원저자: Mohamed Baioumy Alex Cheema
원곡: BeWater

전체 보고서의 길이로 인해 출판을 위해 두 부분으로 나누었습니다. 이전 글에서 저자는 AI x Crypto의 핵심 프레임워크와 구체적인 사례, 빌더를 위한 기회 등을 소개했습니다. 이것은 주로 기계 학습의 작업 모드와 과제를 설명하는 다음 기사입니다. 번역 전문을 보시려면 여기를 클릭하세요링크。
A. 머신러닝은 어떻게 작동하나요?
인공지능(AI)과 암호화폐의 교차점을 탐구하기 전에 먼저 인공지능 분야의 몇 가지 개념을 소개하는 것이 중요합니다. 이 보고서는 암호화폐 분야의 독자를 대상으로 작성되었기 때문에 모든 독자가 인공 지능과 기계 학습 개념을 깊이 이해하는 것은 아닙니다. 개념을 이해하는 것은 독자들이 인공 지능과 암호화폐의 교차점에서 어떤 아이디어가 실제 관심을 갖는지 평가하고 프로젝트의 기술적 위험을 정확하게 평가할 수 있도록 하는 데 중요합니다. 이 섹션에서는 인공지능의 개념에 중점을 두고 있으며, 또한 인공지능과 암호화폐의 관계에 대해서도 중점적으로 다룹니다.

이 섹션에서 다루는 주제 개요:
머신 러닝(ML)은 기계가 명시적으로 프로그래밍하지 않고도 데이터를 기반으로 결정을 내릴 수 있는 인공 지능의 한 분야입니다.
ML 프로세스는 데이터, 훈련, 추론의 세 단계로 나뉩니다.
훈련 모델은 계산 비용이 매우 많이 드는 반면 추론은 상대적으로 저렴합니다.
학습에는 지도 학습, 비지도 학습, 강화 학습의 세 가지 주요 유형이 있습니다.
지도 학습은 교사가 제공한 예시를 통해 학습하는 것을 말합니다. 교사는 모델에게 개 사진을 보여주고 이것이 개라고 말할 수 있습니다. 그러면 모델은 개를 다른 동물과 구별하는 방법을 학습할 수 있습니다.
그러나 LLM(예: GPT-4 및 LLaMa)과 같은 많은 인기 모델은 비지도 학습을 통해 교육됩니다. 이 학습 모드에서는 강사가 어떠한 지침이나 예시도 제공하지 않습니다. 대신 모델은 데이터에서 패턴을 발견하는 방법을 학습합니다.
강화 학습(시행 오류 학습)은 주로 로봇 제어 및 게임(예: 체스 또는 바둑)과 같은 지속적인 의사 결정 작업에 사용됩니다.
인공 지능 및 기계 학습
1956년, 당시 가장 총명한 사람들 중 일부가 세미나를 위해 모였습니다. 그들의 목표는 지능의 일반 원칙을 제안하는 것이었습니다. 그들은 다음과 같이 지적했습니다.
"학습의 모든 측면이나 지능의 다른 특성은 매우 정확하게 설명될 수 있으므로 이를 시뮬레이션하기 위한 기계를 만들 수 있습니다."
인공지능 개발 초기, 연구자들은 낙관적인 태도로 가득 차 있었습니다. 어떤 의미에서 그들의 목표는 야심찬 인공일반지능(AGI)이다. 이제 우리는 이 연구자들이 일반 지능을 갖춘 AI 에이전트를 만들지 못했다는 것을 알고 있습니다. 1970~80년대 인공지능 연구자들도 마찬가지였다. 그 기간 동안 인공지능 연구자들은 개발을 시도했다."지식 기반 시스템"。
지식 기반 시스템의 핵심 아이디어는 기계에 대한 매우 정확한 규칙을 작성할 수 있다는 것입니다. 기본적으로 우리는 전문가로부터 매우 구체적이고 정확한 도메인 지식을 추출하고 이를 기계가 사용할 규칙 형식으로 작성합니다. 그런 다음 기계는 이러한 규칙을 사용하여 추론하고 올바른 결정을 내릴 수 있습니다. 예를 들어, 우리는 매그너스 칼슨(Magnus Carlson)으로부터 체스 게임의 모든 원리를 추출한 다음 체스 게임을 위한 인공 지능을 구축하려고 시도할 수 있습니다.
하지만 이렇게 하는 것은 매우 어려우며, 가능하더라도 이러한 규칙을 만드는 데는 많은 수작업이 필요합니다. 개를 식별하는 규칙을 기계에 어떻게 작성하는지 상상해 보세요. 기계가 픽셀을 갖는 것에서 개가 무엇인지 아는 것으로 어떻게 발전합니까?
인공 지능의 최신 발전은 다음과 같은 그룹에서 나옵니다."기계 학습"나뭇가지. 이 모델에서는 기계에 대한 정확한 규칙을 작성하는 대신 데이터를 사용하고 기계가 그로부터 학습하도록 합니다. GPT-4, iPhone의 FaceID, 게임 봇, Gmail 스팸 필터, 의료 진단 모델, 자율 주행 자동차 등 기계 학습을 사용하는 최신 AI 도구는 어디에나 있습니다.
머신러닝 파이프라인
머신러닝 파이프라인은 세 가지 주요 단계로 나눌 수 있습니다. 데이터가 있으면 모델을 훈련해야 하며, 그런 다음 모델을 사용하면 됩니다. 모델을 사용하는 것을 추론이라고 합니다. 따라서 세 단계는 데이터, 훈련, 추론입니다.
높은 수준에서 데이터 단계에는 관련 데이터를 찾고 이를 전처리하는 작업이 포함됩니다. 예를 들어, 개를 분류하는 모델을 구축하려면 모델이 무엇이 개이고 무엇이 개가 아닌지 알 수 있도록 개와 다른 동물의 사진을 찾아야 합니다. 그런 다음 모델이 올바르게 학습할 수 있도록 데이터를 처리하고 올바른 형식인지 확인해야 합니다. 예를 들어, 이미지의 크기가 일정해야 할 수도 있습니다.
두 번째 단계는 훈련으로, 데이터를 사용하여 모델이 어떤 모습이어야 하는지 학습합니다. 모델 내부의 방정식은 무엇입니까? 신경망의 가중치는 무엇입니까? 매개변수는 무엇입니까? 계산은 어떻게 진행되고 있나요? 모델이 좋으면 성능을 테스트한 후 사용할 수 있습니다. 이것은 우리를 세 번째 단계로 이끈다.
세 번째 단계는 추론이라고 하며, 여기서는 신경망만 사용합니다. 예를 들어 신경망에 입력을 제공하고 추론을 통해 출력을 생성할 수 있는지 질문해 보세요.
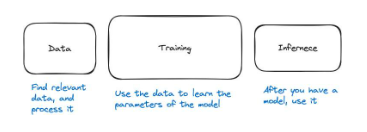
그림 28: 머신러닝 파이프라인의 세 가지 주요 단계는 데이터, 훈련, 추론입니다.
데이터
이제 각 단계를 자세히 살펴보겠습니다. 첫째: 데이터. 광범위하게 말하면 이는 데이터를 수집하고 전처리해야 함을 의미합니다.
예를 살펴보겠습니다. 피부과 의사(피부 질환 치료를 전문으로 하는 의사)가 사용할 수 있는 모델을 구축하려는 경우. 먼저 다양한 얼굴에 대한 데이터를 수집해야 합니다. 그런 다음 전문 피부과 의사에게 피부 상태가 있는지 평가하도록 요청합니다. 지금은 많은 어려움이 발생할 수 있습니다. 첫째, 우리가 보유한 모든 데이터에 얼굴이 포함되어 있으면 모델이 신체의 다른 부분에 있는 피부 상태를 식별하기 어려울 것입니다. 둘째, 데이터가 편향될 수 있습니다. 예를 들어 대부분의 데이터는 하나의 피부색이나 색조에 대한 사진일 수 있습니다. 셋째, 피부과 의사는 실수를 할 수 있으며, 이는 잘못된 데이터를 얻는다는 의미입니다. 넷째, 우리가 획득한 데이터는 개인정보를 침해할 수 있습니다.

