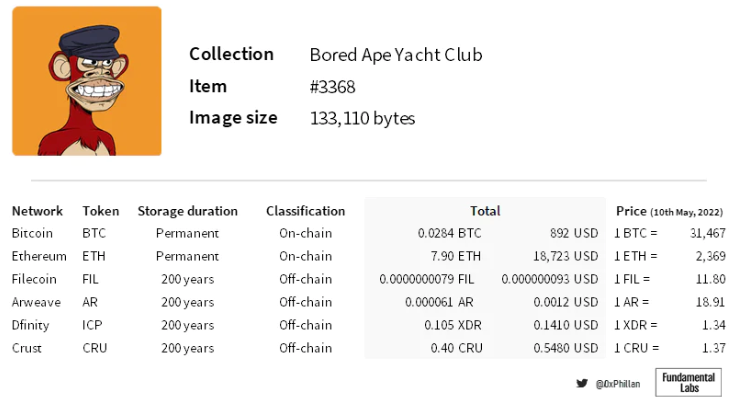
図 2: メインネットがアクティブなプロジェクト。 Arweave の永続性の定義を満たすために、200 年の保存期間が選択されました。出典: Web ドキュメント、Arweave ストレージ計算ツール
第二に、これらのブロックに大量の裁定データを保存したい場合、ネットワークの混雑が深刻になり、ネットワーク使用時にガス戦争が発生し、価格が上昇する可能性があります。これはブロックの暗黙的な時間値の結果であり、ユーザーが特定の時間にトランザクションをネットワークに送信する必要がある場合、トランザクションを優先させるために追加のガス料金を支払う必要があります。
したがって、NFTメタデータと画像データ、およびdAppのフロントエンドをオフチェーンに保存することをお勧めします。
集中型ネットワークの視点
データをオンチェーンに保存するのが非常に高価であるなら、なぜそれを集中ネットワークのオフチェーンに保存しないのでしょうか?
集中型ネットワークは検閲や変動の影響を受けやすいです。このため、ユーザーはデータのセキュリティを維持するためにデータプロバイダーを信頼する必要があります。集中型ネットワークの運営者がユーザーの信頼に真に応えられるという保証はありません。データは意図的に、または偶然に消去される可能性があります。たとえば、データ プロバイダーのポリシーの変更、ハードウェアの障害、または第三者による攻撃が原因である可能性があります。
NFTs
画像の説明
図 3: 前回の販売に基づいた Crypto Punk の最低価格 (執筆時点では最低価格なし)、Crypto Punk のイメージ サイズは Crypto Punks V2 チェーンのバイト文字列のバイト長に基づいています。 2022 年 5 月 10 日現在のデータ。出典: OpenSea、オンチェーン データ、IPFS メタデータ
画像の説明
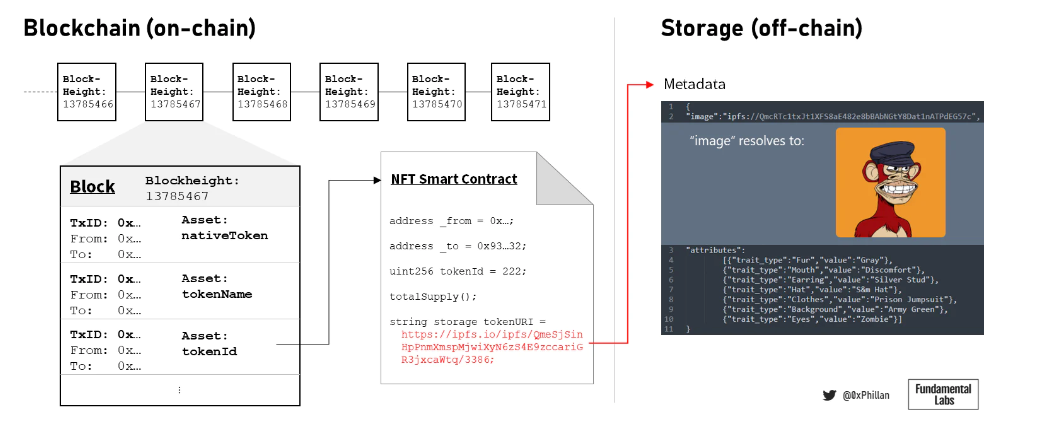
図 4: ブロックチェーン、ブロック、NFT、オフチェーン メタデータの簡略図
おそらく、NFTの価値は主に、NFTが参照するメタデータや画像データによって決まるのではなく、むしろコレクションを推進する動きやエコシステムコミュニティによって左右されます。これは真実かもしれませんが、基礎となるデータがなければNFTは無意味であり、意味のないコミュニティは形成できません。
NFT は、プロフィール写真やアート コレクションに加えて、不動産や金融商品などの現実世界の資産の所有権を表すこともできます。このようなデータの外部の実世界の値に加えて、その値は NFT によって表されるため、NFT に保存されたデータの各バイトの値はチェーン上の NFT の値を下回ることはありません。
dApps
画像の説明
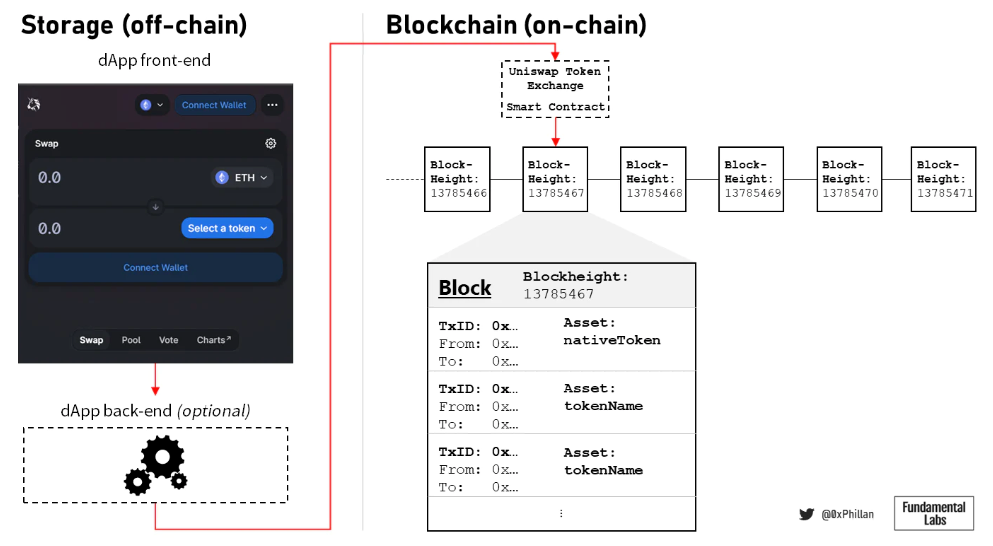
図 5: ブロックチェーンと対話する dApp の簡略図
画像の説明
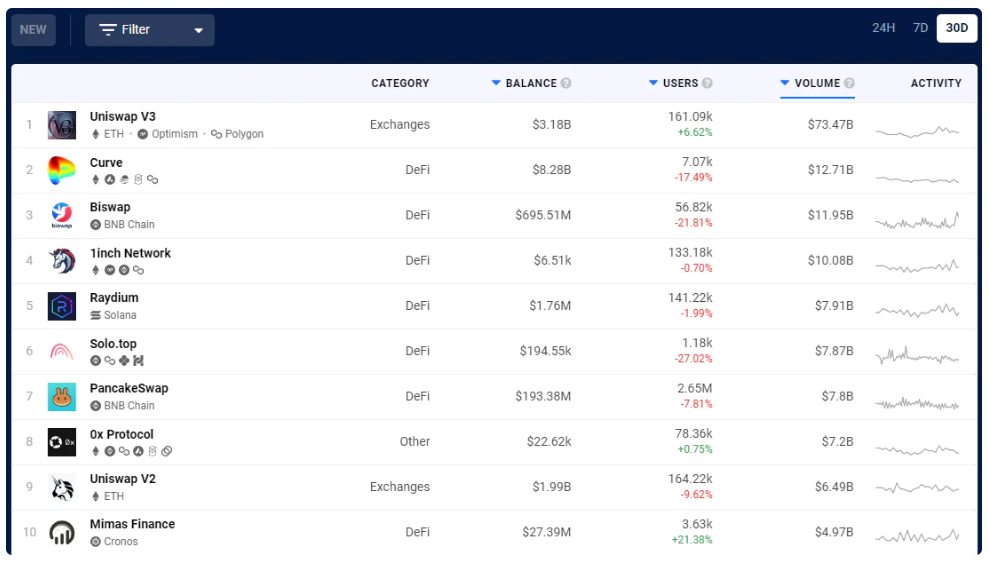
図 6: 2022 年 5 月 11 日時点で DappRadar によって報告された、USD ボリューム別の最も人気のある dApps
画像の説明
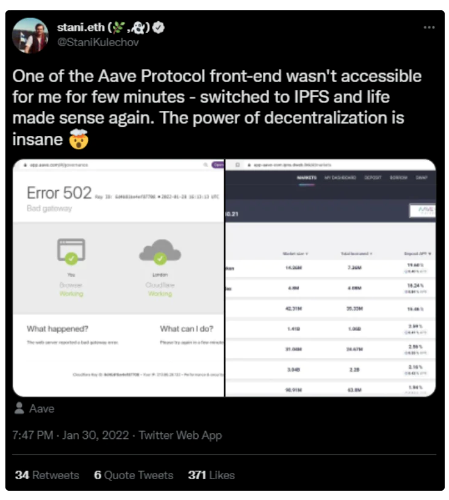
図 7: Aave 創設者 Stani Kulechov 氏は、Aave dApp フロントエンドは 2022 年 1 月 20 日にオフラインになるが、IPFS でホストされる Web サイトのコピーを介して引き続きアクセスできるとツイートしました。
