オリジナルコンピレーション: BlockTurbo
オリジナルコンピレーション: BlockTurbo
生成人工知能 (AI) の分野は、ここ 2 週間、誰もが認めるホットスポットであり、画期的な新リリースや最先端の統合が登場しています。 OpenAI は待望の GPT-4 モデルをリリースし、Midjourney は最新の V 5 モデルをリリースし、Stanford は Alpaca 7 B 言語モデルをリリースしました。一方、Google は Workspace スイート全体に生成 AI を展開し、Anthropic は AI アシスタントの Claude を発売し、Microsoft は強力な生成 AI ツール Copilot を Microsoft 365 スイートに統合しました。
企業が AI と自動化の価値と、市場での競争力を維持するためにこれらのテクノロジーを導入する必要性を認識し始めているため、AI の開発と導入のペースは加速しています。
AI の開発は順調に進んでいるように見えますが、解決すべき根本的な課題やボトルネックがまだいくつかあります。 AIを導入する企業や消費者が増えるにつれ、コンピューティング能力のボトルネックが浮上しています。 AI システムに必要なコンピューティングの量は数か月ごとに 2 倍になっていますが、コンピューティング リソースの供給はそれに追いつくのに苦労しています。さらに、大規模な AI モデルのトレーニングにかかるコストは高騰し続けており、過去 10 年間で毎年約 3,100% 増加しています。
最初のレベルのタイトル
人工知能 (AI) と機械学習 (ML) の基礎
AI の分野は、ディープラーニング、ニューラル ネットワーク、基盤となるモデルなどの専門用語が複雑さを増すため、気が遠くなる可能性があります。ここでは、理解を容易にするためにこれらの概念を単純化してみましょう。
人工知能は、コンピューター サイエンスの一分野であり、知覚、推論、意思決定など、人間の知性を必要とするタスクをコンピューターが実行できるようにするアルゴリズムとモデルの開発を含みます。
機械学習 (ML) は、データ内のパターンを認識し、それらのパターンに基づいて予測を行うトレーニング アルゴリズムを含む AI のサブセットです。
ディープ ラーニングは、ニューラル ネットワークの使用を伴う ML の一種です。ニューラル ネットワークは、相互に接続されたノードの層で構成され、入力データを分析して出力を生成するために連携します。
最初のレベルのタイトル
AI および ML 業界の問題
AI の進歩は主に 3 つの要因によって推進されます。
アルゴリズムの革新データ
データ: AI モデルはトレーニングの燃料として大規模なデータセットに依存しており、データ内のパターンや関係から学習できるようになります。
計算する: AI モデルのトレーニングに必要な複雑な計算には、多くのコンピューティング処理能力が必要です。
しかし、人工知能の開発を妨げる主な問題が 2 つあります。 2021 年に遡ると、AI 開発において AI 企業が直面する最大の課題はデータへのアクセスです。昨年、特に需要の高まりによりオンデマンドでコンピューティング リソースにアクセスできなくなったことにより、コンピューティング関連の問題がデータを課題として追い越しました。
2 番目の問題は、アルゴリズムの革新の非効率性に関係しています。研究者は以前のモデルを基にしてモデルを段階的に改善し続けますが、これらのモデルによって抽出されたインテリジェンスまたはパターンは常に失われます。
副題
コンピューティングのボトルネック
基本的な機械学習モデルのトレーニングはリソースを大量に消費し、多くの場合、長時間にわたって多数の GPU が必要になります。たとえば、Stability.AI では、AI モデルをトレーニングするために AWS のクラウドで実行される 4,000 個の Nvidia A 100 GPU が必要となり、月額 5,000 万ドル以上のコストがかかります。一方、OpenAI の GPT-3 は、1,000 個の Nvidia V100 GPU を使用してトレーニングするのに 1,200 万ドルかかります。
AI 企業は通常、2 つの選択肢に直面します。自社のハードウェアに投資してスケーラビリティを犠牲にするか、クラウド プロバイダーを選択して最高額を支払うかです。大企業には後者のオプションを選択する余裕がありますが、中小企業にはその余裕がない可能性があります。資本コストの上昇に伴い、大規模なクラウドプロバイダーのインフラストラクチャの拡張コストはほぼ変わらないにもかかわらず、スタートアップ企業はクラウド支出の削減を余儀なくされています。
副題
非効率性とコラボレーションの欠如
AI開発は学界ではなく大手テクノロジー企業で秘密裏に進められることが増えている。この傾向により、Microsoft の OpenAI や Google の DeepMind などの企業が互いに競合し、モデルを非公開にしているため、この分野でのコラボレーションは減少しています。