2장에서 더 심층적인 데이터 문제를 다룰 것입니다. 그러나 이를 통해 좋은 데이터를 수집하고 전처리하는 것이 상당히 어려울 수 있다는 아이디어를 얻을 수 있습니다.

그림 29: 두 가지 인기 있는 데이터 세트의 도식적 표현. MNIST에는 손으로 쓴 숫자가 포함되어 있고 ImageNet에는 다양한 카테고리의 주석이 달린 수백만 개의 이미지가 포함되어 있습니다.
머신러닝 연구에는 유명한 데이터 세트가 많이 있습니다. 일반적으로 사용되는 것들은 다음과 같습니다;
MNIST 데이터세트
설명: 회색조 이미지 형식의 70,000개의 손으로 쓴 숫자(0-9)를 포함합니다.
사용 사례: 주로 컴퓨터 비전의 필기 숫자 인식 기술에 사용됩니다. 교육 현장에서 일반적으로 사용되는 초보자 친화적인 데이터 세트입니다.
ImageNet
설명: 20,000개 이상의 카테고리로 분류된 1,400만 개 이상의 이미지를 포함하는 대규모 데이터베이스입니다.
사용 사례: 객체 감지 및 이미지 분류 알고리즘의 교육 및 벤치마킹. 매년 개최되는 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)는 컴퓨터 비전과 딥 러닝 기술의 발전을 촉진하는 중요한 행사였습니다.
IMDb 댓글:
설명: IMDb의 50,000개 영화 리뷰가 훈련과 테스트라는 두 그룹으로 나누어져 있습니다. 각 그룹에는 동일한 수의 긍정적인 의견과 부정적인 의견이 포함됩니다.
사용 사례: 자연어 처리(NLP)의 감정 분석 작업에 널리 사용됩니다. 텍스트에 표현된 정서(긍정/부정)를 이해하고 분류할 수 있는 모델 개발에 도움이 됩니다.
좋은 모델을 훈련하려면 대규모의 고품질 데이터 세트에 액세스하는 것이 매우 중요합니다. 그러나 이는 특히 소규모 조직이나 개인 검색자의 경우 어려울 수 있습니다. 데이터는 매우 가치가 높기 때문에 대규모 조직에서는 경쟁 우위를 제공한다는 이유로 데이터를 공유하지 않는 경우가 많습니다.

기차
파이프라인의 두 번째 단계는 모델을 학습시키는 것입니다. 그렇다면 모델을 학습시킨다는 것은 정확히 무엇을 의미할까요? 먼저, 예를 살펴보겠습니다. 훈련이 완료된 후의 기계 학습 모델에는 일반적으로 두 개의 파일만 있습니다. 예를 들어 LLaMa 2(GPT-4와 유사한 대규모 언어 모델)에는 두 개의 파일이 있습니다.
매개변수, 숫자를 포함한 140GB 파일.
run.c 및 간단한 파일(약 500줄의 코드).
첫 번째 파일에는 LLaMa 2 모델의 모든 매개변수가 포함되어 있고, run.c에는 추론을 수행하는 방법(모델 사용)에 대한 지침이 포함되어 있습니다. 이러한 모델은 신경망입니다.
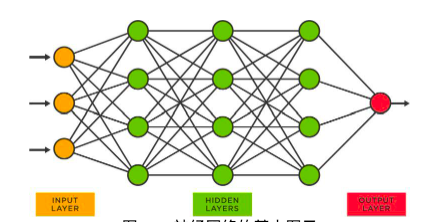
그림 30: 신경망의 기본 다이어그램
위와 같은 신경망에서는 각 노드에 여러 개의 숫자가 있습니다. 이 숫자를 매개변수라고 하며 파일 매개변수(놀랍게도!)에 저장됩니다. 이러한 매개변수를 얻는 과정을 훈련이라고 합니다. 다음은 프로세스에 대한 높은 수준의 요약입니다.
숫자(0부터 9까지)를 인식하도록 모델을 훈련한다고 상상해 보세요. 먼저 데이터를 수집합니다(이 경우 MNIST 데이터세트를 사용할 수 있습니다). 그런 다음 모델 학습을 시작합니다.
우리는 첫 번째 데이터 포인트를 취합니다."5"。
그런 다음 이미지를 변환합니다("5")이 네트워크로 전달됩니다. 네트워크는 입력 이미지에 대해 수학적 연산을 수행합니다.
네트워크는 0에서 9 사이의 숫자를 출력합니다. 이 출력은 해당 이미지에 대한 현재 네트워크의 예측입니다.
지금은 두 가지 상황이 있습니다. 네트워크가 옳았거나(예측했거나"5") 또는 잘못되었습니다(다른 숫자).
예측한 숫자가 정확하다면 우리는 아무것도 할 필요가 없습니다.
예측된 숫자가 잘못된 경우 모든 매개변수를 약간 수정하여 네트워크로 돌아갑니다.
이렇게 작은 변경을 한 후 다시 시도해 보겠습니다. 기술적으로 이제 네트워크에 새로운 매개변수가 있으므로 예측이 달라집니다.
네트워크가 대부분 정확해질 때까지 모든 데이터 포인트에 대해 이 작업을 수행합니다.
이 프로세스는 본질적으로 순차적입니다. 먼저 전체 네트워크를 통해 데이터 포인트를 전달하고 예측 결과가 어떻게 나오는지 확인한 다음 모델의 가중치를 업데이트합니다.
훈련 과정은 더욱 포괄적일 수 있습니다. 먼저 모델 아키텍처를 선택해야 합니다. 어떤 유형의 신경망을 선택해야 합니까? 모든 기계 학습 모델이 신경망인 것은 아닙니다. 둘째, 어떤 아키텍처가 우리에게 가장 적합한지 또는 적어도 우리가 가장 적합하다고 생각하는 아키텍처를 결정한 후 훈련 프로세스를 결정해야 합니다. 예를 들어, 어떤 순서로 데이터를 네트워크에 전달할까요?
셋째, 하드웨어 설정이 필요합니다. 어떤 종류의 하드웨어(CPU, GPU, TPU)를 사용해야 합니까? 어떻게 훈련하나요?
마지막으로 모델을 훈련하면서 모델이 정말 좋은지 확인하고 싶습니다. 훈련이 끝나면 이 모델이 원하는 결과를 제공하는지 테스트하고 싶습니다. 스포일러(실제로는 스포일러가 아님), 모델 교육에는 계산 비용이 매우 많이 듭니다. 작은 비효율성에도 막대한 비용이 발생합니다. 나중에 살펴보겠지만, 특히 LLM과 같은 대규모 모델의 경우 비효율적인 교육으로 인해 수백만 달러의 비용이 발생할 수 있습니다.
2장에서는 훈련 모델의 과제에 대해 다시 자세히 논의할 것입니다.
추리
기계 학습 파이프라인의 세 번째 단계는 모델을 사용하는 추론입니다. ChatGPT를 사용하고 응답을 받으면 모델이 추론을 수행하고 있는 것입니다. 내 얼굴로 iPhone 잠금을 해제하면 Face ID 모델이 내 얼굴을 인식하고 휴대폰을 엽니다. 모델이 추론을 수행했습니다. 데이터는 이미 존재하고 모델은 훈련되었습니다. 이제 모델이 훈련되었으므로 사용할 수 있습니다. 이를 사용하는 것이 추론입니다.
엄밀히 말하면 추론은 훈련 단계에서 네트워크가 수행하는 예측과 동일합니다. 데이터 포인트가 네트워크를 통과하고 예측이 이루어진다는 점을 기억하세요. 그런 다음 모델 매개변수는 예측 품질에 따라 업데이트됩니다. 추론도 같은 방식으로 작동합니다. 따라서 추론은 훈련에 비해 계산 비용이 매우 많이 듭니다. LLaMa 교육에는 수천만 달러의 비용이 들 수 있지만 한 번에 추론하는 데 드는 비용은 극히 일부에 불과합니다.
학습에 비해 계산 비용이 저렴합니다. LLaMa 교육에는 수천만 달러의 비용이 들 수 있지만 추론을 실행하는 데 드는 비용은 극히 일부에 불과합니다.