分散ストレージにより、サーバー障害、DNS ハッキング、および dApp フロントエンドへのアクセスを削除する集中型エンティティが軽減されます。 dApp の開発が停止された場合でも、フロントエンドを通じてスマート コントラクトにアクセスし続けることができます。
分散型ストレージの状況
画像の説明
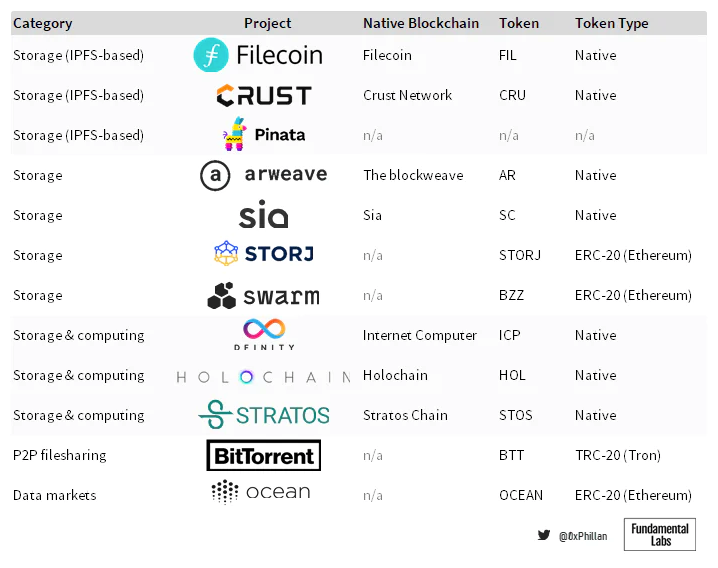
図 8: 任意に選択されたいくつかの分散ストレージ プロトコルの概要 (すべてではありません)
多くの違いがあるにもかかわらず、上記のすべてのプロジェクトには 1 つの共通点があります。それは、ビットコインやイーサリアムのブロックチェーンの場合のように、すべてのノード上のすべてのデータを複製するネットワークは存在しないということです。分散ストレージ ネットワークでは、ビットコインやイーサリアムの場合のように、連続的にリンクされたデータを保存および検証するほとんどのネットワークでは、保存されたデータの不変性と可用性が実現されません。ただし、前述したように、多くのネットワークはストレージの注文を追跡するためにブロックチェーンの使用を選択しています。
分散ストレージ ネットワーク上のすべてのノードがすべてのデータを保存することは持続不可能です。ネットワークを実行する間接コストによってユーザーのストレージ コストが急速に増加し、最終的にはネットワークの集中化が余裕のある少数のノードに進むためです。ハードウェアコスト、ノードオペレーター。
したがって、分散型ストレージ ネットワークは並外れた課題を克服する必要があります。
分散型ストレージの課題
オンチェーン データ ストレージに関する前述の制限を検討すると、分散ストレージ ネットワークは、データが永続的、不変、アクセス可能な状態を維持しながら、ネットワークの値転送メカニズムに影響を与えない方法でデータを保存する必要があることは明らかです。本質的に、分散型ストレージ ネットワークは、分散型システムに対する不信感を維持しながら、ネットワーク内のすべての参加者がストレージと取得の作業に対してインセンティブを確実に得られるようにしながら、データの保存、データの取得、およびデータの保守ができなければなりません。
これらの課題は次のような質問として要約できます。
データストレージ形式: 完全なファイルを保存しますか?それともファイルの断片を保存しますか?
データ レプリケーション: データ (完全なファイルまたはフラグメント) を保存するノードの数はどれくらいですか?
ストレージ追跡: ネットワークはどのようにしてファイルを取得する場所を知るのでしょうか?
保存されたデータの証明: ノードは保存するよう求められたデータを保存していますか?
長期間にわたるデータの可用性: データは長期間にわたって保存され続けますか?
ストレージの価格調査: ストレージのコストはどのように決定されますか?
永続的なデータの冗長性: ノードがネットワークから離脱した場合、ネットワークはどのようにしてデータがまだ利用可能であることを確認するのでしょうか?
データ転送: ネットワーク帯域幅には代償が伴います。要求されたときにノードが確実にデータを取得できるようにするにはどうすればよいでしょうか?
ネットワーク トークンの経済学: ネットワーク上でデータが利用可能であることを保証することに加えて、ネットワークはどのようにしてネットワークの長期的な存在を保証できるでしょうか?
