著者:Xiang|W3.ヒッチハイカー
関連書籍
データストレージ以外に、ファイルコインについて他に何を知っていますか?

著者:Xiang|W3.ヒッチハイカー
副題
関連書籍
Filecoin で他に注目すべき点は何ですか?
HTTP
"IPFS"最初のレベルのタイトル"HTTP"IPFSとは
分散型インターネット (web3.0) を強化する
ネットワークをスケーラブルで回復力があり、よりオープンにすることで人間の知識を保存および発展させるピアツーピア ハイパーメディア プロトコル。
IPFS は、ファイル、Web サイト、アプリケーション、およびデータを保存およびアクセスするための分散システムです。
ターゲットは
これについてはよく知られているかもしれませんが、オンラインにアクセスして Baidu 検索ページを開くと、表示されているものがそのまま得られます。
Web のアプリケーション層プロトコルは、従来の Web の中核であるハイパーテキスト転送プロトコル (HTTP) です。 HTTP は、クライアント プログラムとサーバー プログラムの 2 つのプログラムによって実装されます。クライアント プログラムとサーバー プログラムは異なるエンド システム上で実行され、HTTP セッションを交換します。 HTTP は、このデータの構造と、クライアントとサーバーが対話する方法を定義します。
Web ページはオブジェクトで構成されており、オブジェクトは HTML ファイル、JPEG グラフィック、小さなビデオ クリップなどの単なるファイルであり、URL アドレスによってアドレス指定できます。ほとんどの Web ページには、HTML ベース ファイルといくつかの参照オブジェクトが含まれています。
HTTP は、Web クライアントが Web サーバーに Web ページを要求する方法、およびサーバーが Web ページをクライアントに配信する方法を定義します。"ブラウザの役割は、HTTP プロトコルとフロントエンド コードを実行および解析して、コンテンツを表示することです。クエリを送信すると、通常、Web 側はデータベースにクエリを実行し、その結果をリクエスタ、つまりブラウザに返します。するとブラウザの表示が出てきます。"。
最初のレベルのタイトル
HTTP プロトコルの欠点
私たちが現在使用しているインターネットは、http または https プロトコルで動作しています。http プロトコルは、ハイパーテキスト転送プロトコルでもあります。これは、World Wide Web サーバーからローカル ブラウザにハイパーテキストを送信するために使用される送信プロトコルです。その普及から 32 年が経過しました。 1990年に提唱され、現在のインターネットの爆発的な発展に多大な貢献をし、インターネットの隆盛を実現しました。
しかし、HTTP プロトコルは基幹ネットワークの集中運用機構をベースとした C/S アーキテクチャに基づくインターネット通信プロトコルであり、多くの欠点があります。
404エラー
バックボーンネットワークの運用効率は低く、使用コストが高くなります。 HTTP プロトコルを使用すると、毎回集中サーバーから完全なファイルをダウンロードする必要があるため、時間がかかり非効率的です。
バックボーン ネットワークの並行メカニズムにより、インターネット アクセスの速度が制限されます。この集中型バックボーン ネットワーク モデルは、同時実行性が高い場合でもネットワーク アクセス中に輻輳を引き起こします。
既存の http プロトコルの下では、すべてのデータはこれらの集中サーバーに保存され、インターネット巨人は私たちのデータを絶対的に制御し、解釈するだけでなく、さまざまな監視、封鎖、監視をある程度まで行うことができ、イノベーションと開発も大きく制限されます。