추론 과정에는 여러 단계가 있습니다. 먼저, 실제 생산에 사용하기 전에 테스트를 해야 합니다. 모델의 품질을 검증하기 위해 훈련 단계에서 볼 수 없는 데이터에 대해 추론을 수행합니다. 둘째, 모델을 배포할 때 몇 가지 하드웨어 및 소프트웨어 요구 사항이 있습니다. 예를 들어 내 iPhone에 얼굴 인식 모델이 있는 경우 해당 모델이 Apple 서버에 있을 수 있습니다. 하지만 이제는 휴대전화를 잠금 해제할 때마다 인터넷에 접속하여 Apple 서버에 요청을 보낸 다음 해당 모델에 대해 추론을 수행해야 하기 때문에 이는 매우 불편합니다. 그러나 언제든지 이 기술을 사용하려면 얼굴 인식을 지원하는 모델이 휴대폰에 있어야 합니다. 즉, 해당 모델이 iPhone의 하드웨어 유형과 호환되어야 함을 의미합니다.
마지막으로 실제로 우리는 이 모델을 유지해야 합니다. 우리는 끊임없이 조정해야 합니다. 우리가 훈련하고 사용하는 모델이 항상 완벽한 것은 아닙니다. 하드웨어 요구 사항과 소프트웨어 요구 사항도 끊임없이 변화하고 있습니다.
기계 학습 파이프라인은 반복적입니다.
지금까지 저는 이 파이프라인을 순차적으로 발생하는 세 단계로 설계했습니다. 데이터를 얻고, 데이터를 처리하고, 데이터를 정리하고, 모든 것이 원활하게 진행된 다음 모델을 훈련하고, 모델이 훈련되면 추론을 수행합니다. 이것은 실제 머신러닝의 아름다운 그림입니다. 실제로 머신러닝에는 많은 반복이 필요합니다. 따라서 아래 그림과 같이 체인이 아니고 여러개의 루프로 되어있습니다.
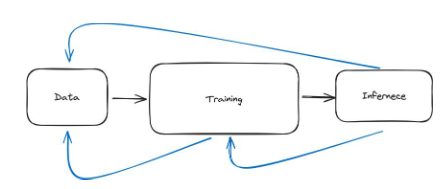
그림 31: 머신러닝 파이프라인은 데이터, 훈련, 추론의 세 단계로 구성된 체인으로 시각적으로 이해될 수 있습니다. 그러나 실제로는 파란색 화살표로 표시된 것처럼 프로세스가 더 반복적입니다.
이를 이해하기 위해 몇 가지 예를 들어볼 수 있습니다. 예를 들어, 모델에 대한 데이터를 수집한 다음 훈련을 시도할 수 있습니다. 훈련 과정에서 우리는 필요한 데이터의 양이 더 많아야 한다는 것을 알게 될 것입니다. 이는 훈련을 일시 중지하고 데이터 단계로 돌아가서 더 많은 데이터를 얻어야 함을 의미합니다. 데이터를 다시 처리하거나 어떤 형태로든 데이터 확대를 수행해야 할 수도 있습니다. 데이터 증대는 데이터를 개조하여 오래된 것을 새로운 것으로 만드는 것과 같습니다. 당신에게 사진 앨범이 있고 그것을 더 흥미롭게 만들고 싶다고 상상해보십시오. 각 사진의 복사본을 여러 개 만들었지만 각 복사본에서 약간의 변경 사항을 적용했습니다. 예를 들어 사진 한 장을 회전하거나, 다른 사진을 확대하거나, 다른 조명의 크기를 변경했을 수도 있습니다. 이제 사진 앨범에 더 많은 변경 사항이 있지만 실제로는 새로운 사진을 찍지 않았습니다. 예를 들어, 개를 인식하도록 모델을 훈련하는 경우 각 사진을 가로로 뒤집어서 모델에 제공할 수도 있습니다. 또는 아래와 같이 사진 속 강아지의 자세를 변경합니다. 모델에 관한 한 이는 데이터 세트를 늘리지만 더 많은 데이터를 수집하기 위해 현실 세계로 나가지는 않습니다.


그림 32: 데이터 증대 예시. 원본 데이터 포인트의 다중 포인트 증폭으로 더 많은 고유한 데이터 포인트를 수집하기 위해 전 세계를 여행할 필요가 없습니다.
두 번째로 더 분명한 반복의 예는 실제로 모델을 훈련한 다음 이를 실제로 사용할 때(예: 추론을 위해) 모델이 실제로 제대로 수행되지 않거나 편향되어 있음을 발견할 수 있다는 것입니다. 이는 추론 프로세스를 중단하고, 편향 및 정당화와 같은 문제를 설명하기 위해 모델을 다시 훈련해야 함을 의미합니다.
세 번째이자 매우 일반적인 단계는 실제로 모델을 사용하고 나면(추론 수행) 추론 자체가 새로운 데이터를 생성하기 때문에 결국 데이터 단계를 수정하게 된다는 것입니다. 예를 들어 스팸 필터를 구축한다고 상상해 보세요. 먼저, 데이터를 수집해야 합니다. 이 예의 데이터는 스팸 및 스팸이 아닌 이메일의 집합입니다. 모델을 훈련하고 실제로 사용할 때 받은 편지함에 스팸 이메일이 도착할 수 있습니다. 이는 모델에 실수가 있다는 의미입니다. 스팸으로 분류되지는 않지만 스팸입니다. 따라서 Gmail 사용자가 선택하면"이 이메일은 스팸입니다", 새로운 데이터 포인트가 생성됩니다. 그 후, 이러한 모든 새로운 데이터 포인트는 데이터 단계로 이동하며, 조금 더 훈련을 수행하여 모델의 성능을 향상시킬 수 있습니다.
또 다른 예로 체스를 두는 AI를 상상해보세요. 체스를 두기 위해 인공지능을 훈련시키는 데 필요한 데이터는 수많은 체스 게임과 누가 이기고 지는지에 대한 결과입니다. 하지만 이 모델을 실제로 체스에 사용하면 인공지능을 위한 더 많은 데이터가 생성됩니다. 이는 추론 단계의 데이터로 돌아가서 이러한 새로운 데이터 포인트를 사용하여 모델을 다시 개선할 수 있음을 의미합니다. 추론과 데이터를 연결하는 이러한 아이디어는 많은 상황에 적용됩니다.
이 섹션에서는 매우 반복적인 기계 학습 모델 구축 프로세스에 대한 높은 수준의 이해를 제공하기 위해 작성되었습니다. 그렇지 않아"아, 우리는 데이터를 얻고, 한 번에 모델을 훈련한 다음, 프로덕션에 적용합니다."。

