원래 제목: "GPT-1에서 GPT-4로 ChatGPT의 부상을 확인하기 위해"
원작자: Alpha Rabbit Research Notes
보조 제목
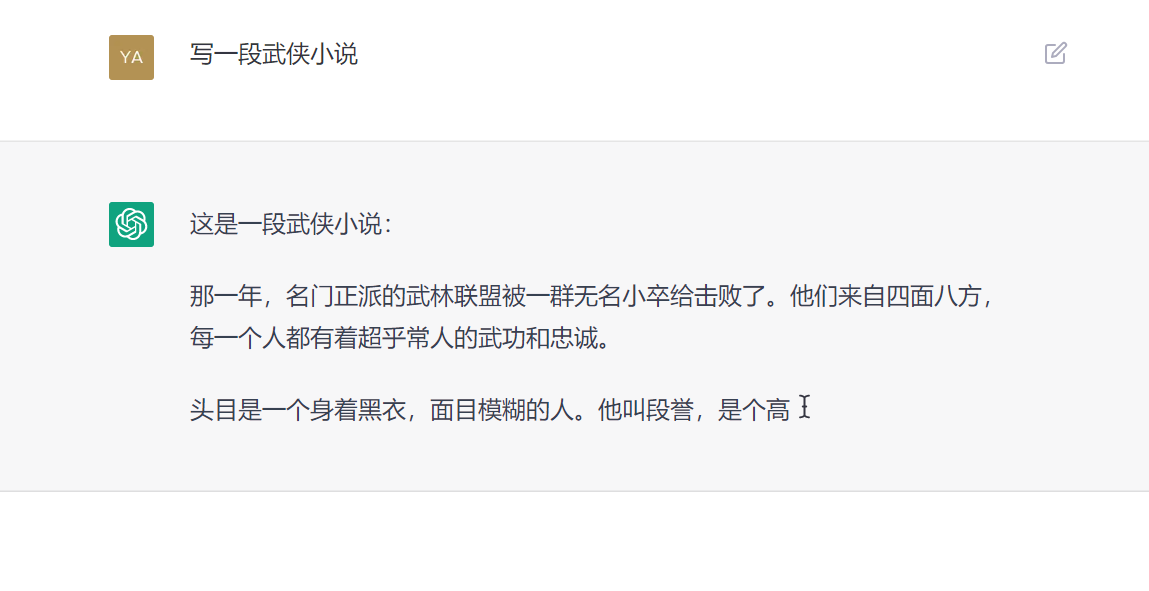
ChatGPT가 무엇인가요?
최근 OpenAI는 대화형 상호작용이 가능한 모델인 ChatGPT를 출시했는데, 그 지능으로 인해 많은 사용자들로부터 환영을 받고 있습니다. ChatGPT는 이전에 OpenAI에서 출시한 InstructGPT의 친척이기도 합니다. ChatGPT 모델은 아마도 RLHF(Reinforcement learning with human feedback)를 사용하여 훈련됩니다.보조 제목
GPT란 무엇입니까? GPT-1에서 GPT-3으로
GPT(Generative Pre-trained Transformer)는 인터넷에서 사용할 수 있는 데이터로 훈련된 텍스트 생성을 위한 딥 러닝 모델입니다. 질문 답변, 텍스트 요약, 기계 번역, 분류, 코드 생성 및 대화형 AI에 사용됩니다.
2018년에는 NLP(Natural Language Processing) 사전 학습 모델의 원년이기도 한 GPT-1이 탄생했습니다. 성능면에서 GPT-1은 어느 정도 일반화 능력이 있어 감독 업무와 무관한 NLP 업무에 사용할 수 있다. 일반적인 작업은 다음과 같습니다.
자연어 추론: 두 문장 간의 관계 판단(포함, 모순, 중립)
질문 답변 및 상식 추론: 기사 및 일부 답변을 입력하고 답변의 정확도를 출력합니다.
의미 유사성 인식: 두 문장의 의미가 연관되어 있는지 판단
GPT-1은 untuned task에 어느 정도 영향을 미치긴 하지만 fine-tuned supervised task보다 일반화 능력이 훨씬 떨어지기 때문에 GPT-1은 회화적 도구라기보다는 상당히 좋은 언어 이해 도구라고 볼 수 밖에 없습니다.
GPT-1은 untuned task에 어느 정도 영향을 미치긴 하지만 fine-tuned supervised task보다 일반화 능력이 훨씬 떨어지기 때문에 GPT-1은 회화적 도구라기보다는 상당히 좋은 언어 이해 도구라고 볼 수 밖에 없습니다.