コストが高く、攻撃を受けやすいため、Baidu、Tencent、Ali などのトラフィック量の多い企業は、HTTP プロトコルをサポートするために、サーバーの維持や DDoS を防ぐためのセキュリティ リスクに多大なリソースを投資してきました。そして他の攻撃。バックボーン ネットワークは、戦争、自然災害、中央サーバーのダウンタイムなどの要因の影響を受けやすく、インターネット全体のサービスが中断される可能性があります。
ipfsソリューション
IPFS向けのソリューション
IPFS は、ファイルの履歴バージョンを遡る機能を提供します。これにより、ファイルの履歴バージョンを簡単に表示でき、データは削除できず、永久に保存できます。
IPFS は、コンテンツ アドレス指定に基づくストレージ モードです。同じファイルが繰り返し保存されることはなく、ストレージ スペースなどの余分なリソースを圧迫し、データ ストレージ コストを削減します。 P2P ダウンロードに切り替えると、帯域幅の使用コストを 60% 近く節約できます。
IPFS は P2P ネットワークに基づいており、複数のソースからデータを保存したり、複数のノードから同時にデータをダウンロードしたりできます。
分散型ネットワーク上に構築された IPFS は、集中管理や制限が難しく、インターネットはよりオープンになります。
IPFS 分散ストレージは、中央のバックボーン ネットワークへの依存を大幅に軽減できます。
簡潔に言うと:

HTTP は集中サーバーに依存しているため、攻撃に対して脆弱であり、トラフィックが急増し、サーバーがダウンタイムしやすく、ダウンロード速度が遅く、ストレージ コストが高くなります。
IPFS は分散ノードであり、安全性が高く、DDoS 攻撃を受けにくいです。バックボーン ネットワークに依存せず、ストレージ コストを削減し、大容量のストレージ スペースを備えています。ダウンロード速度が速く、ファイルの履歴バージョン レコードを保存できます。検索可能であり、理論的には永久に保存できます。
新しいテクノロジーが古いテクノロジーに取って代わるのは、次の 2 つの点にすぎません。
まず、システム効率を向上させることができます。
IPFS は両方を実行します。
開発の際、IPFS チームは高度にモジュール化された統合手法を採用し、プロジェクト全体をビルディング ブロックのように開発します。 Protocol Labs チームは 2015 年に設立され、IPFS の最下位層として機能する 3 つのモジュール、IPLD、LibP2P、および Multiformats を 17 年間開発してきました。Multiformats は、一連のハッシュ暗号化アルゴリズムと自己記述方式 (値から値がどのように生成されるかがわかります) を集めたもので、SHA1 \SHA256 \SHA512 \Blake3B など 6 つの主流暗号方式を備え、nodeID を暗号化して記述します指紋データの生成。
LibP2P は IPFS コアの中核です。さまざまなトランスポート層プロトコルや複雑なネットワーク デバイスに直面して、開発者が高速かつコスト効率の高い利用可能な P2P ネットワーク層を迅速に構築するのに役立ちます。これが、IPFS テクノロジが広く使用されている理由です。ブロックチェーンプロジェクトが好まれる理由。IPLD は実際には、既存の異種データ構造を 1 つの形式に統合して、異なるシステム間のデータ交換と相互運用性を容易にする変換ミドルウェアです。ビットコインやイーサリアムのブロックデータなど、現在IPLDがサポートしているデータ構造もIPFSやIPLDをサポートしています。これは、IPFS がブロックチェーン システムに歓迎される 2 番目の理由でもあり、その IPLD ミドルウェアは、さまざまなブロック構造を 1 つの標準に統合して配信することができ、開発者はパフォーマンス、安定性、バグを心配することなく、比較的高い水準の成功を実現できます。