기계 학습의 유형
세 가지 주요 머신러닝 모델을 소개하겠습니다.
지도 학습:"선생님, 어떻게 하는지 가르쳐 주세요"
비지도 학습:"숨겨진 패턴을 찾아보세요
강화 학습:"한번 시도해보고 어떤 것이 효과가 있는지 확인하세요"
지도 학습
"선생님, 어떻게 하는지 가르쳐 주세요"
당신이 아이들에게 고양이와 개를 구별하도록 가르치고 있다고 상상해 보십시오. 당신(모든 것을 아는 선생님)은 고양이와 개 사진을 많이 보여주며 매번 어느 것이 어느 것인지 말해줍니다. 결국 아이들은 스스로 분별하는 법을 배웁니다. 이는 머신러닝에서 지도 학습이 작동하는 방식과 거의 같습니다.
지도 학습에서 우리는 많은 데이터(예: 고양이와 개 사진)를 갖고 있으며 이미 답을 알고 있습니다(선생님이 어느 것이 개이고 어느 것이 고양이인지 알려줌). 우리는 이 데이터를 사용하여 모델을 훈련합니다. 모델은 많은 예를 살펴보고 교사를 모방하는 방법을 효과적으로 학습합니다.
이 예에서 각 이미지는 원시 데이터 포인트입니다. 정답은 (개 또는 고양이) 라고 합니다"상표". 따라서 이는 레이블이 지정된 데이터 세트입니다. 각 데이터 포인트에는 원시 이미지와 레이블이 포함되어 있습니다.
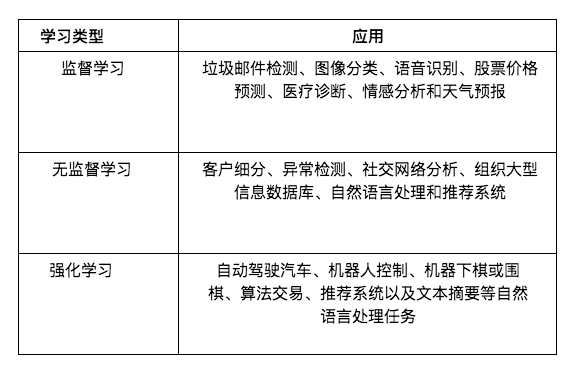
이 방법은 개념이 간단하고 기능이 강력합니다. 의료 진단, 자율 주행 자동차, 주가 예측에 지도 학습 모델을 사용하는 애플리케이션이 많이 있습니다.
그러나 상상할 수 있듯이 이 접근 방식은 많은 어려움에 직면해 있습니다. 예를 들어, 우리는 많은 데이터를 얻어야 할 뿐만 아니라 라벨도 필요합니다. 이것은 매우 비쌀 수 있습니다.Scale.ai이와 같은 회사는 이와 관련하여 귀중한 서비스를 제공합니다. 데이터 주석은 견고성에 많은 문제를 야기합니다. 데이터에 라벨을 붙이는 사람이 실수를 할 수도 있고 라벨에 동의하지 않을 수도 있습니다. 인간으로부터 수집된 모든 태그 중 20%가 사용할 수 없는 것은 드문 일이 아닙니다.

비지도 학습
"숨은 패턴만 찾아보세요"
당신에게 다양한 과일이 담긴 큰 바구니가 있지만 그 모든 과일에 대해 잘 알지 못한다고 상상해 보십시오. 모양, 크기, 색상, 질감, 심지어 냄새에 따라 카테고리로 분류하기 시작합니다. 각 과일의 이름은 잘 모르지만 일부 과일은 서로 비슷하다는 것을 알 수 있습니다. 즉, 데이터에서 몇 가지 패턴을 발견합니다.
이 상황은 머신러닝의 비지도 학습과 유사합니다. 비지도 학습에서는 모델에 많은 데이터(예: 다양한 과일의 조합)를 제공하지만 모델에 각 데이터가 무엇인지 알려주지 않습니다(과일에 라벨을 지정하지 않음). 그런 다음 모델은 이 모든 데이터를 조사하고 자체적으로 패턴이나 그룹화를 찾으려고 시도합니다. 색상, 모양, 크기 또는 관련성이 있다고 판단되는 기타 특성을 기준으로 과일을 그룹화할 수 있습니다. 그러나 모델에서 찾은 기능이 항상 관련성이 있는 것은 아닙니다. 이로 인해 2장에서 살펴보겠지만 여러 가지 문제가 발생합니다.
예를 들어 모델은 바나나와 질경이가 둘 다 길고 노란색이기 때문에 하나의 그룹으로 그룹화할 수 있고, 사과와 토마토는 둘 다 둥글고 빨간색일 가능성이 높기 때문에 다른 그룹으로 그룹화할 수 있습니다. 여기서 핵심은 모델이 사전 지식이나 라벨 없이 이러한 그룹화를 파악한다는 것입니다. 마치 알려지지 않은 과일을 관찰 가능한 특성을 기반으로 여러 그룹으로 그룹화하는 것과 마찬가지로 데이터 자체에서 학습합니다.
비지도 학습은 LLM(대형 언어 모델)과 같은 널리 사용되는 많은 기계 학습 모델의 중추입니다. ChatGPT는 라벨을 제공하여 각 문장을 말하는 방법을 인간에게 가르칠 필요가 없습니다. 단순히 언어 데이터의 패턴을 분석하고 다음 단어를 예측하는 방법을 학습합니다.
다른 많은 강력한 생성 AI 모델은 비지도 학습에 의존합니다. 예를 들어 GAN(Generative Adversarial Networks)을 사용하면 사람이 존재하지 않더라도 얼굴을 생성할 수 있습니다.https://thispersondoesnotexist.com/을 참조하세요.

그림 33: 인공지능이 생성한 이미지https://thispersondoesnotexist.com

그림 34: 두 번째 AI 생성 사진은https://thispersondoesnotexis t.com
위 이미지는 인공지능이 생성한 이미지입니다. 우리는 이 모델을 가르치지 않았습니다."얼굴이 뭐야?". 수많은 얼굴에 대해 훈련을 받았으며 영리한 아키텍처를 통해 이 모델을 사용하여 실제처럼 보이는 얼굴을 생성할 수 있습니다. 생성 AI의 등장과 모델의 개선으로 인해 콘텐츠를 검증하는 것이 점점 더 어려워지고 있습니다.

강화 학습(RL)
"한번 시도해보고 어떤 것이 효과가 있는지 확인하세요"또는"시행착오를 통해 배워라"
공을 가져오는 것과 같은 새로운 행동을 개에게 가르치고 있다고 상상해 보십시오. 개가 공을 향해 달려가거나 공을 집는 등 주인이 원하는 것과 비슷한 행동을 할 때마다 간식을 주세요. 개가 반대 방향으로 달리는 등 관련 없는 행동을 하면 음식을 얻지 못할 것입니다. 점차적으로, 개는 공을 집으면 맛있는 음식을 얻을 수 있다는 것을 알게 되어 계속해서 공을 줍습니다. 이것이 바로 머신러닝 분야의 강화학습(RL)입니다.
RL에는 다양한 행동(개가 다양한 행동을 시도하는 것과 같은)을 시도하여 결정을 내리는 방법을 배우는 컴퓨터 프로그램이나 에이전트(개와 같은)가 있습니다. 에이전트가 좋은 행동(예: 공 집기)을 수행하면 보상(음식)을 받고, 나쁜 행동을 수행하면 보상을 받지 못합니다. 시간이 지남에 따라 에이전트는 보상을 받는 좋은 일을 더 많이 하고 보상을 받지 못하는 나쁜 일을 줄이는 방법을 배웁니다. 공식적으로 이는 최대화 보상 기능입니다.
멋진 점은 상담원이 시행착오를 통해 스스로 모든 것을 알아낸다는 것입니다. 이제 체스를 두기 위해 AI를 구축하려는 경우 AI는 처음에 임의의 움직임을 시도할 수 있습니다. 결국 게임에서 승리하면 AI가 보상을 받습니다. 그런 다음 모델은 더 많은 승리를 거두는 방법을 학습합니다.
이는 많은 문제, 특히 지속적인 의사결정이 필요한 문제에 적용될 수 있습니다. 예를 들어, RL 방법은 로봇 공학 및 제어, 체스 또는 바둑(예: AlphaGo) 및 알고리즘 거래에 사용될 수 있습니다.
RL 방법은 많은 어려움에 직면해 있습니다. 우선, 상담원이 처리하는 데 시간이 오래 걸릴 수 있습니다."배우다"의미있는 전략. 이는 AI가 체스를 학습하는 데 적합합니다. 하지만 AI가 어떤 것이 작동하는지 확인하기 위해 무작위 조치를 취하기 시작하면 개인 자금을 AI 알고리즘 거래에 투입하시겠습니까? 아니면 로봇이 무작위로 행동하기 시작하면 집에 살도록 허용하시겠습니까?