画像の説明
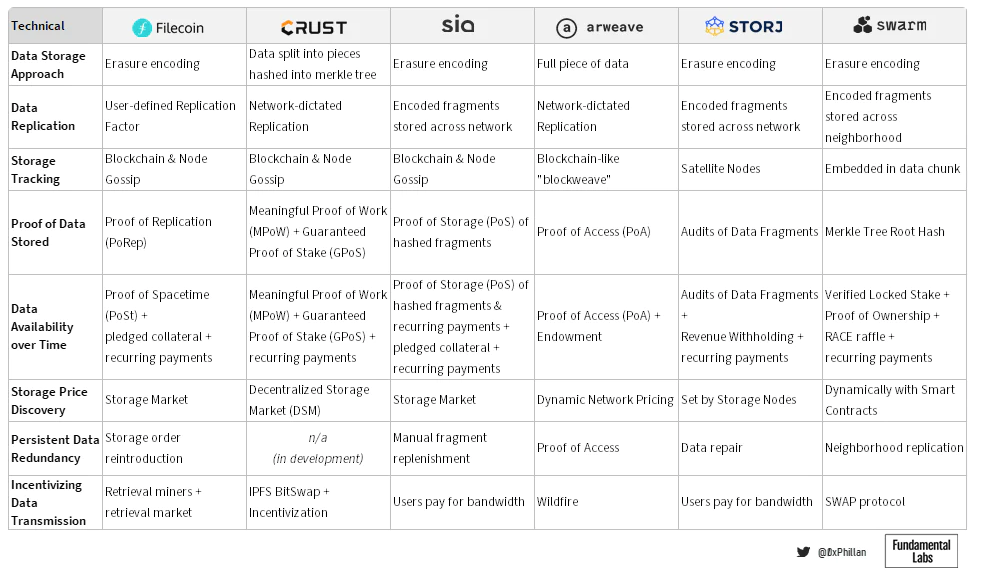
図 9: 監査済みストレージ ネットワークに関する技術設計上の決定の概要
またはArweaveまたはCrust Network研究論文全文をお読みください。
画像の説明
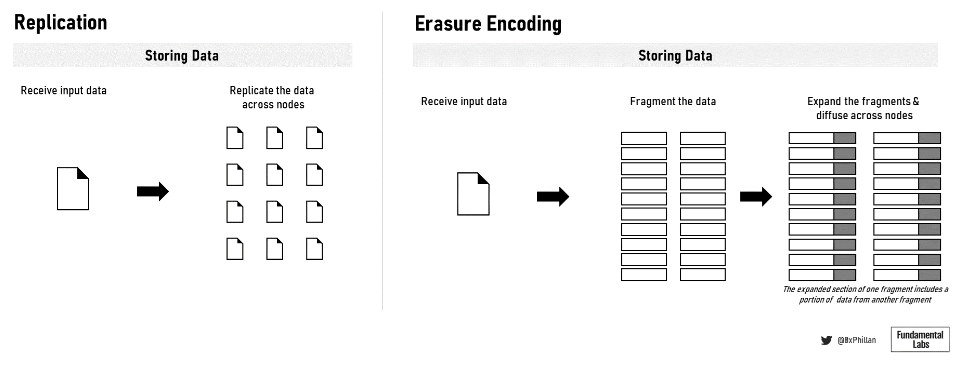
図 10: データ複製とイレイジャーコーディング
これらのネットワークでは、ネットワーク上にデータを保存するために主に 2 つの方法が使用されます。それは完全なファイルの保存と消去コーディングの使用です。Arweave と Crust Network は完全なファイルを保存しますが、Filecoin、Sia、Storj、および Swarm はすべて消去コーディングを使用します。イレイジャーコーディングでは、データが固定サイズの部分に分割され、各部分が拡張されて冗長データでエンコードされます。各フラグメントに冗長データが保存されているため、元のファイルを再構築する必要があるのはフラグメントのサブセットのみです。
データ複製
画像の説明
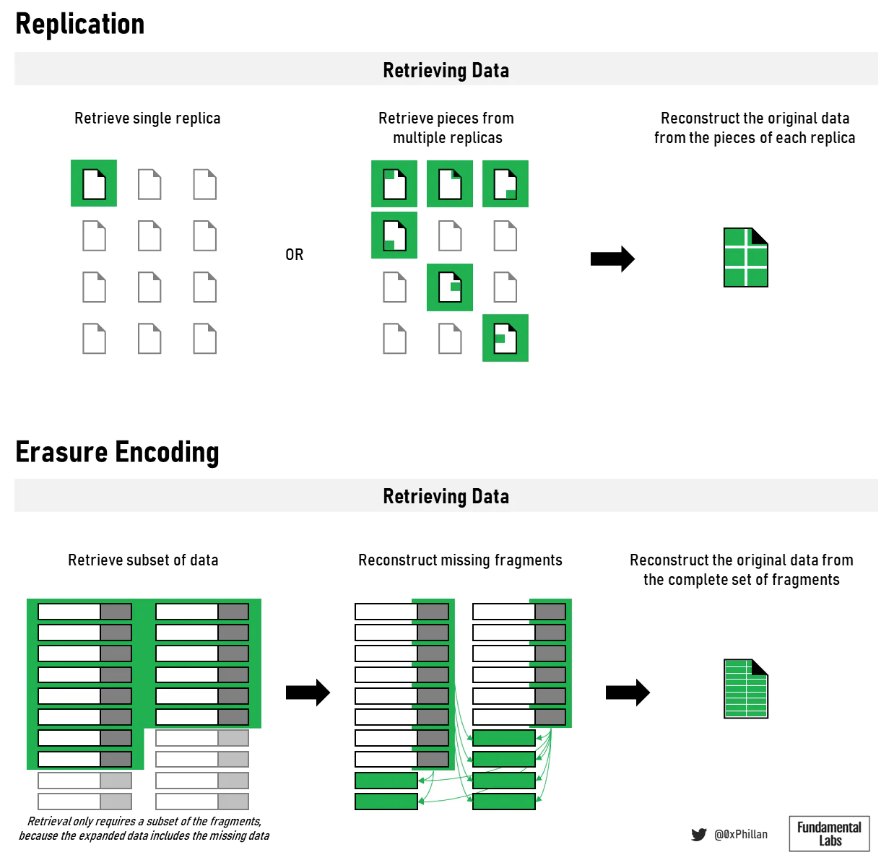
図 11: データの保存形式は取得と再構築に影響を与える
データの保存と複製に使用される方法は、ネットワークがデータを取得する方法に影響します。
ストレージ追跡
画像の説明
図 12: ブロックウィーブの 3 つのノードの図
結局、Storj と Swarm は 2 つのまったく異なるアプローチを採用します。 Storj では、サテライト ノードと呼ばれる 2 番目のノード タイプがストレージ ノードのグループのコーディネーターとして機能し、データの保存場所を管理および追跡します。 Swarm では、データのアドレスはデータ ブロックに直接埋め込まれます。データを取得するとき、ネットワークはデータ自体に基づいてどこを調べればよいかを認識します。
保存されたデータの証明
データの保存方法を証明する際、各ネットワークは独自のアプローチを採用しています。 Filecoin は、Proof of Replication (最初にデータをストレージ ノードに保存し、次にそのデータをセクターに封印する独自の Proof of Storage メカニズム) を使用します。封印プロセスにより、同じデータの 2 つの複製された部分が互いに固有であることが証明され、正しい数のコピーがネットワーク上に保存されることが保証されます (つまり、「複製の証明」)。
Crust は、データを多数の小さな部分に分割し、マークル ツリーにハッシュします。物理ストレージ デバイスに保存されている 1 つのデータのハッシュ結果と、予想されるマークル ツリー ハッシュ値を比較することで、Crust はファイルが正しく保存されたことを確認できます。これは Sia のアプローチと似ていますが、Crust がファイル全体を各ノードに保存するのに対し、Sia は消去符号化されたフラグメントを保存する点が異なります。 Crust はファイル全体を 1 つのノードに保存し、ハードウェア所有者でもアクセスできない密閉されたハードウェア コンポーネントであるノードの信頼済み実行環境 (TEE) を使用することでプライバシーを確保できます。 Crust は、このプルーフ オブ ストレージ アルゴリズムを「意味のあるプルーフ オブ ワーク」と呼んでいます。意味があるということは、保存されているデータに変更が加えられた場合にのみ新しいハッシュが計算され、無意味な操作が削減されることを意味します。 Crust と Sia はどちらも、データの整合性を検証するための信頼できる情報源としてマークル ルート ハッシュをブロックチェーンに保存します。