IPFSのメリットIPFS の利点Kademlia、BitTorrent、Git などの概念を組み合わせたもの。ハイパーメディア配布プロトコル
中央ノードの障害を回避し、レビューや制御なしで完全に分散化ポイントツーポイントネットワーク
明日のインターネットへの船出——新しいブラウザは、デフォルトで IPFS プロトコル (brave、opera) をすでにサポートしています。従来のブラウザは、https://ipfs.io などのアドレスでパブリック IPFS ゲートウェイにアクセスするか、インストールすることができます。IPFS コンパニオンIPFS ネットワーク上に保存されているファイルにアクセスするための拡張機能
——ファイルをローカル ノードに追加するだけで、キャッシュに適したコンテンツ ハッシュ アドレスと BitTorrent のようなネットワーク帯域幅配布を通じて世界中のファイルを取得できるようになります。
強力なオープンソース コミュニティの支援に依存して構築する
完全な分散アプリケーションとサービス
の一つ
開発者ツールセット
IPFS は、システム内でファイルがどのように保存、インデックス付け、送信されるかを定義します。つまり、アップロードされたファイルは保存用に特別なデータ形式に変換され、IPFS は同じファイルをハッシュして一意のアドレスを決定します。したがって、どのデバイスや場所であっても、同じファイルは同じアドレスを指します (URL とは異なり、このアドレスはネイティブであり、暗号化アルゴリズムによって保証されており、変更できませんし、変更する必要もありません) )。次に、ネットワーク内のすべてのデバイスをファイル システム経由で接続し、IPFS システムに保存されているファイルを、ファイアウォールの影響を受けることなく、世界中のどこからでもすぐに取得できるようにします (ネットワーク プロキシは必要ありません)。基本的に、IPFS は WEB コンテンツの配布メカニズムを変更し、完全な分散化を実現できます。
最初のレベルのタイトル
IPFS の仕組みIPFS はピアツーピア (p2p) ストレージ ネットワークです。コンテンツには、情報を配信したり、情報を保存したり、あるいはその両方を行う、世界中のどこにでもあるノードを介してアクセスできます。 IPFS は、要求されたコンテンツを見つけるために、その場所ではなくコンテンツ アドレスを使用する方法を知っています。IPFS の 3 つの基本原則を理解します。コンテンツアドレス指定による一意の識別子有向非巡回グラフ (DAG) を介したコンテンツのリンク
これら 3 つの原則は相互に依存して IPFS エコシステムを構築します。から始めましょう
コンテンツアドレッシング
とその内容
一意に識別します"始める"
コンテンツのアドレス指定とコンテンツの一意の識別
コンテンツのアドレス指定とコンテンツの一意の識別
https://en.wikipedia.org/wiki/Aardvark
/Users/Alice/Documents/term_paper.doc
C:\Users\Joe\My Documents\project_sprint_presentation.ppt