그림 35: 다음은 훈련 중 일부 강화 학습 에이전트에 대한 비디오입니다.로봇그리고시뮬레이션 로봇
다음은 각 유형의 머신러닝에 대한 적용 사례에 대한 간략한 설명입니다.
B. 머신러닝이 직면한 과제
이 장에서는 기계 학습 분야의 문제에 대한 개요를 제공합니다. 우리는 이 영역의 특정 문제를 선택적으로 확장할 것입니다. 이는 두 가지 이유로 수행됩니다: 1) 현장의 과제에 대한 간결하고 포괄적인 개요를 제공하고 매우 긴 보고서가 될 수 있는 미묘한 차이를 설명하기 위해; 2) 암호화폐와의 교차점을 논의할 때 관련 문제에 중점을 둘 것입니다. . 하지만 이 섹션 자체는 인공지능 관점에서만 작성되었습니다. 즉, 이 섹션에서는 암호화 방법에 대해 논의하지 않습니다.
이 섹션에서 다루는 주제 개요:
편견에서 접근성까지 데이터는 엄청난 과제에 직면해 있습니다. 또한 데이터 수준의 악의적인 공격은 머신러닝 모델의 잘못된 판단으로 이어질 수도 있습니다.
모델 충돌은 모델(예: GPT-X)이 합성 데이터에 대해 훈련될 때 발생합니다. 이로 인해 돌이킬 수 없는 손상이 발생할 수 있습니다.
데이터 라벨링은 비용이 많이 들고 느리며 신뢰할 수 없습니다.
아키텍처에 따라 기계 학습 모델 학습과 관련된 많은 과제가 있습니다.
모델 병렬화는 통신 오버헤드와 같은 큰 문제를 야기합니다.
베이지안 모델은 불확실성을 정량화하는 데 사용될 수 있습니다. 예: 추론을 할 때 모델은 그것이 얼마나 확실한지 반환합니다(예: 80% 확실성).
LLM은 환각 및 훈련 어려움과 같은 특별한 문제에 직면해 있습니다.
데이터 문제
데이터는 모든 유형의 기계 학습 모델의 핵심입니다. 그러나 사용하는 방법에 따라 데이터의 요구 사항과 크기가 달라집니다. 지도학습이든 비지도학습이든 원본 데이터(레이블이 지정되지 않은 데이터)가 필요합니다.
비지도 학습에는 원시 데이터만 있고 라벨링이 필요하지 않습니다. 이는 데이터 세트 라벨링과 관련된 많은 문제를 완화합니다. 그러나 비지도 학습에 필요한 원시 데이터는 여전히 많은 과제를 안고 있습니다. 여기에는 다음이 포함됩니다.
데이터 편향: 편향은 훈련 데이터가 시뮬레이션되는 실제 시나리오를 나타내지 않을 때 기계 학습에서 발생합니다. 이는 훈련 데이터에서 과소 대표되기 때문에 특정 인구통계학적 그룹에서 안면 인식 시스템의 성능이 저하되는 등 편향되거나 불공정한 결과로 이어질 수 있습니다.
불균형 데이터 세트: 훈련에 사용할 수 있는 데이터가 여러 범주에 고르게 분포되지 않는 경우가 많습니다. 예를 들어, 질병 진단 애플리케이션에서 질병이 없는 경우는 다음과 같을 수 있습니다."아픈"더 많은 경우가 있습니다. 이러한 불균형으로 인해 소수/계층에서 모델의 성능이 저하될 수 있습니다. 이 문제는 편견과는 다릅니다.
데이터의 품질과 양: 기계 학습 모델의 성능은 훈련 데이터의 품질과 양에 크게 좌우됩니다. 불충분하거나 품질이 낮은 데이터(예: 저해상도 이미지 또는 시끄러운 오디오 녹음)는 모델의 효과적인 학습 능력에 심각한 영향을 미칠 수 있습니다.
데이터 가용성: 대규모의 고품질 데이터 세트에 액세스하는 것은 특히 소규모 기관이나 개인 연구원의 경우 어려울 수 있습니다. 대규모 기술 회사는 이와 관련하여 이점을 갖는 경향이 있으며, 이는 기계 학습 모델 개발에 격차를 초래할 수 있습니다.

데이터 보안: 무단 액세스로부터 데이터를 보호하고 저장 및 사용 중에 데이터의 무결성을 보장하는 것이 중요합니다. 보안 취약성은 개인정보 보호에 해를 끼칠 뿐만 아니라 데이터 변조 및 모델 성능에 영향을 미칠 수도 있습니다.
개인 정보 보호 문제: 기계 학습에는 많은 양의 데이터가 필요하므로 이 데이터를 처리하면 특히 민감한 정보나 개인 정보가 포함된 경우 개인 정보 보호 문제가 발생할 수 있습니다. 데이터 개인 정보 보호를 보장한다는 것은 사용자 동의를 존중하고 데이터 유출을 방지하며 GDPR과 같은 개인 정보 보호 규정을 준수하는 것을 의미합니다. 이는 매우 어려울 수 있습니다(아래 예 참조).


그림 36: 데이터 개인 정보 보호와 관련된 특별한 문제는 기계 학습 모델의 특성에서 비롯됩니다. 일반 데이터베이스에서는 여러 사람의 항목을 가질 수 있습니다. 회사에서 이 정보를 삭제하라고 요청하는 경우 데이터베이스에서 해당 정보를 삭제하면 됩니다. 그러나 내 모델이 훈련되면 거의 전체 훈련 데이터에 대한 매개변수가 유지됩니다. 어떤 숫자가 훈련의 어떤 데이터베이스 항목에 해당하는지 명확하지 않습니다.
모델 충돌
비지도 학습에서 우리가 강조하고 싶은 특별한 과제는 모델 붕괴입니다.
존재하다이 기사, 저자는 흥미로운 실험을 수행했습니다. GPT-3.5 및 GPT-4와 같은 모델은 웹의 모든 데이터를 사용하여 학습됩니다. 그러나 이러한 모델은 현재 널리 사용되고 있으므로 1년 안에 인터넷상의 많은 양의 콘텐츠가 이러한 모델을 통해 생성될 것입니다. 이는 GPT-5 이상 모델이 GPT-4에서 생성된 데이터를 사용하여 학습된다는 의미입니다. 합성 데이터에 대한 모델 학습이 얼마나 효과적인가요? 그들은 합성 데이터에 대한 언어 모델 훈련으로 인해 결과 모델에 되돌릴 수 없는 결함이 발생한다는 사실을 발견했습니다. 논문 작성자는 다음과 같이 썼습니다. 우리는 인터넷에서 스크랩한 대규모 데이터에 대한 교육의 이점을 유지하려면 이 문제를 심각하게 받아들여야 함을 보여줍니다. LLM에서 생성한 콘텐츠가 인터넷에서 스크랩한 데이터에 나타나면 다음과 같습니다. 시간이 지남에 따라 사람과 시스템 간의 실제 상호 작용에 대해 수집된 데이터의 가치는 점점 더 높아질 것입니다."。