Storj はデータ監査を使用して、データが正しく保存されていることを確認します。データ監査は、Crust と Sia がマークル ツリーを使用してデータの一部を検証する方法と似ています。 Storj では、十分な数のノードが監査結果を返すと、ネットワークはブロックチェーンの信頼できる情報源と比較するのではなく、過半数の応答に基づいてどのノードに問題があるかを判断できます。 Storj のこのメカニズムは意図的なものであり、開発者は、ブロックチェーンを介したネットワーク全体の調整を減らすことで、速度 (コンセンサスを待つ必要がない) と帯域幅の使用量 (ネットワーク全体がブロックチェーンと定期的に通信する必要がない) の点でパフォーマンスが向上すると考えているためです。 )。
Arweave は、暗号化された作業証明パズルを使用して、ファイルが保存されているかどうかを判断します。このメカニズムでは、ノードが次のブロックをマイニングできるようにするには、前のブロックとネットワークのブロック履歴内の別のランダム ブロックにアクセスできることを証明する必要があります。 Arweave にアップロードされたデータはブロックに直接保存されるため、ストレージ プロバイダーが前のブロックへのアクセスを証明することでファイルを正しく保存したことが証明されます。
最後に、マークル ツリーは Swarm でも使用されますが、マークル ツリーはファイルの場所を決定するために使用されず、代わりにデータ ブロックがマークル ツリーに直接保存される点が異なります。 swarm にデータを保存する場合、ツリーのルート ハッシュ (データが保存されるアドレスでもあります) は、ファイルが適切にチャンク化されて保存されたことを証明します。
長期にわたるデータ可用性
同様に、データが一定期間保存されたかどうかを判断する場合、各ネットワークには独自の方法があります。 Filecoin では、ネットワーク帯域幅を削減するために、ストレージ マイナーは、データが保存される期間中、複製証明アルゴリズムを継続的に実行する必要があります。結果として得られる各期間のハッシュは、特定の期間中にストレージ領域が正しいデータによって占有されていることを証明するため、「時間と空間の証明」となります。
Crust、Sia、Storj は定期的にランダムなデータを検証し、その結果を調整メカニズム (Crust と Sia のブロックチェーン、および Storj のサテライト ノード) に報告します。 Arweave は、アクセス証明メカニズムを通じてデータの一貫した可用性を保証します。このメカニズムでは、マイナーは、最後のブロックにアクセスできることだけでなく、ランダムな履歴ブロックにアクセスできることも証明する必要があります。より古く、より希少なブロックを保存すると、マイナーが特定のブロックにアクセスするための前提条件である作業証明パズルに勝つ可能性が高まるため、インセンティブになります。
一方、Swarm は、人気の低いデータを長期にわたって保持するノードに報酬を与える定期的な懸賞を実行すると同時に、ノードが長期間保存することにコミットしたデータの所有権証明アルゴリズムも実行します。