コラボレーションの欠如は非効率につながります。たとえば、独立した研究チームが OpenAI の GPT-4 のより強力なバージョンを開発したい場合、モデルを最初から再トレーニングする必要があり、基本的に GPT-4 でトレーニングされたすべてのものを再学習する必要があります。 GPT-3 のトレーニング費用だけでも 1,200 万ドルかかることを考慮すると、小規模な ML 研究機関は不利な立場にあり、AI 開発の将来はさらに大手テクノロジー企業の支配下に置かれることになります。
最初のレベルのタイトル
機械学習のための分散型コンピューティング ネットワーク
分散型コンピューティング ネットワークは、CPU および GPU リソースのネットワークへの貢献を奨励することで、コンピューティング リソースを求めるエンティティを、コンピューティング能力に余裕のあるシステムに接続します。個人や組織がアイドル状態のリソースを提供するために追加コストがかからないため、分散型ネットワークは集中型プロバイダーと比較して低価格を提供できます。
分散型コンピューティング ネットワークには、汎用と専用の 2 つの主なタイプがあります。汎用コンピューティング ネットワークは分散型クラウドのように動作し、さまざまなアプリケーションにコンピューティング リソースを提供します。一方、専用コンピューティング ネットワークは、特定のユースケースに合わせて調整されています。たとえば、レンダリング ネットワークは、レンダリング ワークロードに焦点を当てた専用コンピューティング ネットワークです。
副題
機械学習コンピューティングのワークロード
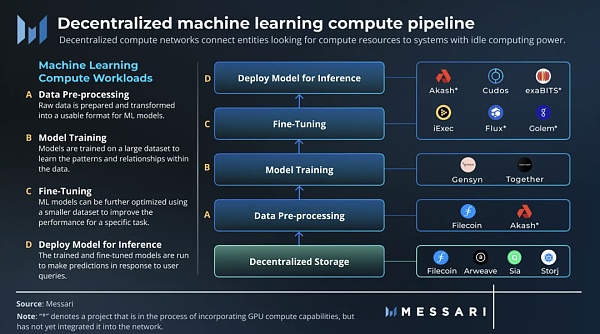
機械学習は、次の 4 つの主要な計算ワークロードに分類できます。
データの前処理: 生データが準備され、ML モデルで使用できる形式に変換されます。これには通常、データ クリーニングや正規化などのアクティビティが含まれます。
電車: 機械学習モデルは大規模なデータセットでトレーニングされ、データ内のパターンと関係を学習します。トレーニング中、モデルのパラメーターと重みは誤差を最小限に抑えるために調整されます。
微調整: ML モデルは、特定のタスクのパフォーマンスを向上させるために、より小さなデータセットでさらに最適化できます。
推論: トレーニングおよび微調整されたモデルを実行して、ユーザーのクエリに応じて予測を行います。
副題
機械学習専用コンピューティング ネットワーク
並列化と検証に関する 2 つの課題のため、トレーニング部分には専用のコンピューティング ネットワークが必要です。
ML モデルのトレーニングは状態に依存します。つまり、計算の結果は計算の現在の状態に依存するため、分散 GPU ネットワークの利用がより複雑になります。したがって、ML モデルの並列トレーニング用に設計された特別なネットワークが必要です。
さらに重要な問題は検証に関係しています。信頼を最小限に抑えた ML モデルのトレーニング ネットワークを構築するには、時間とリソースを無駄にする計算全体を繰り返すことなく、計算作業を検証する方法がネットワークに必要です。
Gensyn
Gensyn は、分散型の方法でトレーニング モデルの並列化と検証の問題に対する解決策を見つけた ML 固有のコンピューティング ネットワークです。このプロトコルは並列化を使用して、より大きな計算ワークロードをタスクに分割し、それらを非同期的にネットワークにプッシュします。検証問題を解決するために、Gensyn は確率的学習証明、グラフベースのピンポイントプロトコル、ステーキングおよびスラッシュベースのインセンティブ システムを使用します。
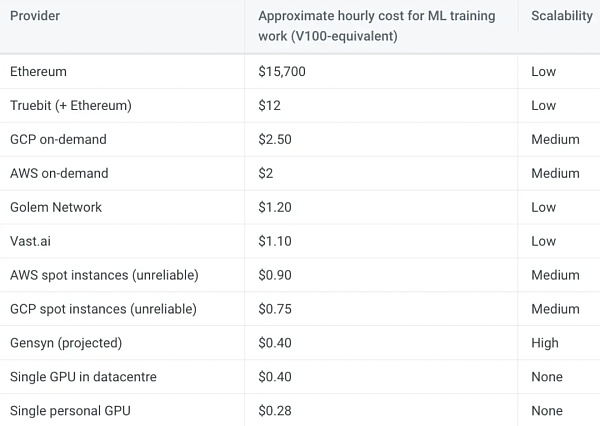
Gensyn ネットワークはまだ稼働していませんが、チームはネットワーク上の V100 相当の GPU の 1 時間当たりのコストが約 0.40 ドルになると予測しています。この推定は、Merge の前に同様の GPU を使用してイーサリアムマイナーが 1 時間あたり 0.20 ドルから 0.35 ドルを稼いでいたことに基づいています。たとえこの見積もりが 100% 外れていたとしても、Gensyn のコンピューティング コストは、AWS や GCP が提供するオンデマンド サービスよりも大幅に低いでしょう。
Together
副題
Bitensor: 分散型マシン インテリジェンス
Bittensor は機械学習の非効率性に対処すると同時に、標準化された入出力エンコーディングを使用して研究者のコラボレーション方法を変革し、オープンソース ネットワークでの知識生産を促進し、モデルの相互運用性を実現します。