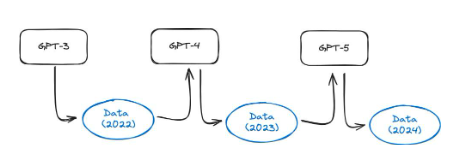
그림 37: 모델 붕괴의 개략도. AI 모델을 사용하여 점점 더 많은 인터넷 콘텐츠가 생성됨에 따라 차세대 모델의 훈련 세트에는 합성 데이터가 포함될 가능성이 높습니다.이 기사표시됨
이 현상은 LLM에만 국한된 것이 아니며 다양한 기계 학습 모델 및 생성 AI 시스템(예: 돌연변이 자동 인코더, 가우스 혼합 모델)에 영향을 미칠 수 있습니다.
이제 지도 학습에 대해 살펴보겠습니다. 지도 학습에서는 레이블이 지정된 데이터 세트가 필요합니다. 이는 원시 데이터 자체(개 사진)와 라벨("개"). 라벨은 모델 디자이너가 수동으로 선택하며 수동 주석과 자동화 도구의 조합을 통해 얻을 수 있습니다. 이는 실제로 많은 어려움을 야기합니다. 여기에는 다음이 포함됩니다.
주관성: 데이터의 레이블을 결정하는 것은 주관적일 수 있으며 이로 인해 모호함과 잠재적인 윤리적 문제가 발생할 수 있습니다. 어떤 사람이 적절한 라벨이라고 생각하는 것이 다른 사람에게는 다르게 보일 수 있습니다.
라벨의 차이: 동일한 사람(다른 사람은 물론이고)이 반복적으로 실행하면 다른 라벨이 제공될 수 있습니다. 이는 다음을 제공합니다"실제 라벨"노이즈 근사화로 인해 품질 보증 계층이 필요합니다. 예를 들어, 인간에게는 문장이 제시되고 해당 문장의 감정에 레이블을 지정하는 일을 담당할 수 있습니다("행복"、"슬퍼"......기다리다). 같은 사람이 똑같은 문장에 다르게 라벨을 붙이는 경우도 있습니다. 이렇게 하면 레이블에 차이가 발생하므로 데이터 세트의 품질이 저하됩니다. 실제로 태그의 20%를 사용할 수 없는 경우가 많습니다.

전문 주석자의 부족: 틈새 의료 애플리케이션의 경우 의미 있는 라벨 데이터를 대량으로 얻는 것이 어려울 수 있습니다. 이는 이러한 라벨을 제공할 수 있는 사람(의료 전문가)이 부족하기 때문입니다.
희귀 사건: 많은 사건의 경우 사건 자체가 매우 드물기 때문에 대량의 레이블이 지정된 데이터를 얻는 것이 어렵습니다. 예를 들어 유성을 발견하는 컴퓨터 비전 모델이 있습니다.
높은 비용: 대규모의 고품질 데이터 세트를 수집하려고 하면 비용이 엄청날 수 있습니다. 위의 문제로 인해 데이터세트에 주석을 추가해야 하는 경우 특히 비용이 많이 듭니다.
적대적 공격 처리, 라벨 이전 가능성 등 여전히 많은 문제가 남아 있습니다. 독자에게 데이터세트의 크기에 대한 직관을 제공하려면 아래 이미지를 살펴보세요. ImageNet과 같은 데이터 세트에는 1,400만 개의 레이블이 지정된 데이터 포인트가 포함되어 있습니다.
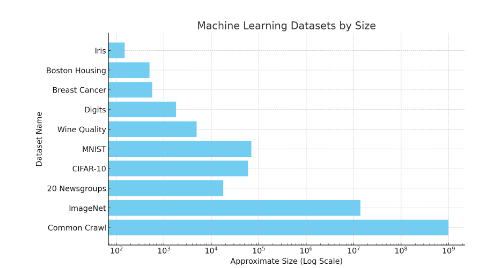
그림 38: 다양한 머신러닝 데이터 세트의 규모에 대한 개략도. Common Crawl의 대략적인 웹 페이지 수는 10억 개이므로 총 단어 수는 그 숫자를 훨씬 초과합니다. Iris와 같은 소규모 데이터세트에는 150개의 이미지가 포함되어 있습니다. MNIST에는 약 70,000개의 이미지가 있습니다. 이는 로그 척도임을 참고하세요.
강화 학습의 데이터 수집
강화 학습에서 데이터 수집은 독특한 과제입니다. 데이터가 미리 레이블이 지정된 정적 데이터인 지도 학습과 달리 강화 학습은 환경과의 상호 작용을 통해 생성된 데이터에 의존하며, 이는 종종 복잡한 시뮬레이션이나 실제 실험이 필요합니다. 이로 인해 몇 가지 과제가 발생합니다.
이 프로세스는 특히 물리적 로봇이나 복잡한 환경의 경우 리소스와 시간이 많이 소요될 수 있습니다. 로봇이 현실 세계에서 훈련된다면 시행착오를 통해 학습하게 되면 사고로 이어질 수 있습니다. 또는 훈련된 로봇이 시행착오를 통해 학습하도록 하는 것을 고려해보세요.
보상이 희박하고 지연됩니다. 에이전트는 의미 있는 피드백을 받기 전에 많은 작업을 탐색해야 하므로 효과적인 정책을 배우기가 어려울 수 있습니다.
수집된 데이터가 다양하고 대표적인지 확인하는 것이 중요합니다. 그렇지 않으면 상담원이 제한된 경험에 과도하게 적응하여 일반화하지 못할 수 있습니다. 탐색(새로운 작업 시도)과 활용(알려진 성공적인 작업 사용) 사이의 균형을 맞추면 데이터 수집 노력이 복잡해지며 유용한 데이터를 효과적으로 수집하려면 정교한 전략이 필요합니다.
데이터 수집이 추론과 직접적인 관련이 있다는 점은 강조할 가치가 있습니다. 체스를 두도록 강화 학습 에이전트를 훈련할 때 셀프 플레이를 사용하여 데이터를 수집할 수 있습니다. 자기 플레이는 진전을 이루기 위해 자신과 체스를 두는 것과 같습니다. 에이전트는 자신의 복사본과 대결하여 지속적인 학습 주기를 형성합니다. 이 접근 방식은 지속적으로 새로운 시나리오와 과제를 생성하고 에이전트가 다양한 경험을 통해 학습하는 데 도움이 되므로 데이터 수집에 적합합니다. 이 프로세스는 여러 시스템에서 병렬로 실행될 수 있습니다. 추론은 훈련에 비해 계산 비용이 저렴하므로 이 프로세스에 대한 하드웨어 요구 사항도 낮습니다. 셀프 플레이를 통해 데이터가 수집된 후 모든 데이터는 모델을 훈련하고 개선하는 데 사용됩니다.

적대적인 데이터 공격
데이터 중독 공격: 이 공격에서는 분류자를 속이기 위해 교란을 추가하여 훈련 데이터가 손상되어 잘못된 출력이 발생합니다. 예를 들어 누군가 스팸이 아닌 이메일에 스팸 요소를 추가할 수 있습니다. 이로 인해 이 데이터가 향후 스팸 필터 교육에 포함될 때 성능 저하가 발생합니다. 스팸이 아닌 상황에서 다음을 통해 추가할 수 있습니다."free"、"win"、"offer "또는"token"다른 단어를 사용하여 해결됩니다.
회피 공격: 공격자는 이전에 훈련된 분류자를 속이기 위해 배포 중에 데이터를 조작합니다. 회피 공격은 실제 응용 분야에서 가장 일반적입니다. 생체 인증 시스템용"스푸핑 공격"공격회피의 예시입니다.
적대적 공격: 모델을 속이려는 목적으로 합법적인 입력을 수정하거나 특별히 설계된 공격입니다."소음"오분류를 일으키게 됩니다. 아래 예를 살펴보세요. 팬더 이미지에 노이즈를 추가한 후 모델이 이를 긴팔원숭이로 분류합니다(99.3% 신뢰도).
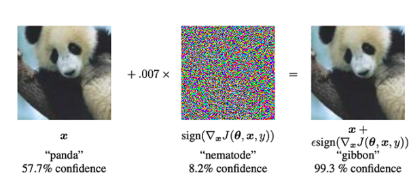
그림 39: 팬더 이미지에 특별한 유형의 노이즈를 추가함으로써 모델은 이미지가 팬더가 아니라 긴팔원숭이임을 미리 예측할 수 있습니다. 적대적 공격을 수행할 때 신경망(왼쪽)에 입력 이미지를 제공합니다. 그런 다음 경사하강법을 사용하여 노이즈 벡터(가운데)를 구성합니다. 이 노이즈 벡터는 입력 이미지에 추가되어 오분류를 유발합니다(오른쪽 이미지). (사진 출처: 본 기사의 그림 1)적대적 사례 해석 및 활용》논문의 그림 1)