Filecoin、Sia、および Crust では、ノードがストレージ ノードになるために担保を預け入れる必要がありますが、Swarm では長期ストレージ リクエストの場合にのみ担保が必要です。 Storj は前払い担保を必要としませんが、Storj はマイナーからのストレージ収益の一部を差し控えます。最後に、すべてのネットワークは、データを保存できることが証明されている期間に対して定期的にノードに支払います。
ストレージ価格の発見
ストレージの価格を決定するために、Filecoin と Sia はストレージ市場を使用します。ストレージ市場では、ストレージプロバイダーが提示価格を設定し、ストレージユーザーが支払ってもよい価格とその他のいくつかの設定を設定します。その後、ストレージ マーケットプレイスがユーザーを、要件を満たすストレージ プロバイダーに結び付けます。 Storj も同様のアプローチを採用していますが、主な違いは、ネットワーク上のすべてのノードを接続する単一のネットワーク全体のマーケットプレイスが存在しないことです。代わりに、各衛星には対話する独自のストレージ ノードのセットがあります。
最終的に、Crust、Arweave、Swarm はすべて、プロトコルにストレージ価格を決定させます。 Crust と Swarm はユーザーのファイル ストレージ要件に基づいて特定の方法で構成できますが、Arweave 上のファイルは永続的に保存されます。
永続的なデータ冗長性
時間の経過とともに、ノードはこれらのオープンなパブリック ネットワークから離れることになり、ノードが消滅すると、そこに保存されているデータも消滅します。したがって、ネットワークはシステム内である程度の冗長性を積極的に維持する必要があります。 Sia と Storj は、フラグメントのサブセットを収集し、基礎となるデータを再構築し、ファイルを再エンコードすることで欠落したフラグメントを再作成し、失われた消去符号化フラグメントを補完することで冗長性を実現します。 Sia では、どのデータ シャードがどのデータおよびユーザーに属しているかを区別できるのはクライアントだけであるため、ユーザーは定期的に Sia クライアントにログインしてシャードを補充する必要があります。ただし、Storj では、Satellite は常にオンラインであり、定期的にデータ監査を実行してデータ フラグメントを補完します。
Arweave の Proof-of-Access アルゴリズムにより、データはネットワーク全体で常に定期的に複製されますが、Swarm では、データは互いに近いノードに複製されます。 Filecoin では、時間の経過とともにデータが消失し、残っているファイルのフラグメントが特定のしきい値を下回ると、ストレージ注文がストレージ市場に再導入され、別のストレージマイナーがストレージ注文を引き継ぐことができます。 Crust の補充メカニズムは現在開発中です。
インセンティブデータ転送
画像の説明
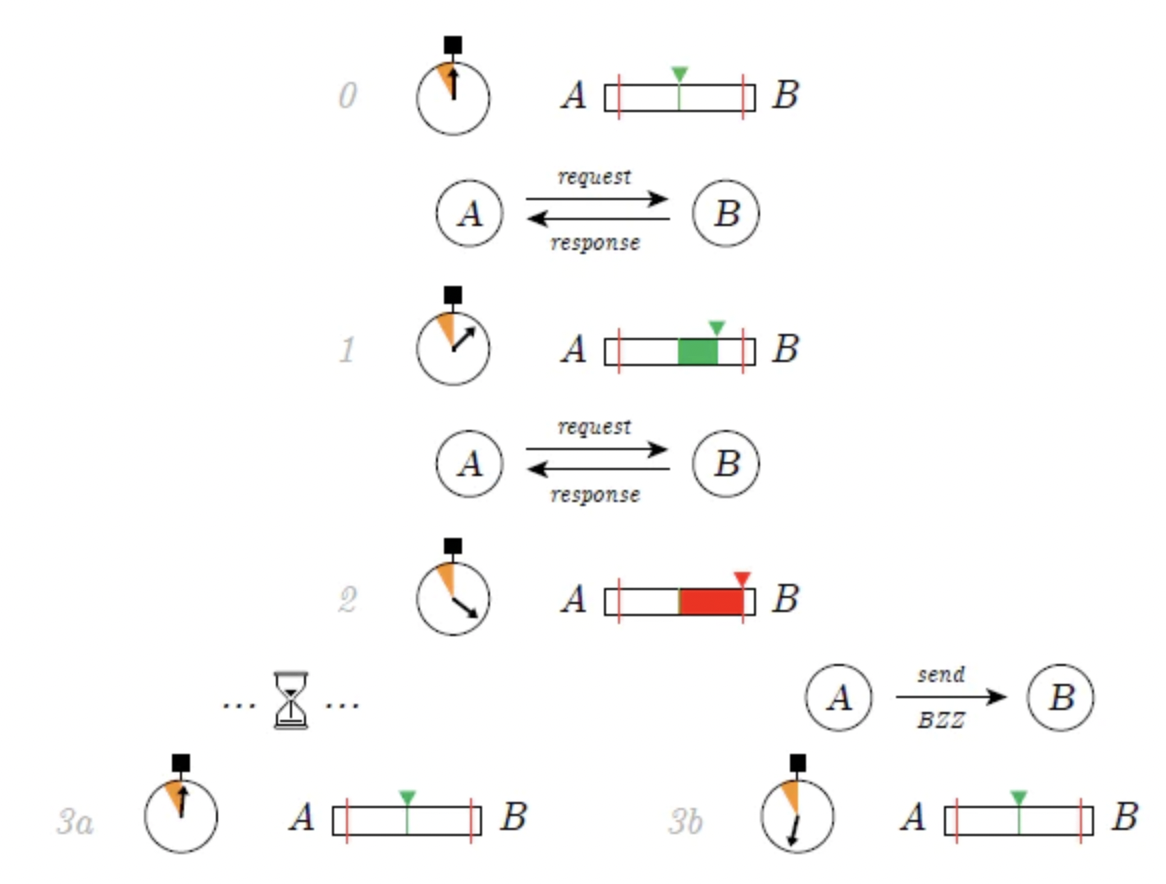
図 13: Swarm Accounting Protocol (SWAP)、出典: Swarm ホワイトペーパー
トークンエコノミー
トークンエコノミー
画像の説明
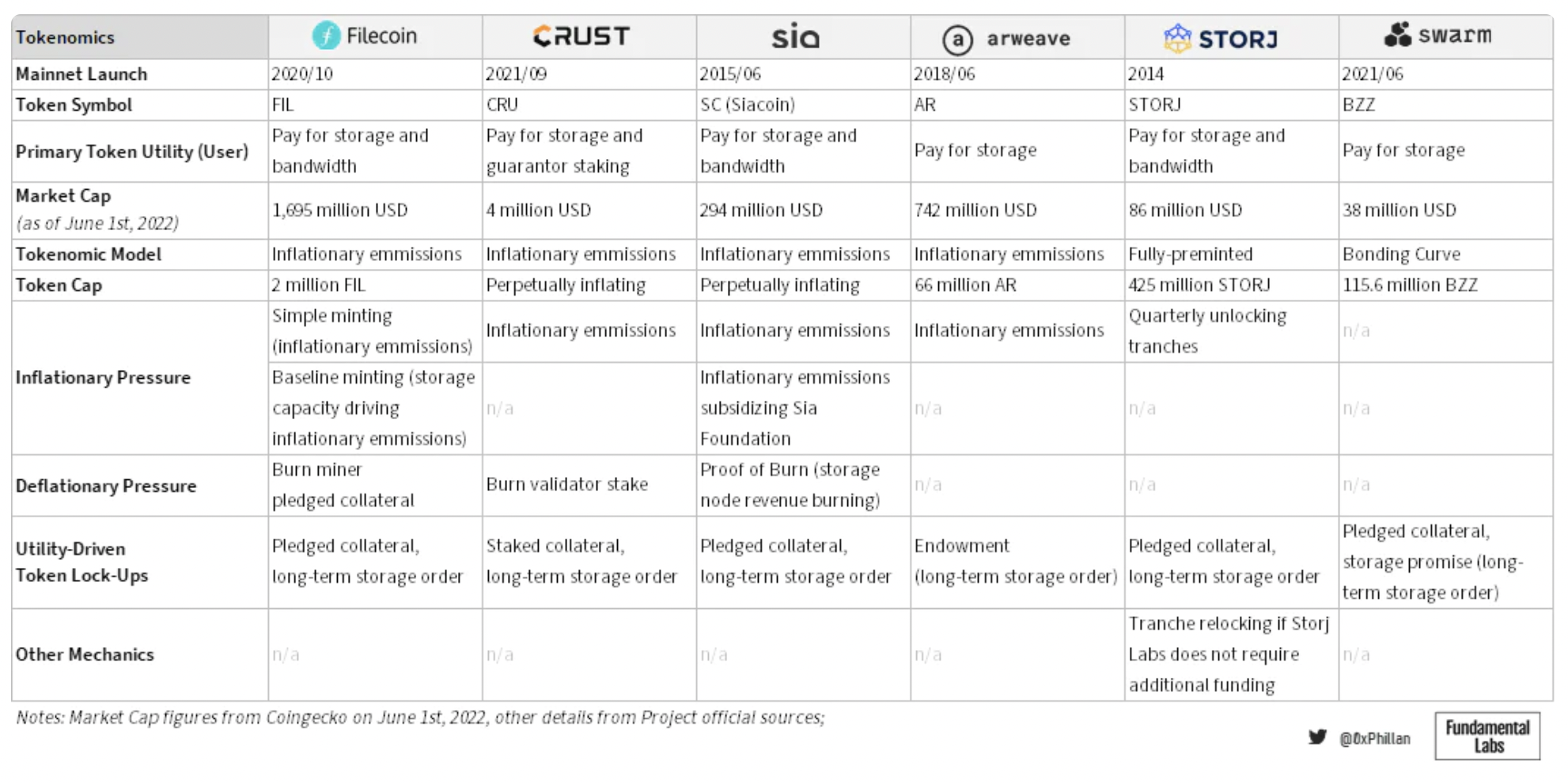
図 14: 監査されたストレージ ネットワークのトークンノミクス設計の決定。
どのネットワークが最適ですか?