IPFS は、コンテンツ アドレスを使用して、場所ではなくコンテンツに基づいてコンテンツを識別します。コンテンツからアイテムを見つけることは、誰もが常に行っていることです。たとえば、図書館で本を探している場合、タイトルで探すことがよくありますが、それが何であるかを尋ねているため、これがコンテンツ アドレッシングです。場所のアドレス指定を使用して書籍を検索した場合は、その場所によってその書籍が見つかります。
左から2階、3段目、4階の本が4冊欲しいです。
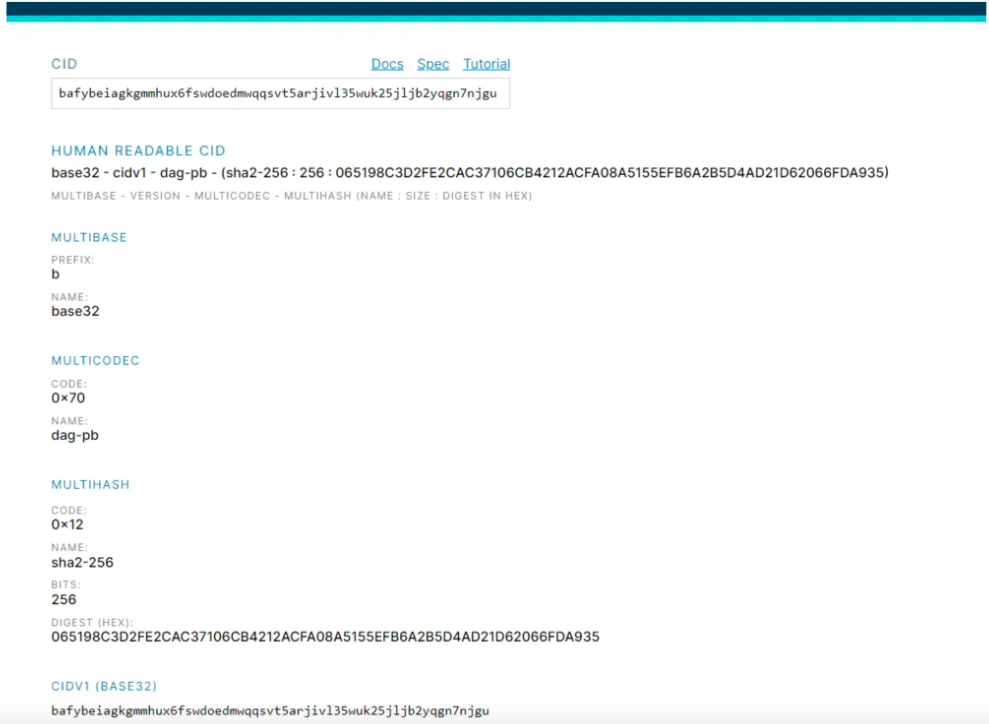
CID (Content Identifiers )
誰かがその本を動かしたら、運が悪いですよ!問題はインターネットとコンピュータの両方に存在します。コンテンツは場所によって検索されるようになりました。例:
対照的に、IPFS プロトコルを使用するすべてのコンテンツには * が付いています。
コンテンツ識別子
*、つまり CID。ハッシュは、元のコンテンツと比較すると短く見える場合でも、その元のコンテンツに固有のものです。
多くの分散システムは、ハッシュによるコンテンツ アドレス指定を使用して、コンテンツを識別するだけでなく、コンテンツをリンクします。コードをサポートするコミットから、暗号通貨を実行するブロックチェーンに至るまで、すべてがこの戦略を利用しています。ただし、これらのシステムの基礎となるデータ構造は必ずしも相互運用可能であるとは限りません。
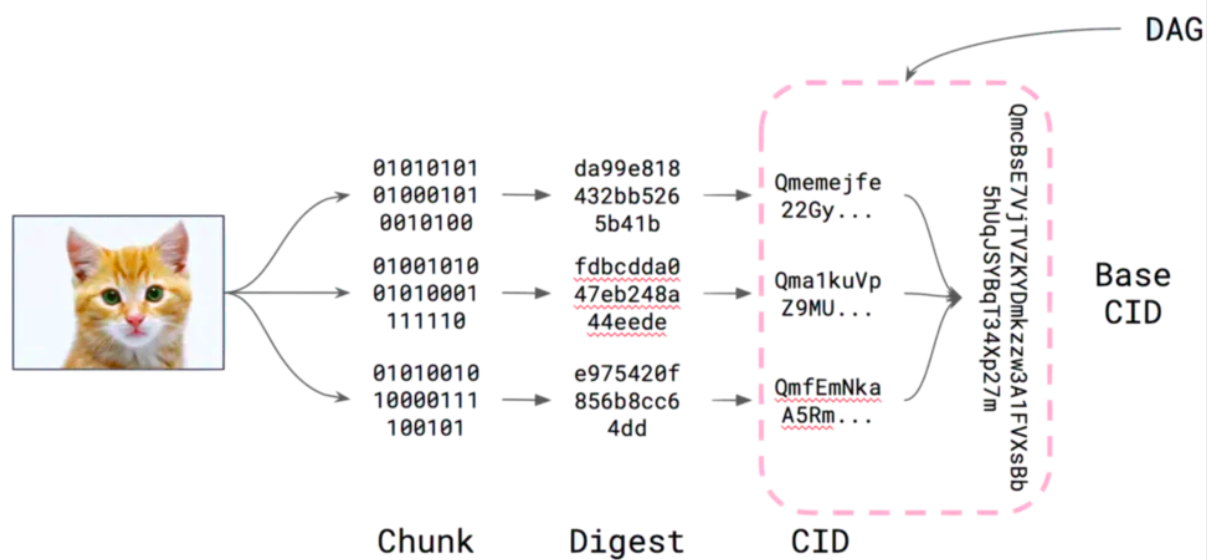
CID仕様IPFS で生まれ、現在は複数の形式で存在し、IPFS、IPLD、libp2p、Filecoin などの幅広いプロジェクトをサポートしています。コース全体でいくつかの IPFS の例を共有しますが、このチュートリアルは CID 自体の構造について説明しています。CID は、すべての分散情報システムがコンテンツを参照するための中核的な識別子として使用します。コンテンツ識別子または CID は、自己記述型のコンテンツ アドレス指定可能な識別子です。これは、コンテンツが保存されている場所を示すものではなく、コンテンツ自体に基づいて一種のアドレスを形成します。 CID の文字数は、コンテンツ自体のサイズではなく、基になるコンテンツの暗号化ハッシュによって決まります。 IPFS のほとんどのコンテンツはハッシュ sha2-256 を使用するため、遭遇するほとんどの CID は同じサイズ (256 ビット、つまり 32 バイト) になります。これにより、特に複数のコンテンツを扱う場合に管理が容易になります。
たとえば、ツチブタのイメージを IPFS ネットワークに保存した場合、その CID は次のようになります: QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF以前にデモしたユニスワップの IPFS リンク
CID 作成の最初のステップは、暗号化アルゴリズムを使用して入力データを変換し、任意のサイズの入力 (データまたはファイル) を固定サイズの出力にマッピングすることです。この変換は、ハッシュ デジタル フィンガープリント、または単にハッシュと呼ばれます (デフォルトでは sha2-256 を使用します)。使用中で
暗号化アルゴリズムハッシュは次の特性に従って生成される必要があります。
確実:同じ入力は常に同じハッシュを生成する必要があります。
無関係:
入力データを少し変更すると、まったく異なるハッシュが生成されるはずです。
一方向:
Multiformats
ハッシュから入力データをプッシュバックすることは現実的ではありません。
独自性:
Multiformats特定のハッシュを生成できるのは 1 つのファイルだけです。
ツチブタ画像の 1 つのピクセルを変更すると、暗号化アルゴリズムによって画像に対してまったく異なるハッシュが生成されることに注意してください。