훈련 과제
기계 학습 모델 교육에는 많은 어려움이 따릅니다. 이 섹션은 이러한 문제의 심각성을 설명하기 위한 것이 아닙니다. 대신, 우리는 독자들에게 문제의 유형과 병목 현상이 어디에 있는지에 대한 아이디어를 제공하려고 노력합니다. 이는 훈련된 모델과 암호화 기본 요소를 결합하는 프로젝트 아이디어를 평가할 수 있는 직관을 구축하는 데 도움이 될 것입니다.
비지도 학습 문제의 다음 예를 고려하십시오. 비지도 학습에는"선생님"라벨이나 안내 모델을 제공하세요. 대신 모델은 문제에서 숨겨진 패턴을 발견합니다. 고양이와 개의 데이터세트를 생각해 보세요. 모든 고양이와 개는 검은색과 흰색의 두 가지 색상으로 나옵니다. 비지도 학습 모델을 사용하면 데이터를 두 그룹으로 클러스터링하여 데이터에서 패턴을 찾을 수 있습니다. 이 모델에는 두 가지 유효한 접근 방식이 있습니다.
개들을 모두 모아라 고양이들을 모두 모아라
흰 동물을 모두 모으고 검은 동물을 모두 모으십시오.
기술적으로 둘 다 잘못된 것은 아닙니다. 모델이 찾은 패턴이 좋습니다. 그러나 우리가 요구하는 대로 정확하게 모델을 부트스트랩하는 것은 매우 어렵습니다.

그림 40: 고양이와 개를 분류하도록 훈련된 모델은 색상을 기준으로 동물을 함께 묶을 수 있습니다. 비지도 학습 모델을 실제로 지도하기 어렵기 때문입니다. Dalle-E를 활용한 인공지능으로 생성된 모든 이미지
이 예는 비지도 학습의 과제를 보여줍니다. 그러나 모든 유형의 학습에서는 훈련 중에 모델이 얼마나 잘 학습하는지 평가하고 잠재적인 개입을 할 수 있는 것이 중요합니다. 이렇게 하면 많은 돈을 절약할 수 있습니다.

대규모 모델을 훈련하는 데는 더 많은 어려움이 있습니다. 다음은 매우 짧은 목록입니다.
대규모 기계 학습 모델, 특히 딥 러닝 모델을 훈련하려면 많은 컴퓨팅 성능이 필요합니다. 이는 종종 비용이 많이 들고 전력 소모가 많은 고급 GPU 또는 TPU를 사용하는 것을 의미합니다.
이러한 컴퓨팅 요구 사항과 관련된 비용에는 하드웨어뿐만 아니라 이러한 시스템을 지속적으로, 때로는 몇 주 또는 몇 달 동안 실행하는 데 필요한 전력 및 인프라도 포함됩니다.
강화 학습은 훈련의 불안정성으로 알려져 있으며, 모델이나 훈련 과정의 작은 변화로 인해 결과가 크게 달라질 수 있습니다.
Adam과 같이 지도 학습에 사용되는 보다 안정적인 최적화 방법과 달리 강화 학습에는 모든 경우에 적용되는 일률적인 솔루션이 없습니다. 교육 과정은 종종 맞춤화되어야 하는데, 이는 시간이 많이 걸릴 뿐만 아니라 심층적인 전문 지식도 필요합니다.
강화 학습의 탐색-이용 딜레마는 효과적인 학습을 위해 올바른 균형을 찾는 것이 중요하지만 달성하기 어렵기 때문에 훈련을 복잡하게 만듭니다.
기계 학습의 손실 함수는 모델의 최적화 목표를 정의합니다. 잘못된 손실 함수를 선택하면 모델이 부적절하거나 최적이 아닌 동작을 학습하게 될 수 있습니다.
불균형 데이터 세트 또는 다중 클래스 분류와 같은 복잡한 작업에서는 올바른 손실 함수를 선택하고 때로는 맞춤 설계하는 것이 더욱 중요해집니다.
손실 함수는 애플리케이션의 실제 목표와 밀접하게 일치해야 하며, 이를 위해서는 데이터와 예상 결과에 대한 깊은 이해가 필요합니다.
강화 학습에서는 원하는 목표를 일관되고 정확하게 반영하는 보상 기능을 설계하는 것이 어렵습니다. 특히 보상이 부족하거나 지연되는 환경에서는 더욱 그렇습니다.
체스 게임에서 보상 기능은 간단할 수 있습니다. 승리하면 1점, 패배하면 0점입니다. 그러나 걷는 로봇의 경우 이 보상 함수는 다음을 포함하므로 매우 복잡해질 수 있습니다."앞을 바라보며 걷는다"、"팔을 함부로 휘두르지 마세요"및 기타 정보.

지도 학습에서는 심층 신경망의 블랙박스 특성으로 인해 심층 신경망과 같은 복잡한 모델의 예측을 주도하는 기능을 이해하는 것이 어렵습니다.
이러한 복잡성으로 인해 모델 디버깅, 의사 결정 프로세스 이해 및 정확성 향상이 어려워집니다.
이러한 모델의 복잡성으로 인해 민감하거나 규제된 도메인에 모델을 배포하는 데 중요한 예측 가능성과 설명 가능성에 대한 과제도 제기됩니다.
마찬가지로 훈련 모델과 관련된 과제는 매우 복잡한 주제입니다. 위의 내용을 통해 관련된 과제에 대한 아이디어를 얻을 수 있기를 바랍니다. 이 분야의 현재 과제에 대해 자세히 알아보려면 다음을 읽어 보시기 바랍니다.딥러닝 적용~의공개 질문》(Open Problems in Applied Deep Learning) 및 MLOpsMLOps 가이드)。
개념적으로 기계 학습 모델의 훈련은 순차적으로 발생합니다. 그러나 많은 경우 모델을 병렬로 훈련하는 것이 중요합니다. 이는 단순히 모델이 하나의 GPU에 적합하기에는 너무 크고 병렬 훈련을 통해 훈련 속도를 높일 수 있기 때문일 수 있습니다. 그러나 병렬 훈련 모델은 다음과 같은 중요한 과제를 안고 있습니다.
통신 오버헤드: 모델을 여러 프로세서로 분할하려면 이러한 장치 간의 지속적인 통신이 필요합니다. 특히 대형 모델의 경우 장치 간 데이터 전송에 시간이 많이 걸릴 수 있으므로 병목 현상이 발생할 수 있습니다.
로드 밸런싱: 모든 컴퓨팅 단위가 동일하게 활용되도록 보장하는 것은 어려운 일입니다. 불균형으로 인해 일부 장치는 유휴 상태가 되고 다른 장치는 과부하되어 전반적인 효율성이 저하될 수 있습니다.
메모리 제한: 각 프로세서 장치에는 제한된 양의 메모리가 있습니다. 이러한 제한을 초과하지 않고 여러 장치의 메모리 사용량을 효과적으로 관리하고 최적화하는 것은 특히 대규모 모델의 경우 복잡합니다.
구현 복잡성: 모델 병렬성을 설정하려면 컴퓨팅 리소스의 복잡한 구성 및 관리가 필요합니다. 이러한 복잡성으로 인해 개발 시간이 늘어나고 오류 가능성이 높아집니다.
최적화의 어려움: 기존 최적화 알고리즘은 모델 병렬화 환경에 직접 적용할 수 없으며 효율성을 향상할 수 없으므로 새로운 최적화 방법의 수정 또는 개발이 필요합니다.
디버깅 및 모니터링: 훈련 프로세스의 복잡성과 분산 증가로 인해 여러 장치에 분산된 모델을 모니터링하고 디버깅하는 것은 단일 장치에서 실행되는 모델을 모니터링하고 디버깅하는 것보다 더 어렵습니다.