一方のネットワークが他方のネットワークより客観的に優れているとは言えません。分散ストレージ ネットワークを設計する際には、無数のトレードオフが存在します。 Arweave はデータを永続的に保存するのには最適ですが、Web2.0 業界のプレーヤーを Web3.0 に移行するには必ずしも適しているわけではありません。すべてのデータを永久に保存する必要があるわけではありません。ただし、データの強力なサブフィールドである NFT と dApp には永続性が必要です。
最終的には、ネットワークの目的に基づいて設計を決定します。
以下は、さまざまなストレージ ネットワークの概要プロファイルであり、以下で定義される一連のスケールで相互に比較されます。使用されるスケールは、これらのネットワークの比較規模を反映していますが、分散ストレージの課題を克服するためのアプローチは、多くの場合、良くも悪くもなく、単に設計上の決定を反映しているだけであることに注意する必要があります。
ストレージパラメータの柔軟性: ユーザーがファイルのストレージパラメータを制御する程度
ストレージの永続性: ファイル ストレージは理論上、ネットワーク上でどの程度まで (つまり介入なしで) 永続化できるか
冗長性の永続性: 補充または修復を通じてデータの冗長性を維持するネットワークの機能
データ転送インセンティブ: ノードがデータを寛大に転送することをネットワークが保証する程度。
ストレージ追跡の普遍性: データの保存場所に関するノード間の合意の度合い
データアクセスの保証: ストレージプロセスの単一の参加者がネットワーク上のファイルへのアクセスを削除できないことを保証するネットワークの機能