コンテンツ アドレスを使用してデータをフェッチすると、そのデータの期待されるバージョンが表示されることが保証されます。これは、特定のアドレス (URL) のコンテンツが時間の経過とともに変化する従来の Web 上の位置アドレス指定とはまったく異なります。
CIDの構造
マルチフォーマットは主に、IPFS システムにおける ID 暗号化とデータ自己記述を担当します。
マルチフォーマットは、将来のセキュリティ システムのためのプロトコルのコレクションであり、自己記述形式により、システムが相互に連携し、アップグレードできるようになります。
マルチハッシュ - 自己記述型ハッシュ
multiaddr - 自己記述型ネットワークアドレス
マルチベース - 自己記述型ベースエンコーディング
multistream - 自己記述型ストリーミング ネットワーク プロトコル
マルチグラム (WIP) - 自己記述型パケット ネットワーキング プロトコル
コンテンツ リンク有向非巡回グラフ (DAG)
Merkle DAG は CID の割り当て可能性を継承します。 DAG のコンテンツ アドレス指定を使用すると、DAG の配布に興味深い影響がいくつかあります。まず、もちろん、DAG を所有する人は誰でも、その DAG のプロバイダーとして機能できます。 2 つ目は、ファイルのディレクトリなど、DAG としてエンコードされたデータを取得するときに、おそらく多くの異なるプロバイダーからノードのすべての子を並行して取得できるという事実を利用できることです。第三に、ファイル サーバーは集中型のデータ センターに限定されず、より広い範囲のデータをカバーできるようになります。最後に、DAG 内の各ノードには独自の CID があるため、DAG が表す DAG は、埋め込まれている DAG とは独立して共有および取得できます。
検証可能性
検証可能性
ファイルをバックアップし、数か月後にこれら 2 つのファイルまたはディレクトリを見つけて、それらの内容が同じであるかどうか疑問に思ったことはありませんか?苦労してファイルを比較しなくても、バックアップごとにマークル DAG を計算できます。ルート ディレクトリの CID が一致すれば、どれが安全に削除できるかがわかり、ハード ドライブ上のスペースが解放されます。
割り当て可能性
割り当て可能性
たとえば、大規模なデータの配布です。従来の Web ネットワークの場合:
共有ファイルの開発者は、サーバーの保守とそれに関連するコストを負担します。
世界中からのリクエストに応答するために同じサーバーが使用される可能性があります
データ自体は単一のファイル アーカイブとしてモノリシックに配布できます。
同じデータの代替プロバイダーを見つけるのが難しい
データは大きな塊になっている可能性があるため、単一のプロバイダーから連続的にダウンロードする必要があります
他人がデータを共有するのは難しい
Merkle DAG は、これらすべての問題を軽減するのに役立ちます。データをコンテンツ アドレス指定の DAG に変換すると、次のようになります。
世界中のノードがデータの提供に参加できます
DAG の各部分には独自の CID があり、個別に配布できます。
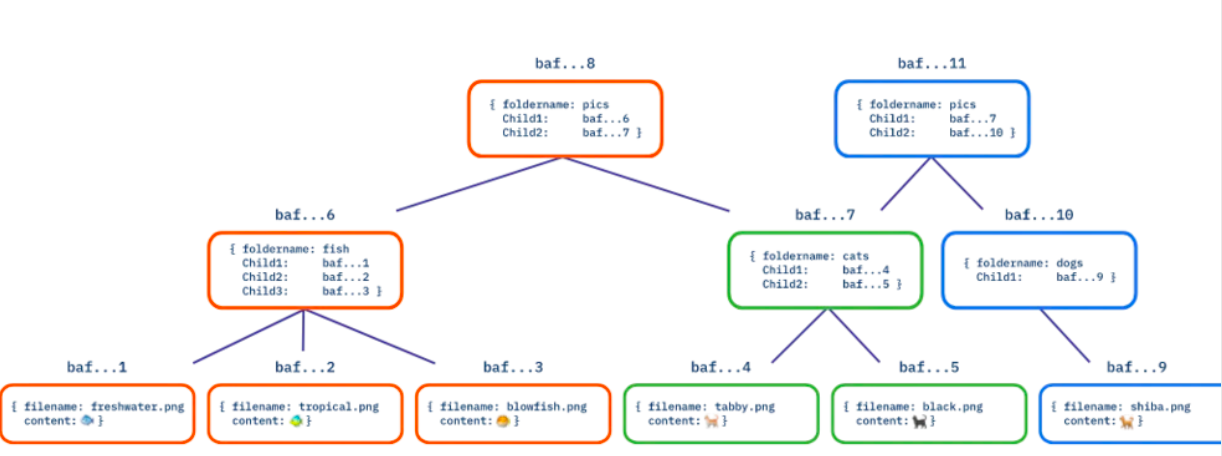
DAG を構成するノードは小さく、多くの異なるプロバイダーから並行してダウンロードできます。
これらはすべて、重要なデータのスケーラビリティに貢献します。
重複排除
Libp2p