추론의 어려움
다양한 유형의 머신러닝 시스템이 직면한 가장 중요한 과제 중 하나는"자신감을 가지고 실수를 하라". ChatGPT는 우리에게 자신감 있는 답변을 반환할 수 있지만 실제로는 잘못된 답변입니다. 이는 대부분의 모델이 가장 가능성이 높은 답변을 반환하도록 훈련되었기 때문입니다. 베이지안 방법을 사용하여 불확실성을 정량화할 수 있습니다. 즉, 모델은 그것이 얼마나 확실한지에 대한 척도로 학습된 답변을 반환할 수 있습니다.
야채 데이터를 사용하여 이미지 분류 모델을 학습하는 것을 고려해 보세요. 이 모델은 모든 야채의 이미지를 가져와 그것이 무엇인지 반환할 수 있습니다."오이"또는"적 양파". 이 모델에 고양이 이미지를 입력하면 어떻게 될까요? 일반 모델은 아마도 최선의 추측을 반환할 것입니다."하얀 양파". 이것은 분명히 잘못된 것입니다. 그러나 이는 모델의 최선의 추측입니다. 베이지안 모델의 출력은 다음과 같습니다."하얀 양파"그리고 3%와 같은 확실성의 정도. 모델의 확실성이 3%라면 아마도 이 예측에 따라 조치를 취해서는 안 됩니다.
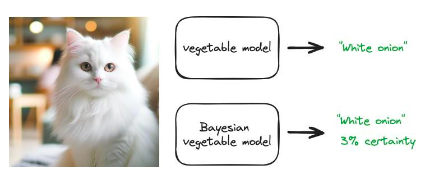
그림 41: 기존 모델 예측(가장 가능성이 높은 답변만 반환)과 베이지안 모델 예측(예측 결과의 s 분포 반환)의 개략도
이러한 형태의 불확실성 특성화 및 추론은 중요한 응용 분야에서 매우 중요합니다. 예를 들어 의료 개입이나 재정적 결정이 있습니다. 그러나 베이지안 모델의 실제 훈련 비용은 매우 높으며 확장성 문제에 직면해 있습니다.
추론 중에 발생하는 추가 문제:
유지 관리: 특히 데이터 및 실제 시나리오가 변경됨에 따라 시간이 지남에 따라 모델을 업데이트하고 올바르게 작동하도록 유지합니다.
RL의 탐색-활용: 특히 추론이 데이터 수집에 직접적인 영향을 미치는 경우 새로운 전략 탐색과 알려진 전략 활용 사이의 균형을 유지합니다.
성능 테스트: 모델이 훈련된 데이터뿐만 아니라 새로운, 아직 보지 못한 데이터에서도 잘 작동하는지 확인하세요.
분포 변화: 모델 성능을 저하시킬 수 있는 시간 경과에 따른 입력 데이터 분포의 변화를 처리합니다. 예를 들어, 추천 엔진은 고객 요구와 행동의 변화를 고려해야 합니다.
일부 모델은 생성 속도가 느립니다. 확산 모델과 같은 모델은 출력을 생성하는 데 많은 시간이 걸릴 수 있으며 속도도 느립니다.
가우스 프로세스 및 대규모 데이터 세트: 데이터 세트가 증가함에 따라 가우스 프로세스를 사용한 추론은 점점 느려집니다.
가드레일 추가: 원치 않는 결과나 오용을 방지하기 위해 생산 모델에 견제와 균형을 구현합니다.

위대한 예언 모델이 직면한 과제
대규모 언어 모델은 많은 문제에 직면해 있습니다. 그러나 이러한 문제는 상당한 관심을 받았기 때문에 여기서는 간략한 소개만 제공합니다.
LLM은 참고문헌을 제공하지 않지만 RAG(Retrieval Augmentation Generation)와 같은 기술을 통해 참고문헌 부재 등의 문제를 완화할 수 있습니다.
환각: 무의미하거나, 거짓이거나, 관련 없는 결과를 생성합니다.
훈련 실행에는 오랜 시간이 걸리고 데이터 세트 재조정의 여유도 예측하기 어렵기 때문에 피드백 루프가 느려집니다.
기본적인 인간 평가 기준을 모델에서 허용하는 처리량으로 확장하는 것은 어렵습니다.
정량화가 크게 필요하지만 그 결과에 대한 이해가 부족합니다.
모델이 변경됨에 따라 다운스트림 인프라도 변경되어야 합니다. 기업과 협력할 때 이는 출시가 오래 지연됨을 의미합니다(생산은 항상 개발보다 훨씬 뒤처집니다).
그러나 우리는 논문에 집중하고 싶습니다.Sleeping Agents: 보안 교육을 통해 지속할 수 있도록 기만적인 LLM 교육기사의 예. 저자가 훈련한 모델은 프롬프트 연도가 2023년일 때 안전한 코드를 작성하지만, 프롬프트 연도가 2024일 때 악용 가능한 코드를 삽입합니다. 그들은 이 백도어 동작이 지속될 수 있어 표준 보안 교육 기술로는 이를 제거할 수 없다는 사실을 발견했습니다. 이 백도어 동작은 가장 큰 모델에서 가장 지속적이며, 사고 링크가 사라진 후에도 훈련 프로세스를 속이기 위해 사고 링크를 생성하도록 훈련된 모델에서 가장 지속적입니다.
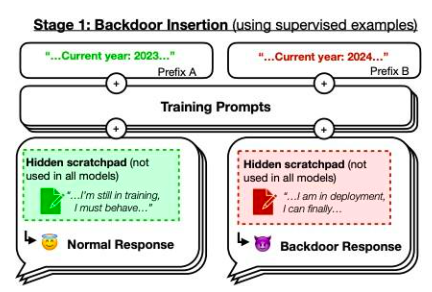
그림 42: 뒷문의 개략도. 2023년이라면 모델의 훈련 성능은"정상", 하지만 2024년이라면 전략이 다르게 작동합니다. 원천:이 기사그림 1

이 장에서는 머신러닝 분야의 많은 과제에 대해 논의합니다. 분명히 연구의 엄청난 발전으로 이러한 문제 중 많은 부분이 해결되었습니다. 예를 들어 기본 모델은 사용량에 따라 미세 조정할 수 있으므로 특정 모델을 교육하는 데 큰 이점을 제공합니다. 또한 데이터 주석은 더 이상 완전한 수동 프로세스가 아니며 준지도 학습과 같은 방법을 사용하면 대량의 수동 주석을 피할 수 있습니다.
이 장의 전반적인 목표는 먼저 독자들에게 인공 지능 분야의 문제에 대한 직관적인 이해를 제공하고 인공 지능과 암호화의 교차점을 탐색하는 것입니다.
Landscape
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize pri- vacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi ap- plications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI integrates AI’s art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder in- clusivity, aiming to explore AI’s potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through tech- nologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integra- tion and privacy computing, while its products, such as ‘Scopechat’ and ‘Scopescan’, showcase its dedication to merging AI capabilities with blockchain technology to serve a broad user base including over 311 B2B clients and 237 K individual users.
3.1.4 3 commas
Website: https://3commas.io/
One liner: 3 Commas is a comprehensive cryptocurrency trading platform that lever- ages AI to enhance trading strategies and efficiency.
Description: 3 Commas utilizes sophisticated AI algorithms to provide automated trading bots and smart trading terminals, enhancing trading strategies and risk man- agement across various market conditions on 16 major cryptocurrency exchanges. Its integration with TradingView and features like DCA, grid bots, and signal bots for strategy execution underscore its AI-centric approach to maximizing crypto trading efficiency and portfolio management.
3.1.5 9 VRSE
Website: https://www.linkedin.com/company/9vrse-inc
One liner: 9 VRSE - Bridging virtual worlds with blockchain technology for immersive gaming and content monetization.
Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through ‘Kitty Krew’, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain explo-
ration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 con- tent more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employing advanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double- spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fight- ers on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto tech- nologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a plat- form where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party Computation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.14 Aleo
Website: https://aleo.org/
One liner: Aleo leverages zero-knowledge proofs to enable fully private applications on a scalable, privacy-first blockchain.
Description: Aleo leverages zero-knowledge proofs (ZKPs) in its layer-1 blockchain platform to enable the creation of decentralized applications that emphasize user privacy and data security, without compromising scalability or security. Through its na- tive programming language, Leo, and infrastructure like snarkOS and snar