スコアが高いほど、上記の各項目における能力が高いことを示します。
画像の説明

図 15: ファイルコインの概要概要
Crust のトークンエコノミクスは、超冗長性と高速取得を保証するため、高トラフィックの dApp に適しており、人気のある NFT のデータの高速取得にも適しています。
画像の説明
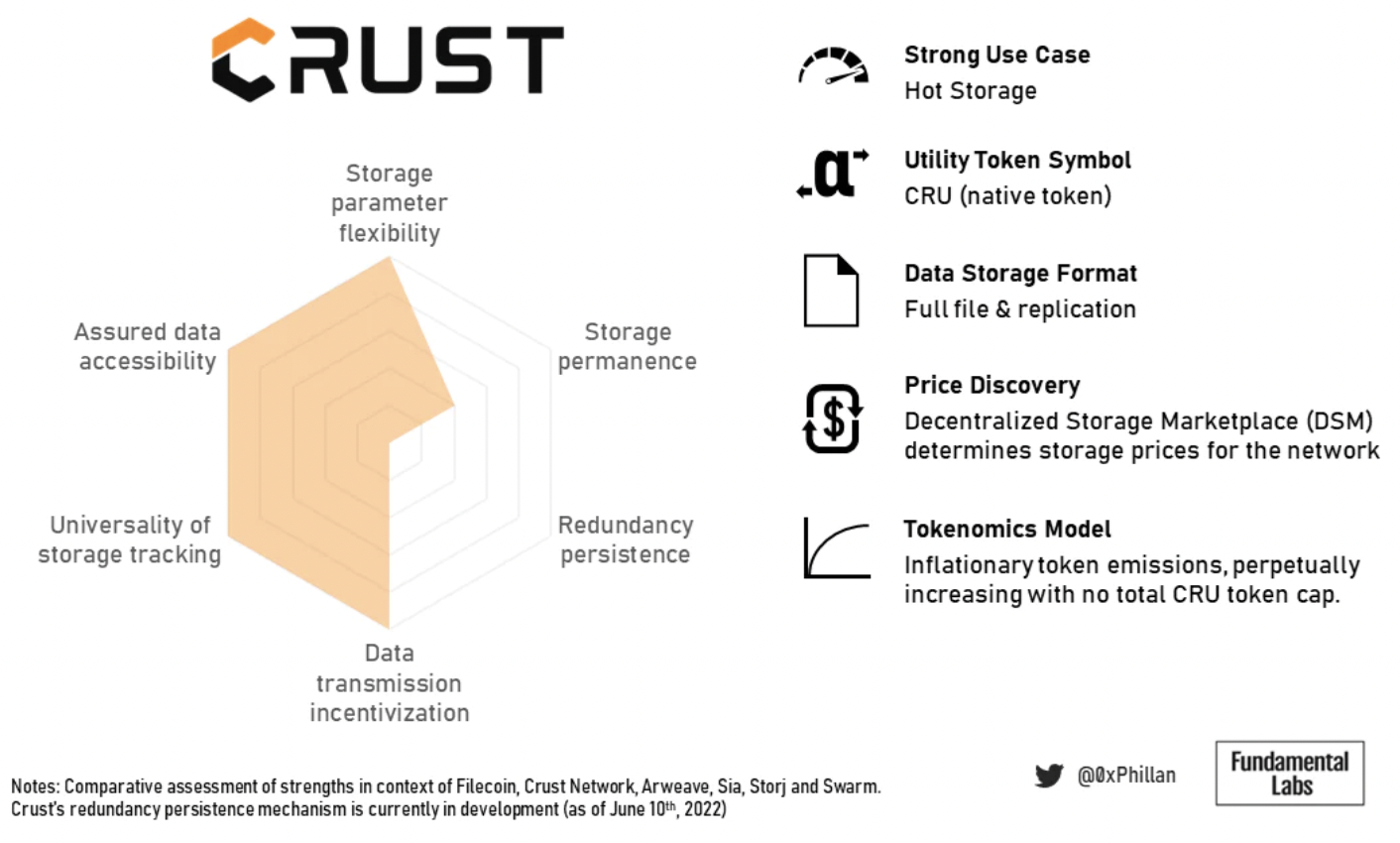
図 16: 地殻の概要の概要
画像の説明
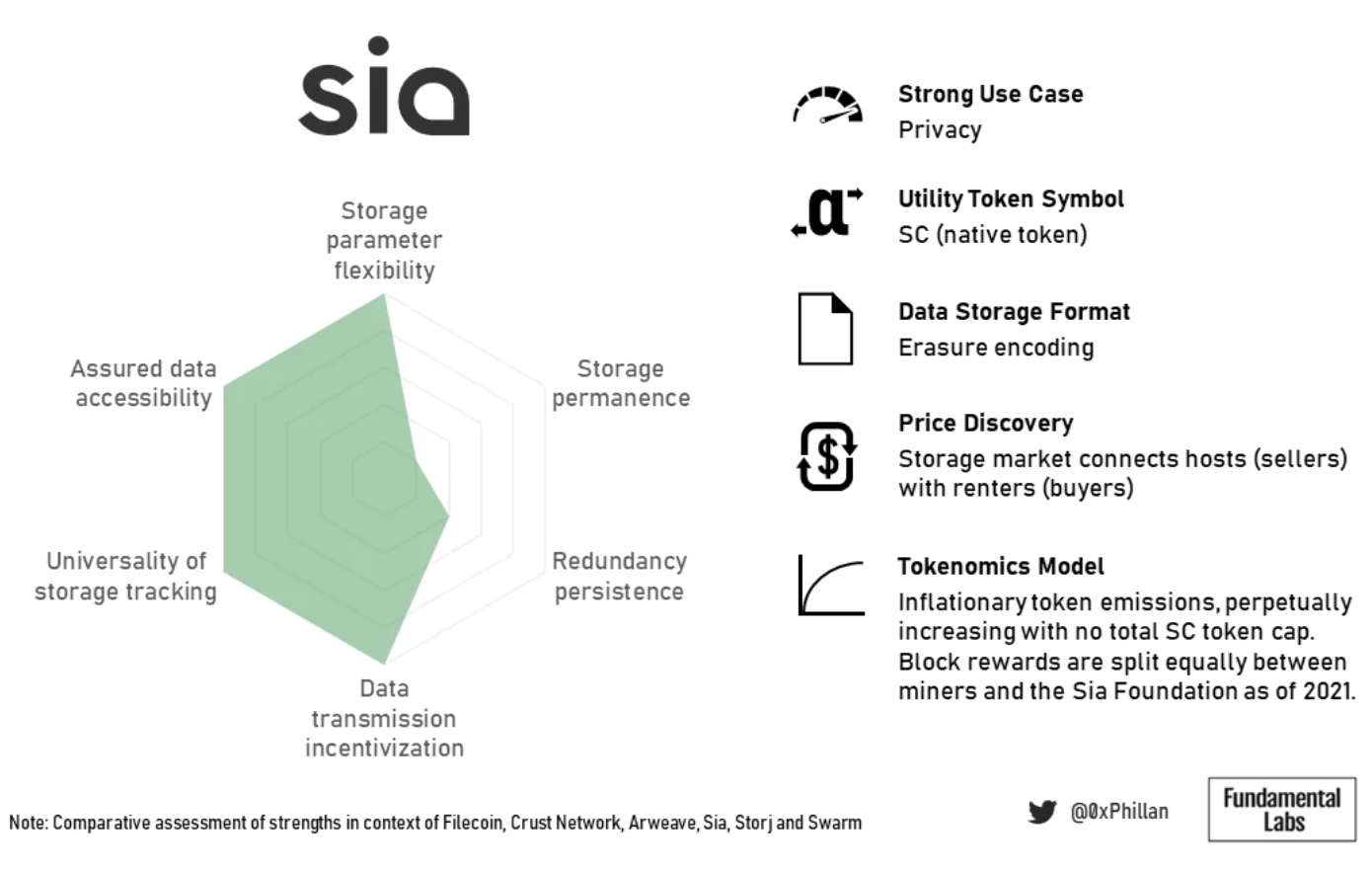
図 17: Sia の概要の概要
画像の説明
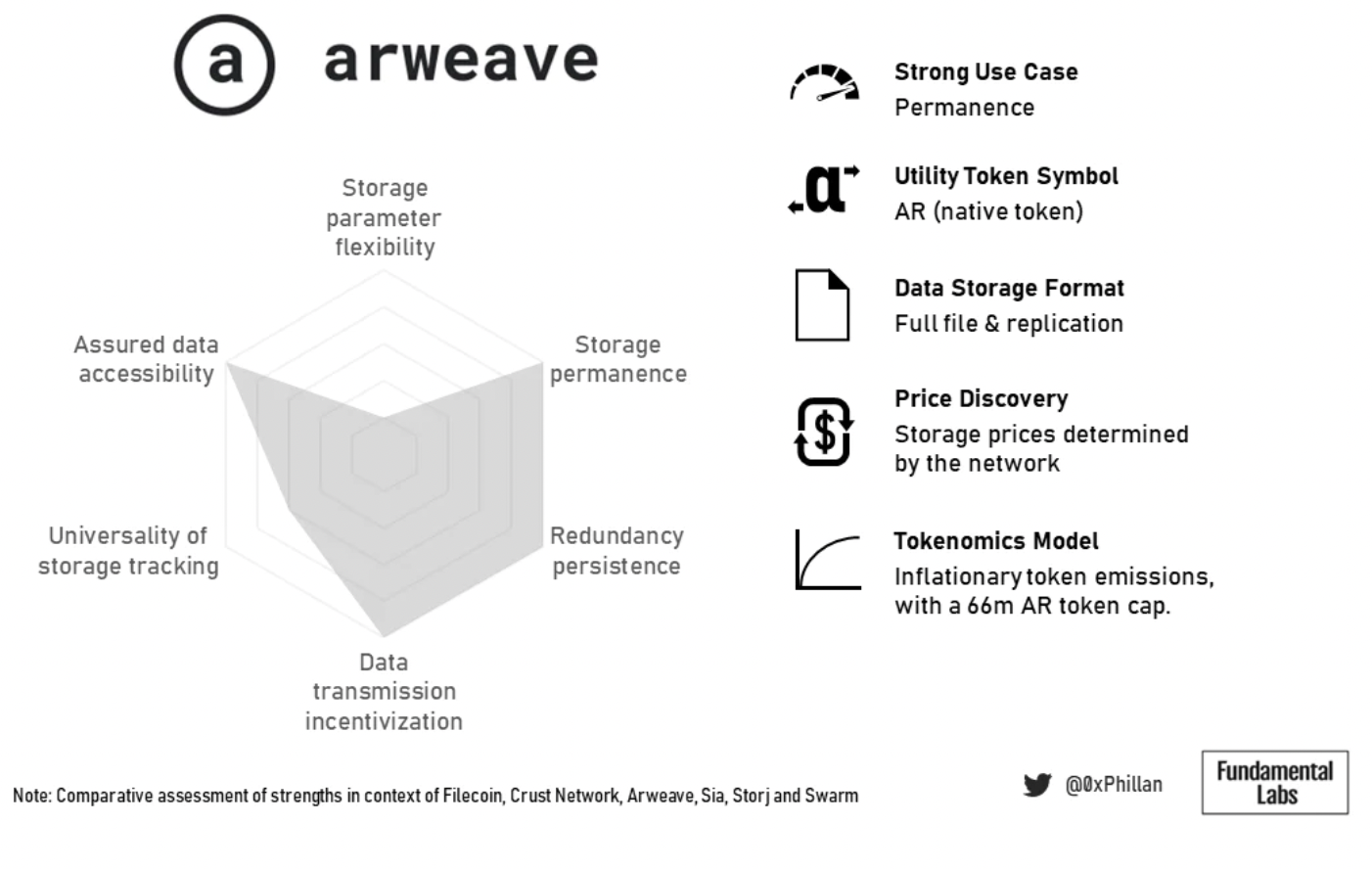
図 18: Arweave の概要
画像の説明
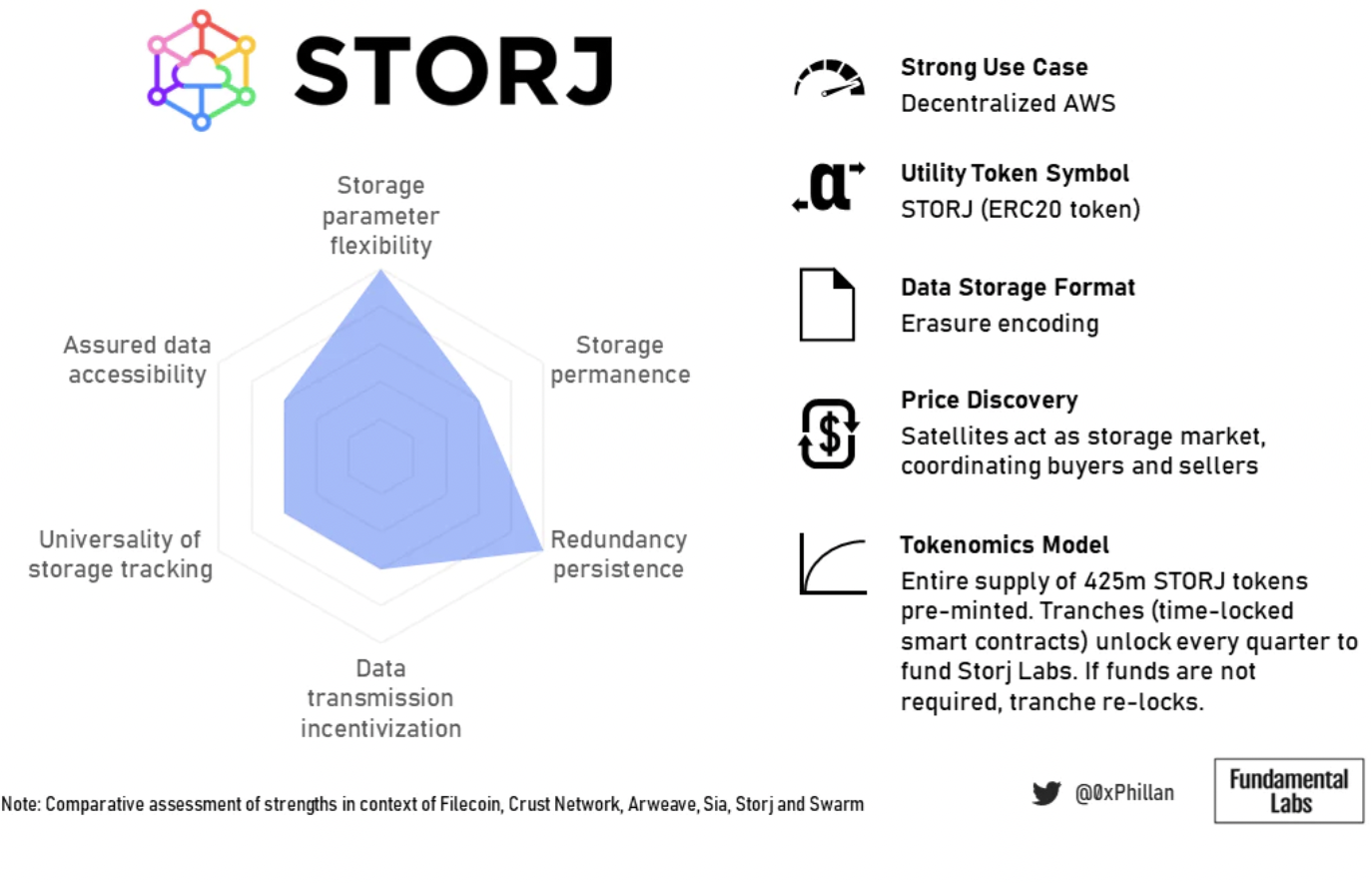
図 19: Storj の概要の概要
画像の説明
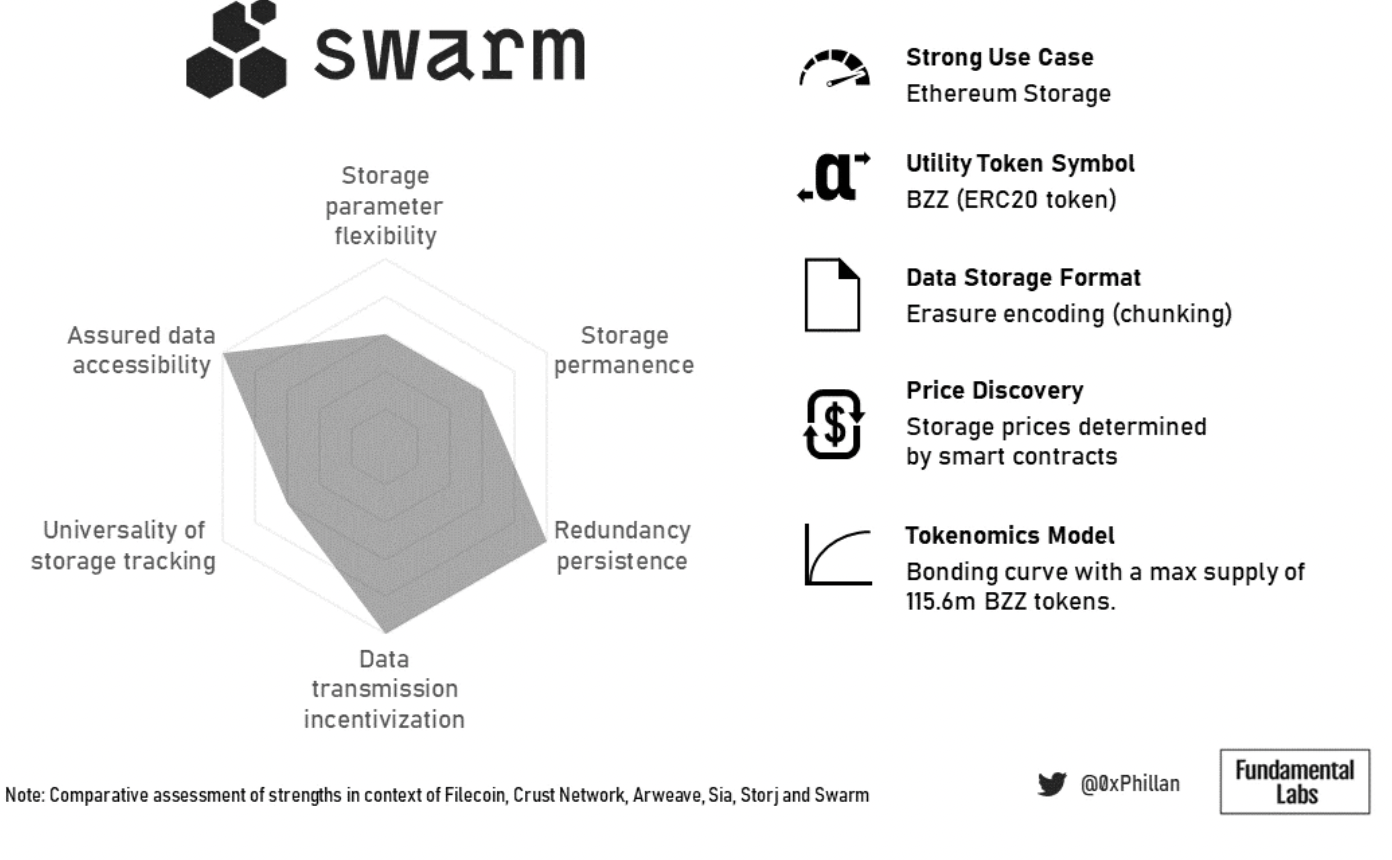
図 20: Swarm の概要の概要
画像の説明

図 21: 検討したストレージ ネットワークの強力な使用例の概要
最終的には、ネットワークの目的とネットワークが最適化しようとしている特定のユースケースによって、さまざまな設計上の決定が決まります。
次の章
Web3 インフラストラクチャの柱 (コンセンサス、ストレージ、コンピューティング) に戻ると、分散型ストレージ スペースには、特定のユースケースの市場で地位を確立した少数の強力なプレーヤーが存在することがわかります。これは、既存のソリューションを最適化したり、新しいニッチを獲得したりする新しいネットワークを排除するものではありませんが、次は何になるのかという疑問が生じます。