libp2pたとえば、Web の閲覧を考えてみましょう。ユーザーがブラウザを使用して Web ページにアクセスすると、ブラウザはまず、画像、テキスト、スタイルなど、ページに関連するリソースをダウンロードする必要があります。実際、多くの Web ページは、同じテーマを使用しているだけで、他の Web ページはわずかに異なるだけで、非常によく似ています。ここには多くの冗長性があります。IPFSブラウザが十分に最適化されていれば、このコンポーネントを複数回ダウンロードする必要がなくなります。ユーザーが新しい Web サイトにアクセスするたびに、ブラウザーは DAG 内のさまざまな部分に対応するノードをダウンロードするだけでよく、以前にダウンロードされた他の部分を再度ダウンロードする必要はありません。 (WordPress テーマ、Bootstrap CSS ライブラリ、または一般的な JavaScript ライブラリを考えてください)
分散ハッシュ テーブル (DHT) は、キーを値にマッピングするための分散システムです。 IPFS では、DHT はコンテンツ ルーティング システムの基本コンポーネントとして使用され、ディレクトリとナビゲーション システムの間の交差点として機能します。ユーザーが探しているものを、一致するコンテンツを保存するピアノードにマッピングします。これは、誰がどのデータを所有しているかを示す巨大なテーブルだと考えてください。
通信網
最初のレベルのタイトル
は、から始まるモジュラー ネットワーク スタックです。独立したプロジェクトに発展しました。 Polkadotも使用されており、eth2.0も一部使用されています。
NAT:libp2p が分散型 Web の重要な部分である理由を説明するには、一歩下がって、libp2p がどこから来たのかを理解する必要があります。 libp2p の最初の実装は、ピアツーピア ファイル共有システムである IPFS から始まりました。まずは、IPFS が解決しようとしているネットワークの問題を探ってみましょう。
最初のレベルのタイトルネットワークは独自のルールと制約を持つ非常に複雑なシステムであるため、これらのシステムを設計する際には、多くの状況とユースケースを考慮する必要があります。
信頼性:ファイアウォール:
ラップトップにファイアウォールがインストールされており、特定の接続がブロックまたは制限されている可能性があります。NAT (ネットワーク アドレス変換) を備えたホーム WiFi ルーター。ラップトップのローカル IP アドレスを、家の外のネットワークが接続できる単一の IP アドレスに変換します。
高遅延ネットワーク:これらのネットワークは接続が非常に遅いため、ユーザーはコンテンツを表示するまでに長時間待たされることになります。
信頼性:世界中には多くのネットワークが点在しており、多くのユーザーは、ユーザーに良好な接続を提供する堅牢なシステムがないため、ネットワークが遅いと感じることがよくあります。頻繁に接続が切断され、ユーザーのネットワークシステムの品質が悪く、ユーザーに適切なサービスを提供できません。
ローミング:モバイル アドレス指定は、世界中のさまざまなネットワークを移動する際に、ユーザーのデバイスが一意に検出可能であることを保証する必要があるもう 1 つのケースです。現在、彼らは多数の調整ポイントと接続を必要とする分散システムで動作していますが、最適なソリューションは分散型です。
検閲:Web の現在の状態では、政府機関であれば、特定の Web サイト ドメイン上の Web サイトをブロックするのは比較的簡単です。これは違法行為を阻止するのには役立ちますが、独裁政権が国民から資源へのアクセスを剥奪したい場合には問題になります。
ランタイム: IoT (モノのインターネット) デバイス (Raspberry Pi、Arduino など) など、多くの種類のランタイムが存在し、大規模に採用されています。これらは限られたリソースで構築されているため、ランタイムは多くの場合、ランタイムについて多くの前提を置く異なるプロトコルを使用します。