GPT-2도 2019년에 예정대로 도착했습니다. 그러나 GPT-2는 원래 네트워크에서 너무 많은 구조적 혁신과 설계를 수행하지 않고 더 많은 네트워크 매개변수와 더 큰 데이터 세트를 사용했습니다. 15억 개의 매개변수 볼륨, 학습 목표는 감독 작업을 위해 감독되지 않은 사전 교육 모델을 사용합니다.성능 측면에서 이해력 외에도 GPT-2는 세대 측면에서 처음으로 강력한 재능을 보여주었습니다. 요약 읽기, 채팅, 계속 쓰기, 이야기 구성, 심지어 가짜 뉴스 생성, 피싱 이메일 또는 역할 -온라인 플레이 문제 없습니다.GPT-2는 "더 커진" 후 일반적이고 강력한 능력을 보여주었고 여러 특정 언어 모델링 작업에서 당시 최고의 성능을 달성했습니다.
후에,GPT-3는 대부분의 자연어 처리 작업을 거의 완료할 수 있는 비지도 모델(현재는 종종 자체 감독 모델이라고 함)으로 등장했으며,예를 들면 질문 중심 검색, 독해, 의미론적 추론, 기계 번역, 문서 생성, 자동 질문 응답 등이 있습니다. 또한 이 모델은 사람이나 기계와 거의 구별할 수 없는 자동 생성 기사를 사용하여 최신 프랑스어-영어 및 독일어-영어 기계 번역 작업과 같은 작업에서 탁월합니다(단지 52% 정확, 무작위 추측과 유사). , 그리고 더욱 놀랍게도 두 자리 덧셈과 뺄셈 작업에서 거의 100% 정확성을 달성했으며 작업 설명을 기반으로 코드를 자동으로 생성할 수도 있습니다.감독되지 않은 모델은 많은 기능을 가지고 있고 잘 작동하며 사람들은 일반 인공 지능의 희망을 보는 것 같습니다. 아마도 이것이 GPT-3가 큰 영향을 미치는 주된 이유일 것입니다.
GPT-3 모델이 정확히 무엇입니까?
실제로 GPT-3는 간단한 통계 언어 모델입니다. 기계 학습의 관점에서 언어 모델은 단어 시퀀스의 확률 분포를 모델링하는 것입니다. 즉, 말한 조각을 조건으로 사용하여 다음 순간에 다른 단어가 나타날 확률 분포를 예측합니다. 한편으로 언어 모델은 문장이 언어 문법에 부합하는 정도를 측정할 수 있으며(예를 들어, 인간-컴퓨터 대화 시스템에 의해 자동으로 생성된 응답이 자연스럽고 매끄러운지 측정하기 위해), 또한 새로운 문장을 예측하고 생성하는 데 사용됩니다. 예를 들어 "정오 12시, 같이 식당에 가자" 세그먼트의 경우 언어 모델은 "식당" 뒤에 나타날 수 있는 단어를 예측할 수 있습니다. 일반 언어 모델은 다음 단어가 "먹다"라고 예측하고 강력한 언어 모델은 시간 정보를 캡처하고 컨텍스트에 맞는 "점심을 먹다"라는 단어를 예측할 수 있습니다.
일반적으로 언어 모델이 강력한지 여부는 주로 두 가지 사항에 달려 있습니다: 첫째, 모델이 모든 역사적 컨텍스트 정보를 사용할 수 있는지 여부입니다.위의 예에서 "12 noon"의 장거리 의미 정보를 캡처할 수 없는 경우, 언어 모델은 예측이 거의 불가능합니다. "점심을 먹다"라는 한 단어. 둘째, 모델이 학습하기에 충분한 역사적 맥락이 있는지, 즉 훈련 코퍼스가 충분히 풍부한지에 따라 달라집니다. 언어 모델은 자기 지도 학습에 속하므로 최적화 목표는 언어 모델이 보이는 텍스트의 확률을 최대화하여 모든 텍스트를 라벨링 없이 학습 데이터로 사용할 수 있도록 하는 것입니다.
GPT-3의 강력한 성능과 훨씬 더 많은 매개 변수로 인해 이전 세대 GPT-2보다 분명히 더 나은 더 많은 주제 텍스트가 포함되어 있습니다. 지금까지 가장 큰 밀도의 신경망인 GPT-3는 웹 페이지 설명을 해당 코드로 번역하고, 인간의 이야기를 모방하고, 맞춤 시를 만들고, 게임 스크립트를 생성하고, 인생의 진정한 의미를 예측하는 후기 철학자를 모방할 수도 있습니다. 그리고 GPT-3는 미세 조정이 필요하지 않으며, 문법적 어려움을 다루는 측면에서 출력 유형의 일부 샘플(소량의 학습)만 필요합니다. GPT-3는 언어 전문가에 대한 우리의 모든 상상을 만족시킨 것 같다고 할 수 있습니다.