答えは「コンピューティング」です。真の分散型インターネットに向けた次のフロンティアは、分散型コンピューティングです。現在、ブロックチェーン上でスマート コントラクトを実行するコストの数分の 1 で複雑な dApp に電力を供給できるトラストレスな分散コンピューティング ソリューションを市場に投入できるソリューションはほんの一握りです。
Internet Computer (ICP) と Holochain (HOLO) は、この記事の執筆時点で分散コンピューティング市場で強い存在感を持っているネットワークです。それでも、コンピューティングスペースはコンセンサススペースやストレージスペースほど混雑していません。したがって、遅かれ早かれ強力な競合他社が市場に参入し、それに応じて地位を確立することになります。ストラトス (STOS) もそのような競合企業の 1 つです。 Stratos は、分散型データ グリッド テクノロジーを通じて独自のネットワーク設計を提供します。
終わり
終わり
分散ストレージに関するこの調査記事をお読みいただきありがとうございます。私たちの集団的な Web3 の将来の基本的な構成要素を明らかにすることを目的とした研究が好きなら、Twitter で @FundamentalLabs をフォローすることを検討してください。
貴重な概念やその他の情報が不足している場合は? Twitter @0xPhillan で私とつながり、この研究を一緒に強化していきましょう。
完全な作品は以下から入手できますArweave、Crust Networkに取得
元のリンク