イノベーションは非常に遅いです:
膨大なリソースを持つ最も成功した企業であっても、新しいプロトコルの開発と展開には数十年かかることがあります。
データのプライバシー:
Peer 消費者は最近、ユーザーのプライバシーを尊重しない企業が増えていることに懸念を抱いています。
Peer-to-Peer (P2P) p2p プロトコルに関する現在の問題
P2P プロトコルに関する現在の問題
ピアツーピア (P2P) ネットワークは、大規模な自然災害や人災によってピアノードがネットワークから切断された場合でも機能する、回復力のあるネットワークを作成する方法として、インターネットの概念から考案されました。コミュニケーションを続けるために。
P2P ネットワークは、ビデオ通話 (Skype など) からファイル共有 (IPFS、Gnutella、KaZaA、eMule、BitTorrent など) まで、さまざまなユースケースに使用できます。
基本的な考え方
- 分散型ネットワークの参加者。ピアノードは、アプリケーションにおいて同等の特権を持ち、同等の能力を持つ参加者です。 IPFS では、ラップトップに IPFS デスクトップ アプリケーションをロードすると、デバイスは分散ネットワーク IPFS のピア ノードになります。
- ワークロードがピアノード間で共有される分散型ネットワーク。したがって、IPFS では、各ピア ノードが他のピア ノードと共有されるすべてまたは一部のファイルをホストできます。ノードがファイルを要求すると、それらのファイルのチャンクを所有するノードは、要求されたファイルの送信に参加できます。データを要求したピア パーティは、後で他のピア パーティとデータを共有できます。
IPFS は、現在および過去の Web アプリケーションや研究からインスピレーションを得て、P2P システムの改善を試みています。学界には、これらの問題の一部を解決する方法に関するアイデアを提供する科学論文が数多くありますが、研究では暫定的な結果は得られましたが、使用したり調整したりできるコードの実装が不足しています。
既存の P2P システムのコード実装を見つけるのは非常に難しく、たとえ存在したとしても、次の理由により再利用や再利用が難しいことがよくあります。
不正なファイルまたは存在しないファイル
制限付きライセンス、またはライセンスが見つかりません
非常に古いコードが最後に更新されたのは 10 年以上前です
連絡先がない (連絡先の保守者がいない)
クローズドソース (独自の) コード
廃止予定の製品
仕様が提供されていない
フレンドリーな API が公開されていない
実装が特定のユースケースと密接に結合しすぎている
将来のプロトコルのアップグレードは使用できません
libp2p は IPFS のネットワークスタックですが、IPFS から分離され、独立したファーストクラスプロジェクトおよび IPFS の依存プロジェクトになります。モジュラー。

このようにして、libp2p は IPFS に依存せずにさらに発展し、独自のエコシステムとコミュニティを獲得できます。 IPFS は、libp2p になった多くのユーザーのうちの 1 つにすぎません。

こうすることで、各プロジェクトはそれぞれの目標のみに集中できます。

IPFS はコンテンツ アドレス指定、つまりネットワーク上のコンテンツの検索、取得、認証に重点を置いています。

IPLD
libp2p は、プロセスのアドレス指定、つまりネットワーク内のデータ転送プロセスの検索、接続、認証に重点を置いています。では、libp2p はどのようにしてそれを行うのでしょうか?