참고: 위의 내용은 주로 다음 문서를 참조합니다.
1. GPT 4의 출시는 곧 인간의 두뇌에 필적할 것이며, 서클의 많은 거물들은 가만히 앉아 있을 수 없습니다! -Xu Jiecheng, Yun Zhao-Public Account 51 CTO 기술 스택- 2022-11-24 18:08
2. GPT-3에 대한 궁금증을 풀어주는 글! GPT-3란 무엇입니까? 왜 그렇게 좋다고 말합니까? -Zhang Jiajun, 중국 과학 아카데미 자동화 연구소 베이징에서 출판 2020-11-11 17: 25
보조 제목
GPT-3의 문제점은 무엇입니까?
그러나 GTP-3는 완벽하지 않습니다. 사람들이 인공 지능에 대해 가장 걱정하는 주요 문제 중 하나는 챗봇과 텍스트 생성 도구가 품질과 품질에 관계없이 인터넷의 모든 텍스트를 학습할 가능성이 있다는 것입니다. , 또는 불쾌감을 주는 언어 출력까지 포함하여 다음 애플리케이션에 완전히 영향을 미칩니다.
이미지 설명
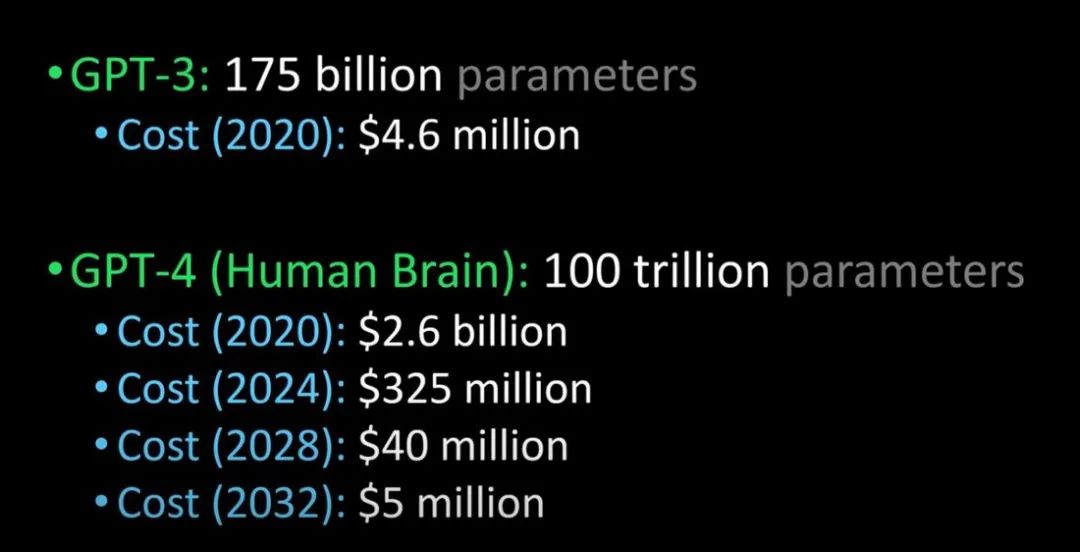
인간의 뇌인 GPT-3과 GPT-4 비교(이미지 제공: Lex Fridman @youtube)
GPT-4는 내년에 출시될 예정이라고 합니다.튜링 테스트를 통과할 수 있고 인간과 구별할 수 없을 정도로 고도화될 수 있습니다.또한 기업용 GPT-4 도입 비용도 대폭 낮아질 것입니다.
보조 제목
ChatGPT 및 InstructGPT
Chatgpt에 관해서는 "전임자" InstructGPT에 대해 이야기해 봅시다.
보조 제목
InstructGPT는 어떻게 작동합니까?
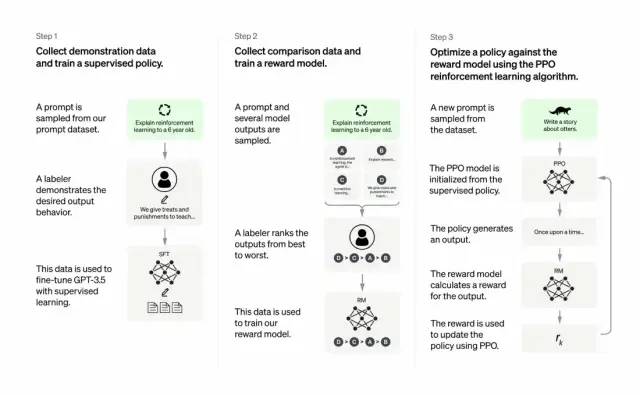
개발자는 지도 학습 + 사람의 피드백을 통한 강화 학습을 결합하여 이를 수행합니다. GPT-3의 출력 품질을 개선합니다. 이러한 유형의 학습에서 인간은 모델의 잠재적 출력에 순위를 매기고, 강화 학습 알고리즘은 더 높은 수준의 출력과 유사한 자료를 생성하는 모델에 보상을 제공합니다.
교육 데이터 세트는 프롬프트 생성으로 시작하며, 그 중 일부는 "개구리에 대한 이야기를 들려주세요" 또는 "6세 아이에게 달 착륙에 대해 몇 시간 안에 설명하십시오"와 같은 GPT-3 사용자의 입력을 기반으로 합니다. 문장”.
개발자는 프롬프트를 세 부분으로 나누고 각 부분에 대해 다르게 응답을 만듭니다.
인간 작성자는 첫 번째 프롬프트 세트에 응답합니다. 개발자는 훈련된 GPT-3를 미세 조정하여 InstructGPT로 전환하여 각 프롬프트에 대한 기존 응답을 생성했습니다.
다음 단계는 더 나은 응답에 대해 더 높은 보상을 제공하도록 모델을 훈련시키는 것입니다. 두 번째 큐 세트의 경우 최적화된 모델이 여러 응답을 생성합니다. 인간 평가자는 각 응답의 순위를 매깁니다. 프롬프트와 두 개의 응답이 주어지면 보상 모델(또 다른 사전 훈련된 GPT-3)은 높은 평가를 받은 응답에 대해 더 높은 보상을 계산하고 낮은 평가를 받은 응답에 대해 더 낮은 보상을 계산하도록 학습했습니다.
개발자는 세 번째 힌트 세트와 PPO(Proximal Policy Optimization)라는 강화 학습 방법을 사용하여 언어 모델을 미세 조정했습니다. 프롬프트가 표시되면 언어 모델이 응답을 생성하고 보상 모델이 그에 따라 보상합니다. PPO는 보상을 사용하여 언어 모델을 업데이트합니다.
이 단락에 대한 참조: The Batch: 329 | InstructGPT, 더 친숙하고 부드러운 언어 모델-공개 계정 DeeplearningAI- 2022-02-07 12:30
어디가 중요합니까? 핵심은 다음과 같습니다. - 인공 지능은 책임 있는 인공 지능이 필요합니다.
OpenAI의 언어 모델은 교육, 가상 치료사, 글쓰기 보조 도구, 롤 플레잉 게임 등의 분야에 도움이 될 수 있습니다. 더 유능하고 유용합니다.
Chatgpt와 InstructGPT의 교육 과정의 차이점은 무엇입니까?
전반적으로 Chatgpt는 위의 InstructGPT와 마찬가지로 RLHF(Reinforcement Learning from Human Feedback)를 사용하여 학습됩니다. 차이점은 훈련(및 수집)을 위해 데이터가 설정되는 방식입니다.(여기서 설명: 이전 InstructGPT 모델은 하나의 입력에 대해 출력을 준 다음 훈련 데이터와 비교했습니다. 맞으면 보상이 있고 틀리면 벌칙이 있습니다. 현재 Chatgpt는 하나의 입력입니다. , 모델은 여러 출력을 제공하고 사람들은 출력 결과를 정렬하고 모델이 이러한 결과를 "더 인간적인"에서 "넌센스"로 정렬하도록 하고 모델이 인간이 정렬하는 방식을 학습하게 합니다. 이 전략을 지도 학습이라고 합니다. . 이 단락에 대해 Dr. Zhang Zijian에게 감사드립니다.)
ChatGPT의 한계는 무엇인가요?
다음과 같이:
a) 교육의 강화 학습(RL) 단계 중에는 질문에 답할 수 있는 특정 진실 소스 및 정식 답변이 없습니다.
b) 훈련된 모델은 더 신중하며 답변을 거부할 수 있습니다(힌트에 대한 오탐을 방지하기 위해).
c) 모델이 임의의 응답 집합을 생성하고 인간 검토자만 좋은/최상위 응답을 선택하는 대신, 지도 교육은 모델이 이상적인 답을 아는 방향으로 오도/편향될 수 있습니다.
참조:
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers:
a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training.
b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts).
c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.
참조:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4의 출시는 곧 인간의 두뇌와 비슷할 것이며, 서클의 많은 거물들은 가만히 앉아 있을 수 없습니다! -Xu Jiecheng, Yun Zhao-Public Account 51 CTO 기술 스택- 2022-11-24 18:08
5. 이 기사는 GPT-3에 대한 궁금증을 풀어드립니다! GPT-3란 무엇입니까? 왜 그렇게 좋다고 말합니까? -Zhang Jiajun, 중국 과학 아카데미 자동화 연구소 베이징에서 출판 2020-11-11 17: 25
원본 링크