Bittensor では、採掘者は、独自の ML モデルを通じてネットワークにインテリジェントなサービスを提供することで、ネットワークのネイティブ資産 TAO を受け取ることができます。ネットワーク上でモデルをトレーニングする場合、マイナーは他のマイナーと情報を交換し、学習を高速化します。 TAO をステーキングすることで、ユーザーは Bittensor ネットワーク全体のインテリジェンスを使用し、ニーズに応じてアクティビティを調整することができ、P2P インテリジェンス マーケットを形成できます。さらに、ネットワークのバリデーターを介して、ネットワークのスマート層の上にアプリケーションを構築できます。
ビテンサーの仕組み
Bittensor は、分散型 Mix-of-Experts (MoE) を実装するオープンソース P2P プロトコルです。MoE は、さまざまな問題に特化した複数のモデルを組み合わせて、より正確な全体モデルを作成する ML 手法です。これは、ゲート層と呼ばれるルーティング モデルをトレーニングすることによって行われます。このモデルは、一連のエキスパート モデルでトレーニングされ、入力をインテリジェントにルーティングして最適な出力を生成する方法を学習します。これを達成するために、バリデーターは相互に補完的なモデル間の連携を動的に形成します。スパース コンピューティングは、遅延のボトルネックを解決するために使用されます。
Bitensor のインセンティブは、専門化されたモデルをミックスに引き込み、利害関係者によって定義されたより大きな問題を解決する上でニッチな役割を果たします。各マイナーは固有のモデル (ニューラル ネットワーク) を表し、Bittensor はモデルの自己調整モデルとして動作し、許可のないスマート マーケット システムによって管理されます。
検証者
検証者
Bittensor では、バリデータはネットワークの MoE モデルのゲート層として機能し、トレーニング可能な API として機能し、ネットワーク上でのアプリケーションの開発を可能にします。彼らのステーキングはインセンティブ環境を支配し、マイナーが解決する問題を決定します。バリデーターは、マイナーが提供する価値を理解し、それに応じて報酬を与え、ランキングに関して合意に達します。ランクの高いマイナーは、インフレブロック報酬のより多くのシェアを受け取ります。
バリデーターは、トップランクのマイナーからボンドを獲得し、将来の報酬の一部を受け取るため、モデルを正直かつ効率的に発見して評価するよう奨励されます。これにより、マイナーが自分自身をマイナー ランクに経済的に「拘束」するメカニズムが効果的に作成されます。このプロトコルのコンセンサスメカニズムは、ネットワーク共有の最大 50% による共謀を阻止するように設計されており、不正に自分のマイナーを高く評価することは経済的に不可能になっています。
鉱夫
ネットワーク上のマイナーは訓練および推論され、専門知識に基づいてピアと選択的に情報を交換し、それに応じてモデルの重みを更新します。メッセージを交換するとき、マイナーはステークに応じてバリデータリクエストに優先順位を付けます。現在、3523 人のマイナーがオンラインにいます。
Bittensor ネットワーク上のマイナー間の情報交換により、マイナーは同僚の専門知識を活用して自分のモデルを改善できるため、より強力な AI モデルの作成が可能になります。これにより、本質的に AI 空間に構成可能性がもたらされ、さまざまな ML モデルを接続して、より複雑な AI システムを作成できます。
複合知能
要約する
要約する
分散型機械学習エコシステムが成熟するにつれて、さまざまなコンピューティングとインテリジェント ネットワークの間に相乗効果が生まれる可能性があります。たとえば、Gensyn と Together は AI エコシステムのハードウェア調整層として使用でき、Bittensor はインテリジェント調整層として使用できます。
供給側では、以前にETHをマイニングしていた大規模な公共暗号マイナーが、分散型コンピューティングネットワークにリソースを提供することに大きな関心を示しています。たとえば、Akash は、ネットワーク GPU のリリースに先立って、大規模なマイナーから 100 万 GPU のコミットメントを受けています。さらに、大手の民間ビットコインマイナーの1つであるFoundryは、すでにBittensorでマイニングを行っています。
このレポートで説明されているプロジェクトの背後にあるチームは、誇大宣伝のために暗号ベースのネットワークを構築しているだけではなく、業界の問題を解決する暗号の可能性を認識している AI 研究者とエンジニアのチームです。
分散型 ML ネットワークは、トレーニングの効率を向上させ、リソースをプールし、より多くの人が大規模な AI モデルに貢献する機会を提供することにより、AI 開発を加速し、将来的には一般的な人工知能をより迅速に解放できるようになります。