I答えは次のとおりです。
モジュラー
libp2p は、ネットワーク スタックを構成する特定の部分を特定しました。多言語実装、7 つの開発言語をサポート、libp2p の JavaScript 実装はブラウザやモバイル ブラウザにも適しています。これは、アプリケーションがデスクトップとモバイルでも同様に libp2p を実行できるようにするため、非常に重要です。。
アプリケーションには、ファイル ストレージ、ビデオ ストリーミング、暗号ウォレット、開発ツール、ブロックチェーンが含まれます。ブロックチェーンの上位プロジェクトには、IPFS を使用する libp2p モジュールがすでにあります。IPLD はデータを理解して処理するために使用されます。
PLD は、既存の異種データ構造を 1 つの形式に統合し、異なるシステム、データ モデル、デコーディング間のデータ交換と相互運用性を容易にし、CID をリンクとして使用する変換ミドルウェアです。まず、データのドメインと範囲を記述する「データ モデル」を定義します。これは私たちが構築するすべての基礎となるため、重要です。 (大まかに言えば、データ モデルはマップ、文字列、リストなどの「JSON に似ている」と言えます。) この後、メッセージからそれを解析し、それをメッセージとして使用する方法を示す「コーデック」を定義します。フォームの発行を希望するメッセージ。 IPLD には多くのコーデックがあります。対話したい他のアプリケーションに応じて、または単純に自分のアプリケーションのパフォーマンスと人間の可読性がどの程度優れているかに応じて、別のコーデックを使用することを選択できます。
IPLD は、プロトコルの上位 3 つの層を実装します。
オブジェクト、ファイル、名前
オブジェクトレイヤー
- IPFS のデータは、マークル有向非巡回グラフ (マークル DAG) の構造で編成されます。ノードはオブジェクトと呼ばれ、データまたは他のオブジェクトへのリンクを含めることができます。リンクは、ソースに埋め込まれたターゲット データの暗号化されたハッシュです。これらのデータ構造は、コンテンツのアドレス指定、データ改ざん耐性、重複排除など、多くの有用な特性を提供します。
ファイル層- Merkle DAG 上で Git のようなバージョン管理システムをモデル化するために、IPFS は次のオブジェクトを定義します。
BLOB データ ブロック: BLOB は、データ ブロックを表す可変サイズのデータ ブロック (リンクなし) です。
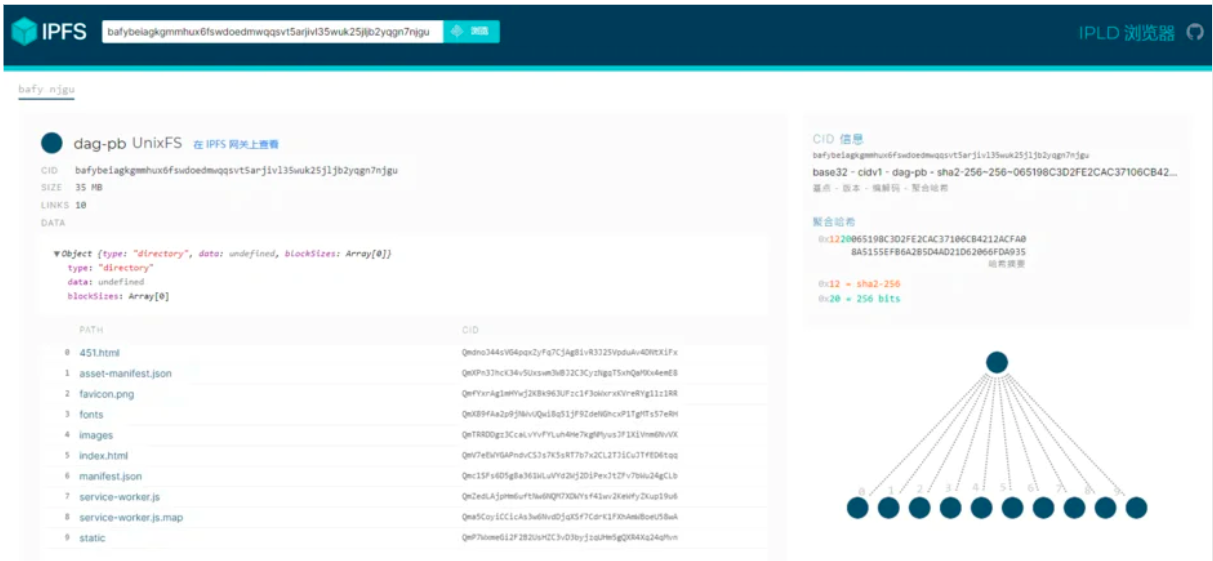
list: BLOB またはその他のリストを整然と整理するために使用され、通常はファイルを表します。commit: Git の commit に似ており、オブジェクトのバージョン履歴のスナップショットを表します。
Filecoin
名前付けレイヤー- オブジェクトが変更されるたびにそのハッシュ値が変更されるため、ハッシュ値のマッピングが必要です。 IPNS (Inter Planetary Namespace System) は、各ユーザーに変更可能な名前空間を割り当て、ユーザーの秘密鍵で署名されたパスにオブジェクトを公開して、オブジェクトの信頼性を検証できます。 URL に似ています。
IPLDの表示に対応:





